







由数组移位引发的思考:
看代码里有用数组实现FIFO的移位,使用了for循环前向移位
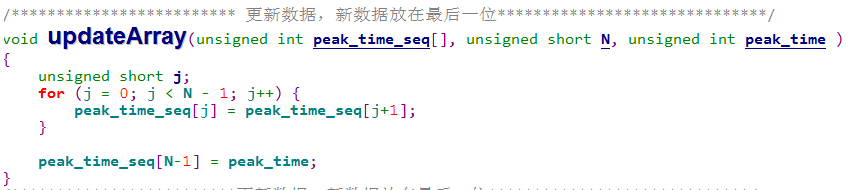
本来猜测是否使用memcpy类的函数会更快一些。后来发现memcpy也不是直接对内存块进行操作。
cpu的快速执行非常依赖于cache,如果cache不命中,cpu会浪费一些时钟周期在等待内存上。(cpu缓存和内存的读取速度要快一个数量级)。小段循环结构容易命中cache。
所以有人开发xmemcpy,https://aigo.iteye.com/blog/2299702
在多核CPU中每个核拥有独立的L1和L2两级cache,L1一般把指令和数据分布存放。为了保证所有的核看到正确的内存数据,一个核在写入L1后,CPU会执行Cache一致性算法把对应的cacheline同步到其他核(us级别),相比之下,写入L1cache只需要ns级别。当很多线程频繁修改某字段的啥时候,这个字段所在的cacheline就不停被同步到其他核,这种现象叫做cache bouncing。三级cache由所有的核共有。
内存数据加载到cache后,要写回内存有五种策略:写通,写回,写一次,wc,uc(内存中一块无法cache的区域)
__pure 函数优化,对于没有的读/写全局变量的函数,进行优化。(有点像)???但是好像用处并不大















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









