






1.官网地址
Set up Elasticsearch | Elasticsearch Guide [7.17] | Elastic
2.下载
进入/usr/local/software/tars 目录下执行以下指令,必须使用普通用户完成,后面启动不允许使用root用户,这里我们使用之前创建的hadoop用户即可
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.10-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.10-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-7.17.10-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-7.17.10-linux-x86_64.tar.gz
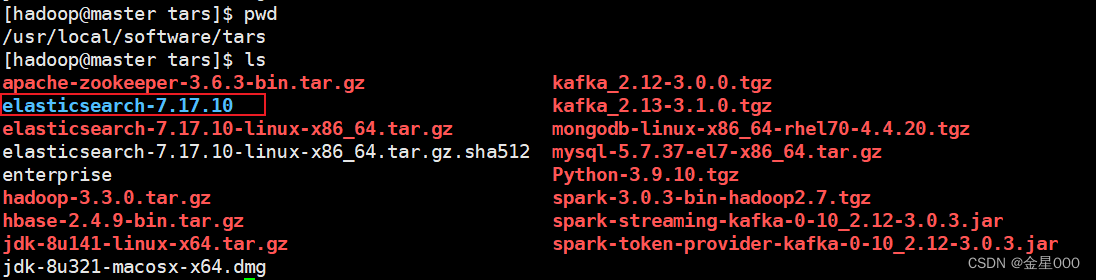
3.安装
把elasticsearch-7.17.10移动到上级目录
mv elasticsearch-7.17.10 ../其他节点的集群也执行1,2,3的操作即可
4.配置
系统配置
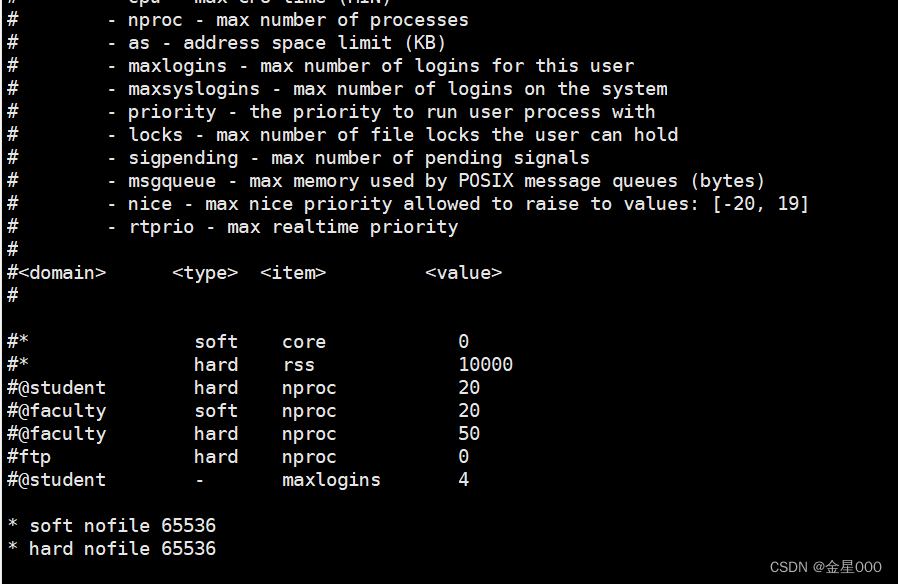
配置/etc/security/limits.conf文件,在底部添加
* soft nofile 65536
* hard nofile 65536
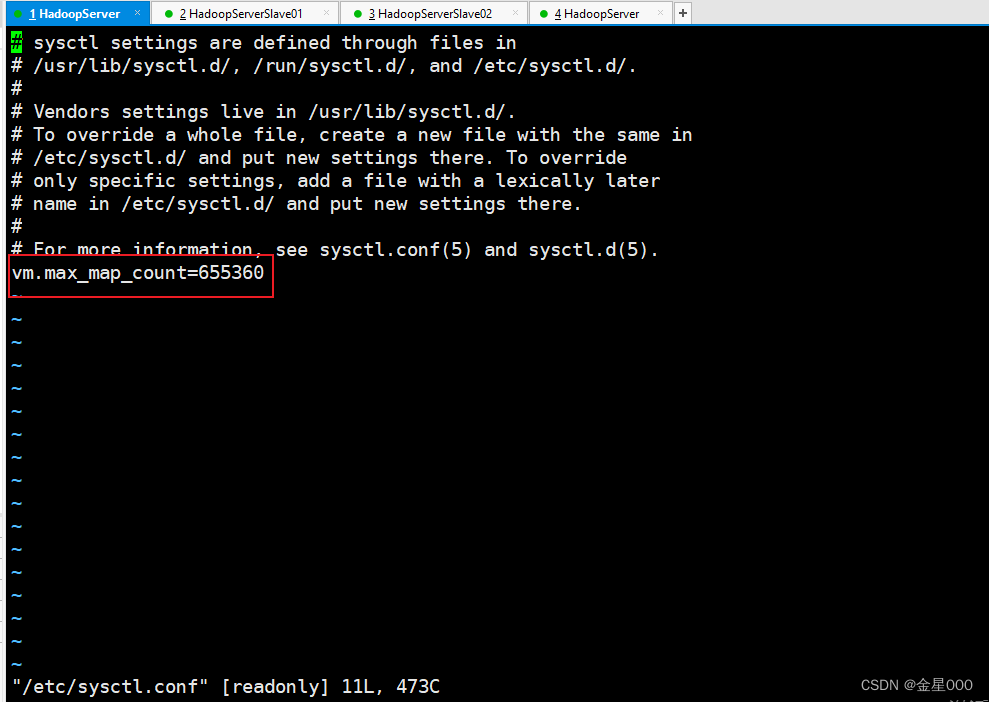
运行vi /etc/sysctl.conf命令,修改sysctl.conf文件中vm.max_map_count参数,该参数设置进程可以适用的的VMA(虚拟内存区域)数量。修改完成后,执行“sysctl -p”命令,使修改的配置生效
elasticsearch配置
在/usr/local/software/elasticsearch-7.17.10/config 下的文件
jvm.options
################################################################
##
## JVM configuration
##
################################################################
##
## WARNING: DO NOT EDIT THIS FILE. If you want to override the
## JVM options in this file, or set any additional options, you
## should create one or more files in the jvm.options.d
## directory containing your adjustments.
##
## See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/jvm-options.html
## for more information.
##
################################################################
################################################################
## IMPORTANT: JVM heap size
################################################################
##
## The heap size is automatically configured by Elasticsearch
## based on the available memory in your system and the roles
## each node is configured to fulfill. If specifying heap is
## required, it should be done through a file in jvm.options.d,
## and the min and max should be set to the same value. For
## example, to set the heap to 4 GB, create a new file in the
## jvm.options.d directory containing these lines:
##
-Xms512m
-Xmx512m
##
## See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/heap-size.html
## for more information
##
################################################################
################################################################
## Expert settings
################################################################
##
## All settings below here are considered expert settings. Do
## not adjust them unless you understand what you are doing. Do
## not edit them in this file; instead, create a new file in the
## jvm.options.d directory containing your adjustments.
##
################################################################
## GC configuration
8-13:-XX:+UseConcMarkSweepGC
8-13:-XX:CMSInitiatingOccupancyFraction=75
8-13:-XX:+UseCMSInitiatingOccupancyOnly
## G1GC Configuration
# NOTE: G1 GC is only supported on JDK version 10 or later
# to use G1GC, uncomment the next two lines and update the version on the
# following three lines to your version of the JDK
# 10-13:-XX:-UseConcMarkSweepGC
# 10-13:-XX:-UseCMSInitiatingOccupancyOnly
14-:-XX:+UseG1GC
## JVM temporary directory
-Djava.io.tmpdir=${ES_TMPDIR}
## heap dumps
# generate a heap dump when an allocation from the Java heap fails; heap dumps
# are created in the working directory of the JVM unless an alternative path is
# specified
-XX:+HeapDumpOnOutOfMemoryError
# exit right after heap dump on out of memory error. Recommended to also use
# on java 8 for supported versions (8u92+).
9-:-XX:+ExitOnOutOfMemoryError
# specify an alternative path for heap dumps; ensure the directory exists and
# has sufficient space
-XX:HeapDumpPath=data
# specify an alternative path for JVM fatal error logs
-XX:ErrorFile=logs/hs_err_pid%p.log
## JDK 8 GC logging
8:-XX:+PrintGCDetails
8:-XX:+PrintGCDateStamps
8:-XX:+PrintTenuringDistribution
8:-XX:+PrintGCApplicationStoppedTime
8:-Xloggc:logs/gc.log
8:-XX:+UseGCLogFileRotation
8:-XX:NumberOfGCLogFiles=32
8:-XX:GCLogFileSize=64m
# JDK 9+ GC logging
9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
network.host: 192.168.128.130
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["192.168.128.130","192.168.128.131","127.0.0.1", "192.168.128.132"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
#
# ---------------------------------- Security ----------------------------------
#
# *** WARNING ***
#
# Elasticsearch security features are not enabled by default.
# These features are free, but require configuration changes to enable them.
# This means that users don’t have to provide credentials and can get full access
# to the cluster. Network connections are also not encrypted.
#
# To protect your data, we strongly encourage you to enable the Elasticsearch security features.
# Refer to the following documentation for instructions.
#
# https://www.elastic.co/guide/en/elasticsearch/reference/7.16/configuring-stack-security.html
# -------------------------------------geo--------------------------------#
ingest.geoip.downloader.enabled: false
master
node.name node-1
network.host 192.168.128.130
slave01
node.name node-2
network.host 192.168.128.131
slave02
node.name node-3
network.host 192.168.128.132
elasticsearch.yml文件中的其他配置信息一致即可
5.集群搭建
在slave01和slave02的上重复前面的操作,然后依次启动即可
启动执行 进入/usr/local/software/elasticsearch-7.17.10/bin
./elasticsearch
这里注意需要使用非root用户去执行
6.从web端查看
查看单点信息
http://192.168.128.130:9200

查看集群信息
http://192.168.128.130:9200/_cat/nodes
















 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









