






Tips
-
JVM常量池分为静态常量池和运行时常量池,因为Jdk1.7后字符串常量池从运行时常量池存储位置剥离,故很多博客也是区分开来,存储位置和内容注意区别!
-
字符串常量池底层是由C++实现,是一个类似于HashTable的数据结构,实质上存的是字符串对象的引用。HashTable跟Java中的HashMap的实现差不多,只是不能自动扩容。默认大小是1009。
-
Jdk1.6和1.7字符串常量池区别:
-
存储位置不同:
-
Jdk1.6及之前:运行时常量池(包含字符串常量池)在永久代;
-
Jdk1.7:有永久代,但已经逐步“去永久代”,字符串常量池移动到堆里,运行时常量池还在永久代;
-
Jdk1.8及之后: 无永久代,运行时常量池在元空间,字符串常量池里依然在堆里;
-
-
intern原理不同:
-
当字符串不在常量池中,Jdk1.6会单独在常量池中创建一个对象,而Jdk1.7直接将堆内存的对象引用放入到字符串常量池中;
-
-
jdk6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降。在jdk7中,StringTable的长度可以通过一个参数指定:-XX:StringTableSize=99991;
-
-
String s = new String("abc”) 创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在堆中的String对象。
-
有些在编译期就能确定的常量,会在类加载时加入JVM常量池(运行时常量池);而有些编译期确定不了,就不会加入常量池,如String c = "li" + new String("zhi");

注意:以下比较字符串==都是基于Jdk1.7,1.6其实很好分析,记住常量池在永久代,堆对象在堆区就行
// a引用常量池
String a = "lizhi”;
// b引用常量池,编译期就能确定
String b = "li" + "zhi”;
// 在常量池和堆里边各创建一个对象,最后c指向堆对象。
String c = new String("lizhi”);
// 实测:先创建常量池对象,然后堆String对象的value指向常量池字符串对象的char数组,这样虽然new String出的每个对象都不==,但value指向是一样!
// 可以从String的构造方法看出,新字符串是常量池字符串的一个copy
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
// 由于new String()创建的字符串不是常量或字面量,在编译期间无法确定,所以没法在编译期进行合并。d指向在堆区创建一个新的对象。
String d = "li" + new String("zhi");
// 在编译期对象b是符号引用,无法确定,所以c也没法在编译期合并,只能运行时在堆中创建li对象然后通过append拼接zhi,c指向堆中对象!
String a = "lizhi";
String b = "li";
String c = b + "zhi";
// 结果为false
System.out.println(a == c);
// 如果对象b是一个常量,在编译期会被解析成常量值的一个本地拷贝存储到常量池中
String a = "lizhi";
final String b = "li";
String c = b + "zhi";
// 结果为true
System.out.println(a == c);
// 非常经典的场景
// 第一行(共创建4个,省去2个中间对象),最终创建了2个对象:常量池对象“a”,和堆对象“aa”。
// 有intern:把已有对象”aa”加入常量池,hashtable存的是堆对象引用,所以s和s1指向同一个对象,故==;
// 无intern:很明显s指向常量池,而s1指向堆对象,不==;
String s1 = new String("a") + new String("a");
// s1.intern();
String s = "aa";
System.out.println(s == s1);
// 两个String对象用"+"拼接会被优化为StringBuffer的append拼接,然后toString方法,与new一样会直接在堆中创建对象。
// 共创建5个对象
String s3 = new String("a") + new String("b");一,常量池概述
JVM的常量池主要有以下几种:
-
class文件常量池(静态常量池)
-
运行时常量池
-
字符串常量池
-
包装类常量池
二,Class文件常量池
.java
文件在编译之后会生成
.class
文件,class文件需要严格遵循JVM规范才能被JVM正常加载,它是一个二进制字节流文件,里面包含了class文件常量池的内容。
2.1 查看Class文件内容
jdk提供了
javap
命令,用于对class文件进行反汇编,输出类相关信息。
用法: javap <options> <classes>
例如,我们可以编写一个简单的类,如下:
public class Student {
private final String name = "张三";
private final int entranceAge = 18;
private String evaluate = "优秀";
private int scores = 95;
private Integer level = 5;
public String getEvaluate() {
return evaluate;
}
public void setEvaluate(String evaluate) {
String tmp = "+";
this.evaluate = evaluate + tmp;
}
public int getScores() {
return scores;
}
public void setScores(int scores) {
final int base = 10;
System.out.println("base:" + base);
this.scores = scores + base;
}
public Integer getLevel() {
return level;
}
public void setLevel(Integer level) {
this.level = level;
}
}
对其进行编译和反汇编:
javac Student.java
javap -v Student.class
得到以下反汇编结果:
Classfile /home/work/sources/open_projects/lib-zc-crypto/src/test/java/Student.class
Last modified 2021-1-4; size 1299 bytes
MD5 checksum 06dfdad9da59e2a64d62061637380969
Compiled from "Student.java"
public class Student
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #19.#48 // java/lang/Object."<init>":()V
#2 = String #49 // 张三
#3 = Fieldref #18.#50 // Student.name:Ljava/lang/String;
#4 = Fieldref #18.#51 // Student.entranceAge:I
#5 = String #52 // 优秀
#6 = Fieldref #18.#53 // Student.evaluate:Ljava/lang/String;
#7 = Fieldref #18.#54 // Student.scores:I
#8 = Methodref #55.#56 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
#9 = Fieldref #18.#57 // Student.level:Ljava/lang/Integer;
#10 = String #58 // +
#11 = Class #59 // java/lang/StringBuilder
#12 = Methodref #11.#48 // java/lang/StringBuilder."<init>":()V
#13 = Methodref #11.#60 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
#14 = Methodref #11.#61 // java/lang/StringBuilder.toString:()Ljava/lang/String;
#15 = Fieldref #62.#63 // java/lang/System.out:Ljava/io/PrintStream;
#16 = String #64 // base:10
#17 = Methodref #65.#66 // java/io/PrintStream.println:(Ljava/lang/String;)V
…...
{
方法信息,此处省略...
}
SourceFile: "Student.java"
其中的
Constant pool
就是class文件常量池,使用
#
加数字标记每个“常量”。
2.2 class文件常量池内容
class文件常量池存放的是该class编译后即知的,在运行时将会用到的各个“常量”。注意这个常量不是编程中所说的
final
修饰的变量,而是
字面量
和
符号引用
,如下图所示:
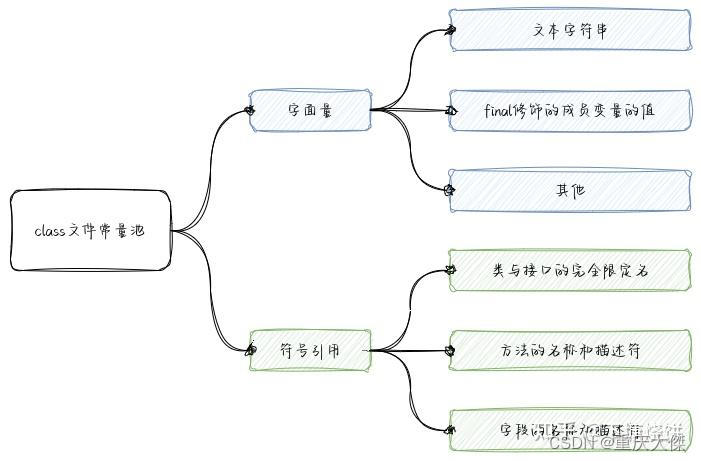
2.2.1 字面量
字面量相当于Java代码中的双引号字符串和常量的实际的值,包括:
1,文本字符串,即代码中用双引号包裹的字符串部分的值。例如刚刚的例子有三个字符串:
"张三"
,
"优秀"
,
"+"
,它们在class文件常量池中分别对应:
#49 = Utf8 张三
#52 = Utf8 优秀
#58 = Utf8 +这里的 #49 就是 "张三" 的字面量,它不是一个String对象,只是一个使用utf8编码的文本字符串而已。
2,用final修饰的成员变量,例如,
private static final int entranceAge = 18;
这条语句定义了一个final常量
entranceAge
,它的值是
18
,对应在class文件常量池中就有:
#25 = Integer 18注意,只有final修饰的成员变量如entranceAge,才会在常量池中存在对应的字面量。而非final的成员变量scores,以及局部变量base(即使使用final修饰了),它们的字面量都不会在常量池中定义。
2.2.2 符号引用
1,类和接口的全限定名,例如:
#11 = Class #59 // java/lang/StringBuilder
#59 = Utf8 java/lang/StringBuilder
2,方法的名称和描述符,例如:
#38 = Utf8 getScores
#39 = Utf8 ()I
#40 = Utf8 setScores
#41 = Utf8 (I)V
以及这种对其他类的方法的引用:
#8 = Methodref #55.#56 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
#55 = Class #69 // java/lang/Integer
#69 = Utf8 java/lang/Integer
#56 = NameAndType #70:#71 // valueOf:(I)Ljava/lang/Integer;
#70 = Utf8 valueOf
#71 = Utf8 (I)Ljava/lang/Integer;
3,字段的名称和描述符,例如:
#3 = Fieldref #18.#50 // Student.name:Ljava/lang/String;
#18 = Class #67 // Student
#67 = Utf8 Student
#50 = NameAndType #20:#21 // name:Ljava/lang/String;
#20 = Utf8 name
#21 = Utf8 Ljava/lang/String;三,运行时常量池
JVM在加载某个class的时候,需要完成以下任务:
1.通过class的全限定名来获取二进制字节流,即读取其字节码文件;2.将读入的字节流从静态存储结构转换为方法区中的运行时的数据结构;3.在Java堆中生成该class对应的类对象,代表该class原信息。这个类对象的类型是java.lang.Class,它与普通对象不同的地方在于,普通对象一般都是在new之后创建的,而类对象是在类加载的时候创建的,且是单例。
注意第二步就包含了将class文件常量池内容导入运行时常量池。class文件常量池是一个class文件对应一个常量池,而运行时常量池只有一个,多个class文件常量池中的相同字符串只会对应运行时常量池中的一个字符串。
运行时常量池除了导入class文件常量池的内容,还会保存符号引用对应的直接引用(实际内存地址)
。这些直接引用是JVM在类加载之后的连接(验证、准备、解析)阶段从符号引用翻译过来的。
四,字符串常量池
字符串常量池,是JVM用来维护字符串实例的一个引用表。在HotSpot虚拟机中,它被实现为一个全局的StringTable,底层是一个c++的hashtable。它将字符串的字面量作为key,实际堆中创建的String对象的引用作为value。
字符串常量池在逻辑上属于方法区,但JDK1.7开始,就被挪到了堆区。
String的字面量被导入JVM的运行时常量池时,并不会马上试图在字符串常量池加入对应的String对象,而是
等到程序实际运行时,要用到这个字面量对应的String对象时
,才会去字符串常量池试图获取或者加入String对象的引用。因此它是懒加载的。
4.1 new String()与String.intern()
通过2个例子,可以帮助我们加深对字符串常量池的理解。
// 语句1
String s1 = new String("asdf");
// 语句2
System.out.println(s1 == "asdf");
这个例子中假设
"asdf"
是首次被执行,那么语句1会创建两个String对象。一个是JVM拿字面量
"asdf"
去字符串常量池试图获取其对应String对象的引用,因为是首次执行,所以没找到,于是在常量池中创建了一个
"asdf"
的String对象,然后返回;返回之后,
JVM又在堆中创建了与
"asdf"
等值的另一个String对象。因此这条语句创建了两个String对象,它们值相等,都是
"asdf"
,但是引用(内存地址)不同,所以语句2返回false。
// 语句3
String s3 = new String("a") + new String("b");
// 语句4
s3.intern();
// 语句5
String s4 = "ab";
// 语句6
System.out.println(s3 == s4);
这个例子也假设相关字符串字面量都是首次被执行到,那么语句3会创建5个对象:两个”a",两个"b",一个”ab”(堆区)。
两个String对象用"+"拼接会被优化为StringBuffer的append拼接,然后toString方法,与new一样会直接在堆中创建对象。
语句4要注意,JDK1.6和JDK1.7开始,String.intern()的执行逻辑是不一样的。
-
JDK1.6会判断"ab"在字符串常量池中不存在,于是创建新的"ab"对象并将其引用保存到字符串常量池。
-
JDK1.7开始,判断"ab"在字符串常量池里不存在的话,会直接把 s3 的引用保存到字符串常量池。
因此对于语句6,如果是JDK1.6及以前的版本,结果就是false;而如果是JDK1.7开始的版本,结果就是true。
如果没有语句4,那么语句6结果一定是false。
4.2 字符串常量池是否会被GC
字符串常量池本身不会被GC,但其中保存的引用所指向的String对象们是可以被回收的。否则字符串常量池总是"只进不出",那么很可能会导致内存泄露。
在HotSpot的字符串常量池实现StringTable中,提供了相应的接口用于支持GC,不同的GC策略会在适当的时候调用它们。一般实在Full GC的时候,额外调用StringTable的对应接口做可达性分析,将不可达的String对象的引用从StringTable中移除掉并销毁其指向的String对象。
五,封装类常量池
除了字符串常量池,Java的基本类型的封装类大部分也都实现了常量池。包括
Byte、Short、Integer、Long、Character、Boolean
,注意浮点数据类型
Float、Double
是没有常量池的。
封装类的常量池是在各自内部类中实现的,比如
IntegerCache
(
Integer
的内部类),
自然也位于堆区
。
要注意的是,这些常量池是有范围的:
-
• Byte,Short,Integer,Long : [-128~127]
-
• Character : [0~127]
-
• Boolean : [True, False]















 3730
3730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









