







列表基础(sequence)
一序列
序列是Python中最基本的一种数据结构。
序列用于保存一组有序的数据,所有的数据在序列当中都有一个唯一的位置(即索引)并且序列中的数据会按照添加的顺序来分配索引。
数据结构指计算机中数据存储的方式。
例如:有一个字符串为‘abcd’,在计算机存储时,字符串是以序列的方式进行存储的。除了有特定的id、类型type以及值value之外;这个字符串里面的每个字母都有对应的索引值。
如下图所示,字符串‘abcd’,其中每个字母分别对应一个索引值,如果是从左往右(正序),abcd分别对应0、1、2、3的索引值。若从右往左(逆序),abcd则分别对应-1、-2、-3、-4这些索引值,也就是有一个位置。
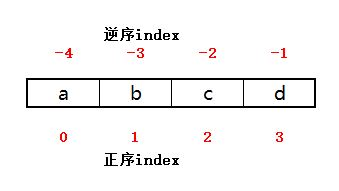
也就是说,字符串是以一定顺序的序列进行存储的,并有固定的索引值,这就是字符串可以通过索引值来截取的原因。
(二)序列的分类
可变序列(序列中的元素可以改变):例如 列表(list)
不可变序列(序列中的元素不能改变):例如 字符串(str)和元组(tuple)
例如·:以下列表1,这个列表的每个元素都可以进行增删改查的操作。(下面会说到这些基本操作)
-list1=[1,2,3,4,5,[a,b]]
而对于字符串来说,里面的元素不能进行增加或者删除这些操作,除非是通过字符串的截取方式来重新获取一个变量。
列表的格式
[数据1,数据2,数据3,…]
列表的使用
列表推导式
- 利用for循环创建列表
li = list()
for i in range(5):
li.append(i)
print(li)
输出;[0,1,2,3,4]
- 列表推导式
li = [b for b in range(5)]
print(li)
输出:[0,1,2,3,4]
创建列表
- 列表是由一系列特定顺序排序的元素组成,在python中,列表用方括号[ ]表示,并用逗号分隔其中的元素。
i = ['栗子','核桃','花生']
print(i)
# 输出:['栗子','核桃','花生']
访问列表
- 在python中,第一个列表元素的索引为0,而不是1。
i = ['栗子', '核桃', '花生']
print(i[1])
# 输出 : 核桃
- 访问最后一个列表元素通过将索引指定为-1,可返回最后一个列表元素。
i = ['栗子', '核桃', '花生']
print(i[-1])
# 输出 : 花生
列表的增,删,改,查
修改元素
i = ['栗子', '核桃', '花生']
i[-1] = '我原来是花生-现在是花生米'
print(i[-1])
### 输出:我原来是花生-现在是花生米
添加元素
- append() 方法用于在列表末尾添加新的对象。
i = ['栗子', '核桃', '花生']
i.append('碧根果')
print(i)
# 输出:['栗子', '核桃', '花生', '碧根果']
在列表中插入元素
- insert() 函数用于将指定对象插入列表的指定位置。该方法没有返回值,但会在列表指定位置插入对象。
语法 :insert()方法语法:
list.insert(index, obj)
参数 index -- 对象 obj 需要插入的索引位置。
obj -- 要插入列表中的对象。
i = ['栗子', '核桃', '花生']
i.insert(1, '我是插入的碧根果')
print(i)
# 输出: ['栗子', '我是插入的碧根果', '核桃', '花生']
拼接列表
- (+)号可以将两个列表拼接成一个列表
i = ['栗子', '核桃', '花生']
n = ['酸奶', '早餐奶', '安慕希']
ni = n + i
print(ni)
# 输出: ['酸奶', '早餐奶', '安慕希', '栗子', '核桃', '花生']
- (*)号可以将列表重复指定的次数 (注意2个列表不能够做乘法,要和整数做乘法运算)
i = ['栗子', '核桃', '花生']
n = i * 2
print(n)
# 输出:['栗子', '核桃', '花生', '栗子', '核桃', '花生']
del删除元素
- del可删除任意位置的列表元素,但你必须知道要删除的值的索引
i = ['栗子', '核桃', '花生']
del i[1]
print(i)
# 输出: ['栗子', '花生']
pop()删除元素
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
i = ['栗子', '核桃', '花生']
n = i.pop(-1)
print(n)
# 输出: 花生 (被删除的返回值)
remove() 方法用于移除集合中的指定元素。
- 该方法不同于 discard() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
- 没有返回值。
- remove()只删除第一个指定的值
i = ['栗子', '核桃', '花生', '核桃']
i.remove('核桃')
print(i)
输出: ['栗子', '花生']
copy()方法 拷贝
- 拷贝以后删除原来的列表不受影响,拷贝以后是一个独立的列表ID都不一样
i = ['栗子', '核桃', '花生']
a = i.copy()
print(i)
print(a)
# 输出:
8372 -- d:\python\python\ceshi.py "
['栗子', '核桃', '花生']
['栗子', '核桃', '花生']
Python index() 方法检测字符串中是否包含子字符串 str
- 如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
- str.index(str, beg=0, end=len(string))
- str – 指定检索的字符串
- beg – 开始索引,默认为0。
- end – 结束索引,默认为字符串的长度。
- 如果包含子字符串返回开始的索引值,否则抛出异常。
str1 = "this is string example....wow!!!"
str2 = "exam"
print(str1.index(str2))
print(str1.index(str2, 10))
print(str1.index(str2, 10, 32))
print(str1.index('fe', 10, 32))
lens = len(str1)
print(lens)
print(str1.index('fe', 10, 32)) # 找不到汇报错
排序
Python List sort()方法
- sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
-
- 语法:
list.sort(cmp=None, key=None, reverse=False)
- 参数:
- cmp – 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。
- 返回值
- 该方法没有返回值,但是会对列表的对象进行排序。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
aList = ['123', 'Google', 'Runoob', 'Taobao', 'Facebook']
aList.sort()
print("List : ")
print(aList)
aList.sort(reverse=True) # 降序排列
print(aList)
# 输出:
# ['123', 'Facebook', 'Google', 'Runoob', 'Taobao']
# ['Taobao', 'Runoob', 'Google', 'Facebook', '123']
Python sorted() 函数
- sorted() 函数对所有可迭代的对象进行排序操作。
- sort 与 sorted 区别:
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
- list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted 语法:
sorted(iterable, cmp=None, key=None, reverse=False)
- 参数说明:
- iterable – 可迭代对象。
- cmp – 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
- 返回值
- 返回重新排序的列表。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a = [5,7,6,3,4,1,2]
b = sorted(a) # 保留元列表
print(a)
print(b)
# 输出:
[5, 7, 6, 3, 4, 1, 2]
[1, 2, 3, 4, 5, 6, 7]
Python List reverse()方法
- reverse() 函数用于反向列表中元素。
– 该方法没有返回值,但是会对列表的元素进行反向排序。 - reverse()方法语法:
list.reverse()
#!/usr/bin/python
aList = [123, 'xyz', 'zara', 'abc', 'xyz']
aList.reverse()
print("List :", aList)
输出: List : ['xyz', 'abc', 'zara', 'xyz', 123]
Python List len()方法
- len() 方法返回列表元素个数。
- 语法:len(list) list – 要计算元素个数的列表。
- 返回列表元素个数。
#!/usr/bin/python
list1, list2 = [123, 'xyz', 'zara'], [456, 'abc']
print("First list length : ", len(list1))
print("Second list length : ", len(list2))
# 输出:
First list length : 3
Second list length : 2
Python count()方法
- Python count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
- count()方法语法:
str.count(sub, start= 0,end=len(string))
- 参数
- sub – 搜索的子字符串
- art – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
- 该方法返回子字符串在字符串中出现的次数。
#!/usr/bin/python
str = "this is string example....wow!!!"
sub = "i"
print("str.count(sub, 4, 40) : ", str.count(sub, 4, 40))
sub = "wow"
print("str.count(sub) : ", str.count(sub))
输出:
str.count(sub, 4, 40) : 2
str.count(sub) : 1
列表切片
• 语法: 列表[起始 : 结束 : 步长]
• 如果开始位置和结束位置都省略, 则则会从第一个元素开始截取到最后一个元素
• 步长表示每次获取元素的间隔,默认是1(可以省略不写)
• 步长不能是0,但可以是是负数
list1 = ['Google', 'Runoob', 'Taobao', '126']
print(list1[2]) # 读取列表中第三个元素
print(list1[-1]) # 读取列表中倒数第一个元素
print(list1[0:2:1]) # 从第0个元素开始到第三个(布长1)截取列表
print(list1[::2])
# 输出:
Taobao
126
['Google', 'Runoob']
['Google', 'Taobao']
in用来检查指定元素在列表当中
li = ['bmw', 'audi', 'toyota', 'subaru']
print('bmw' in li)
输出:True
not in 用来检查指定元素是否不在列表当中
li = ['bmw', 'audi', 'toyota', 'subaru']
print('bmw' not in li)
输出:Flase
小实验
a = [1,2,3,4,5,6] 用多种方式实现列表的反转([6,5,4,3,2,1])
- 排序并进行反转
a = [1, 2, 3, 4, 5, 6]
a.sort(reverse=True)
print(a)
- 直接反转列表
a = [1, 2, 3, 4, 5, 6]
a.reverse()
print(a)
- 逆序切片
a = [1, 2, 3, 4, 5, 6]
a = a[:: -1]
print(a)
- 创建一个空列表,遍历列表a中的元素插入到b列表的第一位
a = [1, 2, 3, 4, 5, 6]
b = []
for i in a:
b.insert(0, i)
print(b)
a = b
print(a)
猜数字游戏
- 给用户9次机会 猜1 - 10 个数字随机来猜数字。如果随机的数字和用户输入的数字一致则表示正确,如果不一致则表示错误。最终结果要求用户怎么也猜不对
import random
b = 0
while b < 9: # 用户有9次机会
a = int(input('请输入1-10其中一个数字')) # 用户输入数字
c = random.randint(1, 10) # 电脑随机数字
while a == c: # 用户和电脑进行判断 猜对电脑重新进行随机
c = random.randint(1, 10) # 电脑重新随机数字
continue # 重新进行循环判断
else: # 直到不相等
print('随机数字{0},你猜错了,还有{1}次机会'.format(c, 8 - b))
b += 1 # 用户次数加1
获取内容相同的连个列表的元素
lst1 = [11, 22, 33]
lst2 = [22, 33, 44]
for i in lst1:
if i in lst2:
print(i)
现在有8位老师,3个办公室,要求将8位老师随机的分配到三个办公室中
```c
import random
teachers = ['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg', 'hh']
offices = [[], [], []]
for name in teachers:
num = random.randint(0, 2)
offices[num].append(name)
i = 1
for office in offices:
print(f'办公室{i}的人数是{len(office)}.老师分别是:', end='')
i += 1
for name in office:
print(name, end='...')
print('')
# 输出:每次都不一样-可能会有的教室没有老师的情况
办公室1的人数是1.老师分别是:hh...
办公室1的人数是3.老师分别是:bb...ee...gg...
办公室1的人数是4.老师分别是:aa...cc...dd...ff...
输入姓名如果列表中存在则提示用户重新输入
name_list = ['Tom', 'lily', 'Rose']
name = input('请输入您的名字:')
while True:
if name in name_list:
print(f'您输入的名字是{name}, 名字已经存在,请重新输入')
name = input('请输入您的名字:')
else:
print(f'您输入的名字是{name}, 可以使用')
break
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











