







tf.train.ExponentialMovingAverage
- 作用:
Some training algorithms, such as GradientDescent and Momentum often benefit from maintaining a moving average of variables during optimization. Using the moving averages for evaluations often improve results significantly.
一些训练算法(如GradientDescent和Momentum)通常可以在优化过程中保持变量的移动平均值。 使用移动平均值进行评估通常会显着改善结果
- 什么是滑动平均:
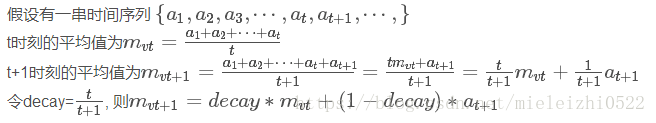
这种求平均值的好处是可以产生一个迭代效果,不必在求t+1时刻的值得时候还要保存a1,a2,a3…at的值,只保存一个之前时刻的平均值mvt就可以了,显然是衰减系数,如果t很大的时候decay接近于1,也就是0.999。
decay是衰减率。在创建ExponentialMovingAverage对象时,需要指定衰减率(decay),用于控制模型的更新速度。影子变量的初始值与训练变量的初始值相同。当运行变量更新时,每个影子变量都会更新为:
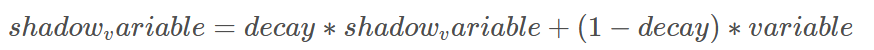
num_updates是ExponentialMovingAverage提供用来动态设置decay的参数,当初始化时,函数提供了num_updates参数,即不为none时,每次的衰减率是:
num_updates是ExponentialMovingAverage提供用来动态设置decay的参数,当初始化时,函数提供了num_updates参数,即不为none时,每次的衰减率是:

# 类,用于计算滑动平均
tf.train.ExponentialMovingAverage
__init__(
decay,
num_updates=None,
zero_debias=False,
name='ExponentialMovingAverage')
apply()方法添加了训练变量的影子副本,并保持了其影子副本中训练变量的移动平均值操作。在每次训练之后调用此操作,更新移动平均值。
average()和average_name()方法可以获取影子变量及其名称。
decay设置为接近1的值比较合理,通常为:0.999,0.9999等,decay越大模型越稳定,因为decay越大,参数更新的速度就越慢,趋于稳定。
官网中的示例:
# 创建variables.
var0 = tf.Variable(...)
var1 = tf.Variable(...)
# ... 使用variables去创建一个训练模型...
...
# 创建一个使用the optimizer对的op.
# 这是我们通常会使用作为一个training op.
opt_op = opt.minimize(my_loss, [var0, var1])
# 创建一个ExponentialMovingAverage object
ema = tf.train.ExponentialMovingAverage(decay=0.9999)
# 创建the shadow variables,然后把ops加到maintain moving averages of var0 and var1.
maintain_averages_op = ema.apply([var0, var1])
# 创建一个op,在每次训练之后用来更新the moving averages.
# 用来代替the usual training op.
with tf.control_dependencies([opt_op]):
training_op = tf.group(maintain_averages_op)
# run这个op获取当前时刻 ema_value
get_var0_average_op = ema.average(var0)
例子:
import tensorflow as tf
import numpy as np
v1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(tf.constant(0))
ema = tf.train.ExponentialMovingAverage(0.99, step)
maintain_average = ema.apply([v1])
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run([v1, ema.average(v1)])) #初始的值都为0
sess.run(tf.assign(v1, 5)) #把v1变为5
sess.run(maintain_average)
print(sess.run([v1, ema.average(v1)]))
# decay=min(0.99, 1/10)=0.1, v1=0.1*0+0.9*5=4.5
sess.run(tf.assign(step, 10000)) # steps=10000
sess.run(tf.assign(v1, 10)) # v1=10
sess.run(maintain_average)
print(sess.run([v1, ema.average(v1)]))
# decay=min(0.99,(1+10000)/(10+10000))=0.99, v1=0.99*4.5+0.01*10=4.555
sess.run(maintain_average)
print(sess.run([v1, ema.average(v1)]))
# decay=min(0.99,(1+10000)/(10+10000))=0.99, v1=0.99*4.555+0.01*10=4.60945
结果:
[0.0, 0.0]
[5.0, 4.5]
[10.0, 4.555]
[10.0, 4.60945]
——————
tf.train.ExponentialMovingAverage()函数解析(最清晰的解释)
tf.group()
tf.group()用于创造一个操作,可以将传入参数的所有操作进行分组。API手册如:
tf.group(
*inputs,
**kwargs
)
ops = tf.group(tensor1, tensor2,…)
其中*inputs是0个或者多个用于组合tensor,一旦ops完成了,那么传入的tensor1,tensor2,…等等都会完成了,经常用于组合一些训练节点,如在Cycle GAN中的多个训练节点,例子如:
generator_train_op = tf.train.AdamOptimizer(g_loss, ...)
discriminator_train_op = tf.train.AdamOptimizer(d_loss,...)
train_ops = tf.groups(generator_train_op ,discriminator_train_op)
with tf.Session() as sess:
sess.run(train_ops)
# 一旦运行了train_ops,那么里面的generator_train_op和discriminator_train_op都将被调用
注意的是,tf.group()返回的是个操作,而不是值,如果你想下面一样用,返回的将不是值
a = tf.Variable([5])
b = tf.Variable([6])
c = a+b
d = a*b
e = a/b
ops = tf.group(c,d,e)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
ee = sess.run(ops)
返回的将不是c,d,e的运算结果,而是一个None,就是因为这个是一个操作,而不是一个张量。如果需要返回结果,请参考tf.tuple()














 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









