






文章目录
前言
昨天和朋友聊天,她买的股票都吃到了大肉,我买的一直半死不活。她喜欢短线交易,我喜欢价值投资。但是A股总会教育我,后来我也在想这是为什么?市场永远是对的,他跟我说她选票的逻辑是,今年天气炎热,每到第三个季度就会是用电高峰,抓住机会就能吃到肉,这让我有了分析趋势,分析板块的想法。在股票投资中,选择正确的板块和抓住市场趋势是获得投资回报的重要因素。下面我将分享一下我对于分析趋势和选择板块的方法和心得。
首先,对于分析趋势,我会从以下几个角度入手:
宏观经济因素:了解宏观经济的整体走势对于判断市场趋势至关重要。例如,关注GDP增长率、通货膨胀率、利率等指标,以及政府的经济政策。这些因素能够影响不同行业和板块的表现,从而帮助我们把握市场趋势。
技术指标分析:技术指标可以辅助我们判断股票价格的走势和买卖时机。常用的技术指标包括移动平均线、相对强弱指数、MACD等。通过观察这些指标的变化,我们可以发现股票价格的趋势和市场情绪的变化。
市场情绪和资金流向:市场情绪和资金流向也是判断趋势的重要参考因素。观察市场的热点和主题,了解资金的流向和机构投资者的操作,可以帮助我们判断市场的走势和板块的表现。
其次,选择板块也是至关重要的。以下是我选择板块的一些建议和心得:
行业前景:选择具有良好发展前景的行业是优先考虑的。例如,新能源、互联网科技、医疗保健等行业在当前市场表现较好,并且有望长期受益于社会发展趋势。
个股分析:对于选择板块中的个股,我们需要进行更加精细的分析。研究公司的基本面,包括财务状况、盈利能力、行业地位、竞争优势等。同时,关注公司的管理层和治理结构,以及公司未来的发展计划和创新能力。
长期投资视角:即使是选择板块,也要有长期投资的视角。我们应该选择那些具备长期成长潜力和竞争优势的板块和个股,而不是追逐短期的热点。长期投资更能够抵御市场波动,获得可持续的回报。
一、python代码
1.准备条件
查询dqnapi接口域名:http://www.dqnapi.com/

pro.stock_basic dqnapi号:100.3568/2023.1_v1
pro.hsgt_top10 dqnapi号:100.3568/2023.23_v1
二、代码
import tushare as ts
import pandas as pd
from time import sleep
# 获取 Tushare 账户 TOKEN
pro = ts.pro_api(token='5f49af63e213438df4f2566786d51ce8e7581b70cd5a4a6ac8bc8189')
# 获取股票列表
stock_list = pro.stock_basic(exchange='', list_status='L', fields='ts_code,industry')
# 设置分析时间段
start_date = '2017-01-01' # 修改开始日期
end_date = '2022-12-31' # 修改结束日期
# 获取时间段内每个季度的起始日期
quarters = pd.date_range(start=start_date, end=end_date, freq='Q')
df_top10_list = []
count = 0 # 计数器,记录已经访问接口的次数
for quarter_start in quarters:
quarter_end = quarter_start + pd.offsets.QuarterEnd()
# 获取每个季度的起始日期和结束日期
start_date = quarter_start.strftime('%Y-%m-%d')
end_date = quarter_end.strftime('%Y-%m-%d')
# 获取时间段内每日前十大成交数据,并按照行业汇总
df_top10_list_quarter = []
for trade_date in pd.date_range(start=start_date, end=end_date):
count += 1
print(count)
if count >= 200:
sleep(60)
count = 0
trade_date_str = trade_date.strftime('%Y%m%d')
df_top10 = pro.hsgt_top10(trade_date=trade_date_str)
df_top10_merged = pd.merge(df_top10, stock_list, on='ts_code', how='left')
df_top10_grouped = df_top10_merged.groupby('industry').size().reset_index(name='counts')
df_top10_grouped['pct'] = df_top10_grouped['counts'] / len(df_top10_merged)
df_top10_list_quarter.append(df_top10_grouped)
# 将行业汇总数据合并,并计算每个行业的得分
df_top10_total_quarter = pd.concat(df_top10_list_quarter).groupby('industry').agg({'counts': 'sum', 'pct': 'mean'}).reset_index()
df_top10_total_quarter['score'] = df_top10_total_quarter['counts'] * df_top10_total_quarter['pct']
# 按照得分从高到低排序,并输出结果
df_top10_total_quarter = df_top10_total_quarter.sort_values(by='score', ascending=False)
df_top10_list.append(df_top10_total_quarter)
# 输出每个季度的热门板块
for i, quarter_start in enumerate(quarters):
quarter_end = quarter_start + pd.offsets.QuarterEnd()
print(f"第{i+1}季度 {quarter_start.strftime('%Y-%m-%d')} 至 {quarter_end.strftime('%Y-%m-%d')} 的热门板块:\n")
print(df_top10_list[i][['industry', 'counts', 'pct', 'score']])
print("\n")
with open('top.txt', 'w') as f:
for i, quarter_start in enumerate(quarters):
quarter_end = quarter_start + pd.offsets.QuarterEnd()
f.write(f"第{i+1}季度 {quarter_start.strftime('%Y-%m-%d')} 至 {quarter_end.strftime('%Y-%m-%d')} 的热门板块:\n\n")
f.write(df_top10_list[i][['industry', 'counts', 'pct', 'score']].to_string(index=False))
f.write("\n\n")
总结
提示:这里对文章进行总结:
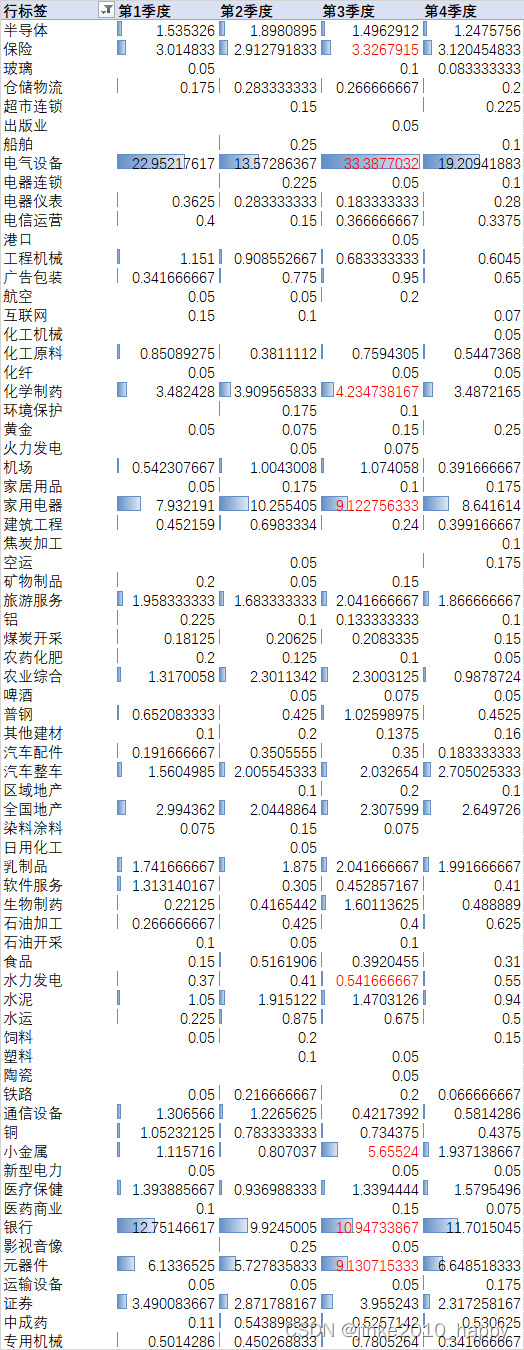
上表是2017年-2023年的数据整理,分析每个季度,不同行业板块热度是否存在差异。现在是第三季度,从结果看可以多关注下面这些板块

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









