






简单查询
Select 列 from 表 where 条件
- select后面如果接*就是查询所有列
- 给结果取一个别名 as 别名
- concat拼接字符串
- Distinct 去重
- %x% 查找含有某个字符
-- 查询先行课程不为空的课程。(使用*表示查询结果)
select *
from course
where cpno is not null;
-- 查询姓名中带有'n'字母的学生的学号,姓名(使用like语句)
select sno,sage
from students
where sname like '%n%';
-- 使用distinct关键字查询学生表中不同的系,列出系(去除重复元祖)
select distinct sdept
from students;
联表查询
-- 查询90分以上学生的选课信息,列出学号,姓名,课程号,成绩。
select A.sno,A.sname,B.cno
from students A,sc B
where grade>90 and A.sno=B.sno;
模糊查询
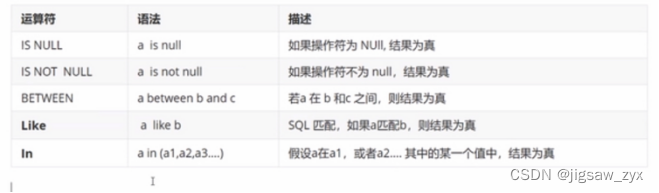
- Like 结合%(代表0到任意一个字符) 结合_代表一个字符
-- 查询姓名中带有'n'字母的学生的学号,姓名(使用like语句)
select sno,sage
from students
where sname like '%n%';
子查询
又称内层查询。
子查询
-- 查询没有选C06(课程号)课程的同学的学号,姓名,性别
select sno,sname,ssex
from students
where sno not in(
select sno
from sc
where cno='C06'
);
-- 查询成绩最高的选课信息,列出学号,课程号和成绩。
select sno,cno,grade
from sc
where grade in(
select max(grade)
from sc
);
-- 查询CS系没有选择'DB'课程学生的姓名,列出学生姓名。
select sname
from student
where sdept='CS' and sno not in(
select sno
from sc
where cno in(
select cno
from course
where cname='DB'
)
);
-- 查询‘DB’课程考最高分的选课信息。列出学号,课程号,成绩
select sno,cno,grade
from sc
where grade in(
select max(grade)
from sc
where cno in(
select cno
from course
where cname='DB'
)
);
-- 查询选修了先行课为'DB'的课程的学生,列出学生学号,姓名,性别,所在系
select sno,sname,ssex,sdept
from students
where sno in(
select sno
from sc
where cno in(
select cno
from course
where cpno in(
select cno
from course
where cno='DB'
)
)
)
子查询的增删改
-- 改:将'DB'课程不及格的成绩加5分。
update sc
set grade=grade+5
where grade<60 and cno in(
select cno
from course
where cname='DB'
);
-- 删:删除'English'(课程名)课程CS系学生的选课记录
delete
from sc
where cno in(
select cno
from course
where cname='English'
) and sno in(
select sno
from students
where sdept='CS'
);
-- 增:为CS系添加必修课'c02'。(即:为CS系没有选c02课程的学生选c02课程)
insert into sc(sno,cno)
select sno,'c02'
from students
where sdept='CS' and sno not in(
select sno
from sc
where cno='c02'
);
ALL表示查询结果的所有值,ANY表示查询中的某个值
聚合查询
即查询集合的数据。
1.As 更改结果列名。
聚合函数是针对一组数据进行操作。谈0到0聚合查询必然会涉及group by。
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
聚合函数和分组查询结合在一起,可以更方便灵活地进行数据查询。
SELECT COUNT(*) 新列名
FROM 表名
where 条件
GROUP BY 要分组的列名。
理解:从表中选出满足条件的所有数据,按照要求分组,然后对组进行数据查询。
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。

-- 查询‘001’号的学生不及格的课程数,列出不及格课程数(列名为:scnt)
select count(sno) as scnt
from sc
where cno='001' and grade<60
group by sno;
-- 查询每个系女同学的平均年龄,列出所在系和平均年龄(列名为:sageavg)
select sdept,avg(sage) as sageavg
from student
where ssex='f'
group by sdept;
聚合查询+带有IN的子查询
注意从里到外
-- 查询Niki(姓名)同学的平均分,列出平均分(列名为:savg)
select avg(grade) as savg
from sc
where sno in(
select sno
from student
where sname='NiKi'
)
-- 查询学分为2的每门课程的选课人数,列出课程号和选课人数(列名为:scnt)
select cno,count(cno) as scnt
from sc
where cno in(
select cno
from course
where ccredit=2
)
group by cno;
聚合查询+带有比较运算符的子查询
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having
条件过滤出特定的组,也可以使用多个分组标准进行分组。
-- 查询平均分最高的学生的姓名
select sname
from student
where sno in(
select sno
from sc
group by sno
having avg(grade)>=all(
select avg(grade)
from sc
group by sno
)
)
-- 查询不及格人数大于等于2人的课程,列出课程号,课程名,不及格人数(列名为scnt)
select sc.cno,cname,count(sno) as scnt
from sc,course
where group<60 and sc.cno=course.cno
group by sc.cno,cname
having count(sno)>=2;
-- ********** 此处写“1、查询E系平均成绩最高的同学的姓名,列出姓名”的SQL语句 ********** --
select sname
from student
where sdept='E' and sno in(-- 一定要注意这里还要加一个sdept='E'的判断,因为选择出来的最高平均成绩可能在其他系也存在
select sno
from sc
group by sno
having avg(grade)>=all(
select avg(grade)
from sc
where sno in(select sno from student where sdept='E')
group by sno
)
)















 2423
2423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









