







一、什么是熵
假设符号Xi的信息定义为:
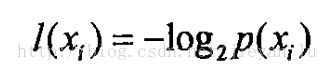
则熵定义为信息的期望值,为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,计算方式如下:
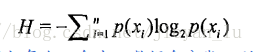
熵愈大,不稳定性愈高,即在决策树中一个样本可选择的分支会愈多。从公式来理解是:假如每个p(xi)愈少,则i值愈大,即信息量愈大,就是有可以有很多中分类。同时,H是关于p(xi)的减函数,
熵表示数据的混乱程度,假如每个p(xi)愈少,数据愈分散,则最后求出的嫡愈大,熵的本质是一个系统“内在的混乱程度”。所以,熵、不确定性、信息量,这三者是同一个数值。
二、构建树的理解
首先我认为要先理解怎样用一堆数据集训练出来一棵树。数据集中的数据包括特征值和类标签值。注意了这里的特征值是只有值,这些值要根据项目的背景归纳出来特征。这些特征就是训练决策树时要输入的标签。
然后,我个人理解创建决策树的过程就是判断哪个特征(就是上面所说的要输入的标签)是父节点,哪些特征是子节点,哪些特征是叶子节点。构建决策树的目的是把数据集合中的不同类型的数据划分得清清楚楚,即不同类型的数据必须分开。也就是说,只有决策树的分支愈多,把不同类型的数据分开的概率才能愈大。所以在创建树的过程中,会优先选择一些特征作为上层节点。这些特征的特点是:在根据这个特征划分数据集之后,数据子集的熵是最大的(熵愈大,不稳定性愈高,则在后续的节点中可以分出更多的类别)。
以下是计算熵和划分数据集的代码
#计算熵值
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts={}
for featVect in dataSet:
currentLabel = featVect[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob,2)
return shannonEnt
#分割数据子集合,返回筛选出某一特征之后的数据子集
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reduceFeatVec=featVec[:axis]
#这里获取的是取出了该特征之后的数据子集
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
#选择最好的划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures=len(dataSet[0])-1
baseEntropy=calcShannonEnt(dataSet)
bestInfoGain=0.0
bestFeature=-1
for i in range(numFeatures):
featList=[example[i] for example in dataSet]#特征中的属性值,这里要注意特征和属性之的关系
uniqueVals=set(featList)
#print uniqueVals
newEntropy=0.0
for value in uniqueVals:#计算熵的时候,不同的特征值分开计算
subDataSet=splitDataSet(dataSet,i,value)#根据每个特征的不同的属性值对数据进行划分
prob=len(subDataSet)/float(len(dataSet))
newEntropy+=prob*calcShannonEnt(subDataSet)#注意:这里是对子集求熵,子集的熵愈大,则愈有可能把树的结构变得愈长
infoGain=baseEntropy-newEntropy#
if infoGain>bestInfoGain:#
bestInfoGain=infoGain#
bestFeature=i
return bestFeature至此,把数据集划分完毕,接下来是进行构建树。工作原理是:对原始的数据集基于最好的特征(即根据该特征划分之后子集熵最大)进行划分数据集。在一次划分之后,数据将会被传到下一个节点,在这个节点上可以再次划分数据。每次递归都会在数据子集上选择一个最好的特征进行数据的分割,递归结束的条件是,所有程序遍历完所有的特征,或者是每个分支下所有的实例都具有相同的分类。
以下是创建树的代码:
#假如已经遍历了所有的特征,但是最终的分类标签仍然不是唯一的,则采用少数服从多数的原则决定这个标签
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0#zhege if yuju xiangdangyu yige chushihua tiaojian
classCount[vote]+=1
sortedClassCount=sorted(classCount.iteritems(),\
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):#判断是否每个分支下所有的实例都具有相同的类
return classList[0]
if len(dataSet[0])==1:#判断是否遍历完所有的特征
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet\
(dataSet,bestFeat,value),subLabels)#
return myTree测试分类器的代码如下:
#test
#featLabels就是上面所说的要输入的标签,而testVec就是属性值
def classify(inputTree,featLabels,testVec):
firstStr=inputTree.keys()[0]
secondDict=inputTree[firstStr]
featIndex=featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else:classLabel=secondDict[key]
return classLabel总结:一步一个脚印!















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









