






 文章介绍了如何在UltralyticsYOLOv8的代码库中实现BIFPNConcat2和Concat3模块,这两个模块用于在YOLOv8的检测头中融合不同层次的特征。作者指导读者如何在nn文件夹中添加这些模块,并提供了相应的配置更改。
文章介绍了如何在UltralyticsYOLOv8的代码库中实现BIFPNConcat2和Concat3模块,这两个模块用于在YOLOv8的检测头中融合不同层次的特征。作者指导读者如何在nn文件夹中添加这些模块,并提供了相应的配置更改。
BIFPN我只是简单了解了一下他的结构图还未做深如了解,在此就不介绍了。可以自己先去研究论文,我研究完再补充。论文地址:https://arxiv.org/abs/1911.09070
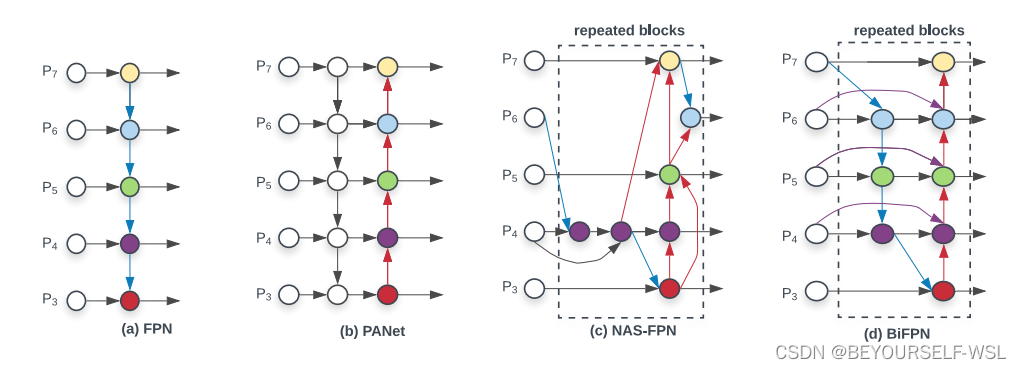
直接开始改进步骤
1.在ultralytics/nn文件夹下创建一个新的BIFPN文件,代码如下:
import math
import numpy as np
import torch
import torch.nn as nn
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat2, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
# 三个分支concat操作
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)2.在nn文件夹下的task.py文件中加入:
from ultralytics.nn.BIFPN import BiFPN_Concat2,BiFPN_Concat3 然后在task.py 文件中找到下面这段代码
elif m is Concat:
c2 = sum(ch[x] for x in f)直接把它修改为
elif m in [Concat,BiFPN_Concat2, BiFPN_Concat3]:
c2 = sum(ch[x] for x in f)3.其中v8的配置文件修改为;
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, BiFPN_Concat2, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, BiFPN_Concat2, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 6, 12], 1, BiFPN_Concat3, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, BiFPN_Concat2, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
完美运行成功!


















 3337
3337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









