







对于java HashMap类的心得
最近闲来无事,拿jdk源码看了下,看到 HashMap类,对里面的一些方法做了下研究,写到博客里记录下。
hashmap是用hash表来存储数据,在此不做赘述,只是把其中一些方法/属性拿来解释下。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
**/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;DEFAULT_INITIAL_CAPACITY :初始容量 16 ;
对于此属性的解释:在初始化hashmap时,不是你给它指定多少容量它就是多大,容量始终是不小于用户给定的容量,代码:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
/**initialCapacity为指定容量,初始化时java会根据给定值自动计算出一个大小为2的n次幂的值来**/
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}DEFAULT_LOAD_FACTOR:默认装载系数0.75
loadFactor 用户指定的装载系数
当hashmap没有指定装载系数时默认使用0.75;
当hashmap中存储数量大于capacity * loadFactor时hashmap会调用resize方法自动扩容为原来的2倍。
MAXIMUM_CAPACITY :最大容量为2^30
threshold:极限值,即capacity * loadFactor;
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}可以看到这里面最关键的两个方法:
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
hash方法用来获取hash值,indexFor方法用来计算元素存放数组位置。
hash函数代码:
//h为key值的hash值
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);indexFor代码:
static int indexFor(int h, int length) {
return h & (length-1);
}可以看到用来计算位置的hash值是经过两次hash算法的产物,为什么要这样做呢?
首先要理解hash表,hash表是时一个散列函数,当我们对hash表查询时涉及到平均查找长度的概念。平均查找长度越大,hash表效率越慢,盗图一张说明: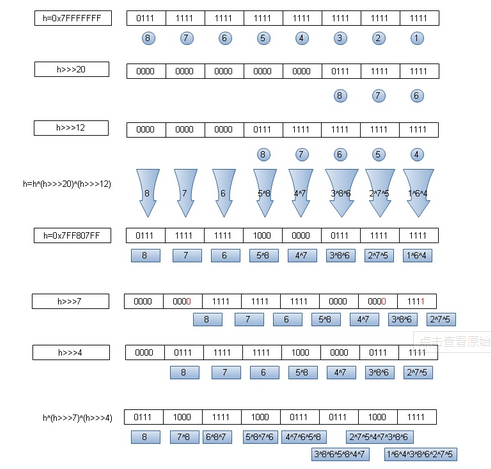
从图中可看出经过2次计算hash值,由越低的位置是由不同位置异或所得,这样与容量进行&运算后所得的位置冲突的几率就变小,hash表分部也就越均匀。
从代码中得知hashmap是由空间换时间的一个类,因为hashmap中存储的数据量总不会大于额定容量的0.75倍,也就是说假如容量是1024,那么最多存储的数据量是1024*0.75(hashmap最理想的存储情况是一个数组位置的链表只存储一个数据,有1/4的空间是浪费的),超过这个值自动扩容并重新计算元素位置。
前面说到容量值始终是2^n,即使你给它赋值为其他值。这么做真的不是人家闲的蛋疼,indexFor方法中可以看到人家的良苦用心。假如容量length是个奇数,(leng-1)与任意值求与运算,最低位的值始终为0,这导致有些位置永远不会被放入元素,hashmap在空间上本来就是牺牲的,如果这样的话岂不是又做出来一些空间上和时间上(平均查找长度)的无谓牺牲?
在用到hashmap存储数据大于12个时一定要给它初始化容量,这个容量要根据自己所存储数据的数量进行合理分配,做到不浪费空间又不浪费时间,比如数据量是count,那么设置长度为大于count*4/3的2^n.















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









