






本篇文章是自己对transformer的理解,有不正确的地方望大家指出!!!!互相学习
直接上图:
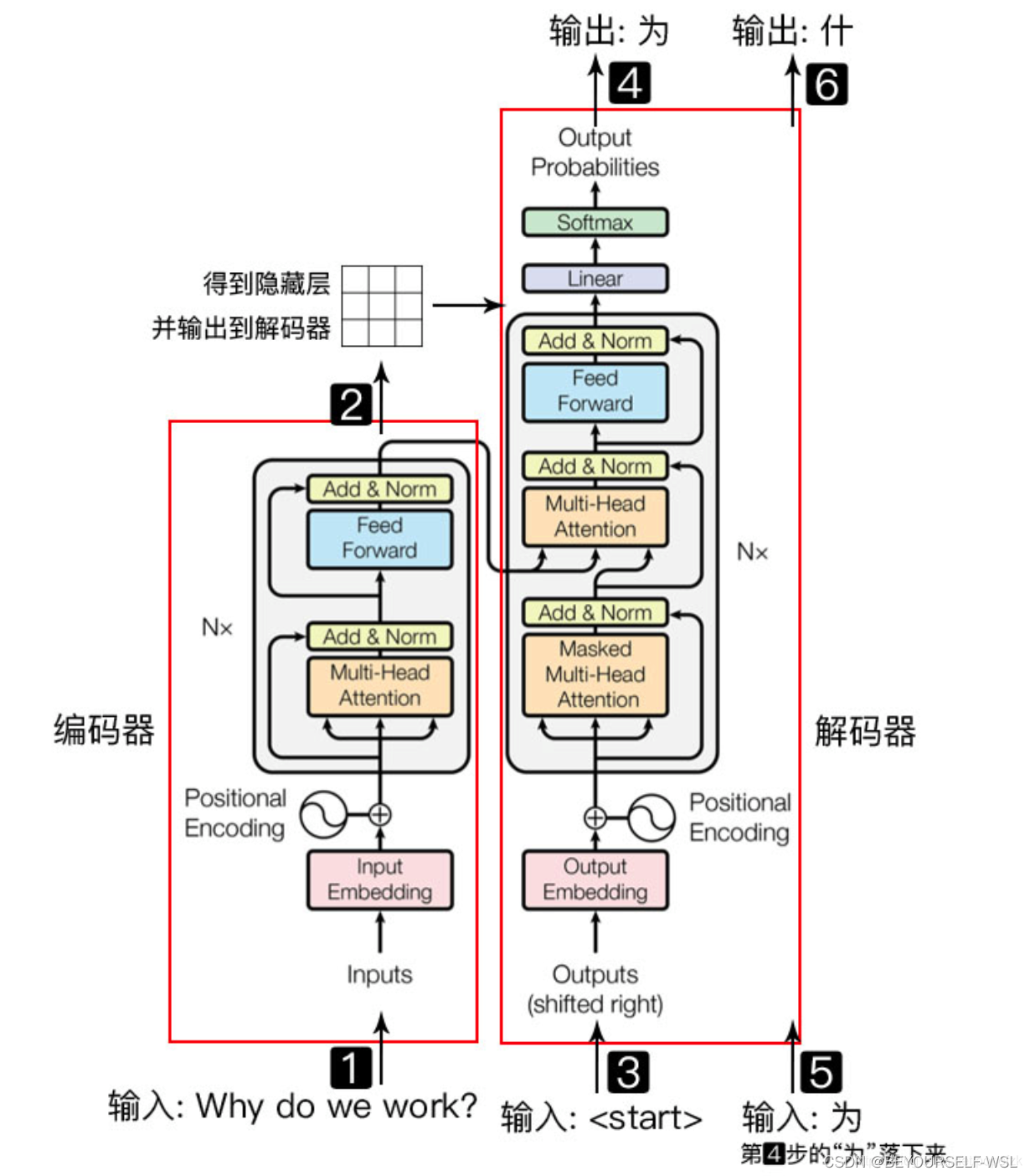 transformer由编码器解码器结构组成,Encoder-Decoder并不是一个具体的模型,而是一类框架。我以为是很陌生的一个专业名词,但是我们熟悉的CNN也可以认为是用编码器解码器结构。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
transformer由编码器解码器结构组成,Encoder-Decoder并不是一个具体的模型,而是一类框架。我以为是很陌生的一个专业名词,但是我们熟悉的CNN也可以认为是用编码器解码器结构。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
CNN:
CNN一直扛着视觉的大旗,transformer出来之后爆火,也逐渐应用于视觉领域。那它与CNN相比有什么优势呢?做了一下小小的了解:卷积提取的特征图只有局部信息,不能提取全局数据之间的长距离特征。比如识别人脸,卷积可以提取眼睛大小,鼻子翘不翘等特征,但是无法形成“鼻子在眼睛下面”这种长距离特征。但是他也有解决办法就是扩大感受野,需要更大的卷积核更深层的卷积,但是这样计算效率就大幅度下降了。但是transformer呢加了自注意力机制,自注意力层输入特征图之后,它会计算特征与特征之间的注意力权重,这样我们就可以得到一个新的带着特征与特征之间关系权重系数的特征映射。
Encoder块:
1.Positional Encoding
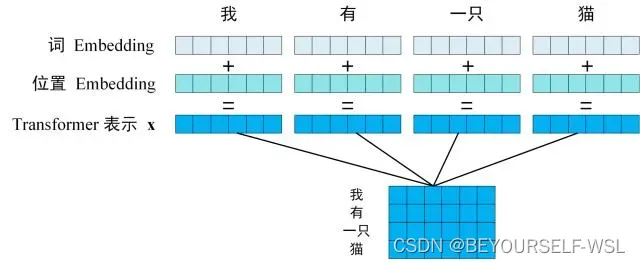
为什么要加位置编码?生活中我们人类看到一个句子,我们很容易就知道这个句子中每个词的绝对位置以及相对位置。但是transformer模型是并行计算的,对于它来说没办法分辨词与词之间的顺序关系,所以需要给输入加上位置信息。
位置计算公式:

pos是指单词在句子中的位置,d表示的是维度。i表示positional encoding的维度,从0~d/2维度。表示第pos个位置的第2i维或者第2i+1维。为什么要用这样的计算公式?
①:使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
②:可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
2.Slef-Attention
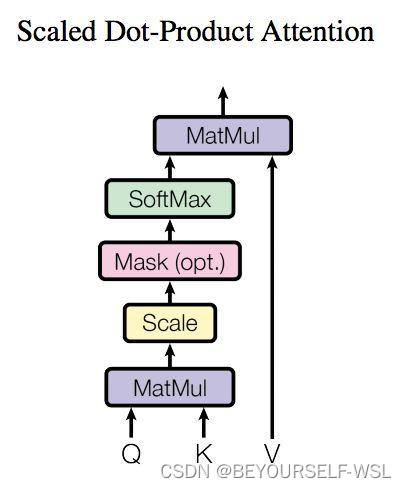
模型内部结构是左侧为Encoder block,右侧为Decoder block。Muti-Head Attention块是由多个Slef-Attention组成的,Slef-Attention内部结构如下图:
Attention的输入是一个个词向量组成的矩阵X,矩阵X分别于参数矩阵Wq,Wk,Wv相乘之后得到Q,K,V矩阵。Q,K,V的每一行都表示一个单词。
根据Self-Attention计算公式,首先是Q矩阵点乘K转置矩阵,在除以矩阵维度的平方根(为了防止内积过大·······)Q与K转置的点乘计算的是词与词之间的相似度,词与自己本身的attention分数最高。结果再与V矩阵相乘,求得每个单词的矩阵向量。

3.Multi-Head Attention
论文中H=8也就是由八个self-attention块组成,我理解应该是把权重矩阵分为八块分别与输入矩阵X相乘得到八组QKV矩阵,经过self-attention计算之后分别得到一个矩阵Z。之后将八个Z矩阵concat在一起,传入一个linear层得到最终的Z矩阵,Z矩阵维度与输入矩阵X的维度是一样的。
4.Add&Norm
后面层的Add是一种残差连接,指的是X+Multi-Head Attention(X),用于解决多层网络训练精度退化问题。Norm指的是layer normalization,与BN层作用一样。加快网络收敛速度
BatchNorm和LayerNorm的区别:
BatchNorm是把一个Batch中同一通道的所有特征视为一个分布,有几个通道就有几个分布
LayerNorm是把一个样本的所有词义向量视为一个分布,即有几个句子就有几个分布
Decoder块:
1.Mask Multi-Head Attention
第一个多头注意力层采取了mask操作,为什么呢?因为一句话的词与词之间都有顺序关系,对于预测的话需要先预测前面第i个词再预测后面第i+1个词。(因为未来的事不可知)mask矩阵就是一个与输入矩阵维度相同的下三角矩阵,在进行softmax函数之前与Q点乘K转置的结果进行按位相乘。
2.第二个muti-head attention
与之前的多头注意力块计算是一致的,只是这个计算的输入矩阵KV是Encoder块的输出矩阵。















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









