






Spark集群要与Hadoop集群一样的部署方案,需要在Hadoop的master机上先把Spark相关的进行设置,然后把master机上的Spark环境复制到worker机。
同时也是使用hadoop用户去操作Spark,这一点非常重要。
想要完成以上操作,需要对Spark的目录结构有所了解
Spark根目录下的conf 里存放的配置文件,比较重要的,而且需要自行修改的是spark-env.sh.template,slaves.template ,尽量不要在原始模板上直接进行修改,最好是copy出一份来,去掉template后缀,这样就是我们要的文件了。
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
然后对spark-env.sh和slaves进行修改
1.在master节点 的spark-env.sh中增加
export SPARK_DIST_CLASSPATH=$(/usr/hadoop/hadoop-3.3.0/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-3.3.0/etc/hadoop
export SPARK_MASTER_IP=192.168.79.130


2.在slaves文件中增加worker节点 slave1 ,slave2


3.把master节点的解压后的spark文件夹复制到slave1,slave2
这里使用root用户来完成,普通用户权限不足
scp -r spark root@slave1:/usr/spark/
scp -r spark root@slave2:/usr/spark/
然后再到slave1,slave2对应机器上去改变所属用户组和权限组
chown -R jinxing:root spark/
配置环境变量
vi /etc/profile
#SPARK Environment
export SPARK_HOME=/usr/spark/spark-3.0.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile 使设置生效
启动Spark集群
1.启动Hadoop集群
启动前可以执行以下jps指令,查看当前hadoop是否已启动
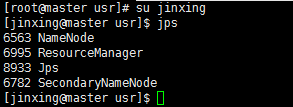
如果没有启动则执行以下指令
![]()
2.在master节点上启动Spark
![]()
3.启动slave节点

解决这个问题需要在/usr/spark/spark-3.0.3-bin-hadoop2.7/sbin/spark-config.sh最后添加export JAVA_HOME=/usr/java/jdk1.8.0_141

保存后,
然后停止主节点, ./stop-master.sh
启动主节点, ./start-master.sh
启动slave ./start-slaves.sh

4.查看集群信息

关闭Spark集群
./stop-master.sh
./stop-slaves.sh















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









