









目录
最近公司需要开发大数据相关项目,已经很久没用hadoop了,研究了一下hadoop,发现hadoop都更新到了3.x版本了,在此做下记录:
Hadoop集群角色
Hadoop生态体系中总共会出现如下进程角色:Hadoop HDFS的管理角色:Namenode进程(仅需1个即可(管理者))
Hadoop HDFS的工作角色:Datanode进程(多个(工人,越多越好,一个机器启动一个))
Hadoop YARN的管理角色:ResourceManager进程(仅需1个即可(管理者))
Hadoop YARN的工作角色:NodeManager进程(多个(工人,越多越好,一个机器启动一个))
Hadoop 历史记录服务器角色:HistoryServer进程(仅需1个即可(功能性进程))
Hadoop 代理服务器角色:WebProxyServer进程(仅需1个即可(功能性进程))
我这里准备了三台机器:一台主机 node12 ip:192.168.1.12,2台从机 node13 ip:192.168.1.13,node15 ip:192.168.1.15
node12安装:Namenode、Datanode、ResourceManager、NodeManager、HistoryServer、WebProxyServer
node13安装:Datanode、NodeManager
node15安装:Datanode、NodeManager
一、前置条件
JDK、SSH免密、关闭防火墙、配置主机名映射
由于hadoop是基于java开发,所以linux需要jdk环境,jdk安装这里不再赘述
配置SSH免密:
在node12执行
# 生成秘钥
ssh-keygen
# 复制秘钥到其他机器
ssh-copy-id node13
ssh-copy-id node15同理在node13,node15机器上执行此命令
关闭SELINUX防火墙:
vi /etc/selinux/config修改 SELINUX=disabled
可通过sestatus 命令查看selinux是否禁用成功
~# sestatus
SELinux status: disabled配置主机名映射:
修改host文件
vi /etc/hosts我这都是内网机器,分别12、 13、 15添加ip对应host名字
192.168.1.12 node12
192.168.1.13 node13
192.168.1.15 node15
二、安装包下载
hadoop 3.2.4官网下载:hadoop 3.2.4
下载好后解压文件
tar -zxvf hadoop-3.2.4.tar.gz 复制到/usr/local下
mv hadoop-3.2.4 /usr/local/进入hadoop文件夹,准备修改配置文件
cd /usr/local/hadoop-3.2.4/三、配置文件更改
Hadoop的配置文件要修改的东西比较多
首先进入/usr/local/hadoop-3.2.4/etc/hadoop/文件夹下,hadoop所有配置文件都存放于此
修改hadoop-env.sh文件
此env文件是配置一些Hadoop用到的环境变量
属于临时变量,在Hadoop运行时有用
如果要永久生效,需要写到/etc/profile中
vi hadoop-env.sh
直接G进入最后,增加以下内容
# 在文件最后加入:
# 配置Java安装路径
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 配置Hadoop安装路径
export HADOOP_HOME=/usr/local/hadoop-3.2.4
# Hadoop hdfs配置文件路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN配置文件路径
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN 日志文件夹
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# Hadoop hdfs 日志文件夹
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
# Hadoop的使用启动用户配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root其中JAVA_HOME和HADOOP_HOME根据实际情况进行调整
随后修改core-site.xml文件
在<configuration></configuration>中间加入以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://node12:8020</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description></description>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property> hdfs-site.xml文件
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/nn</value>
<description>Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node12,node13,node15</value>
<description>List of permitted DataNodes.</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description></description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description></description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dn</value>
</property>
mapred-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFAmapred-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node12:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node12:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/hadoop/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/hadoop/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>yarn-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
yarn-site.xml文件
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log.server.url</name>
<value>http://node12:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node12:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node12</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>修改workers文件 vi workers
node12
node13
node15分发hadoop到其他机器
scp -r /usr/local/hadoop-3.2.4 node13:/usr/local
scp -r /usr/local/hadoop-3.2.4 node15:/usr/local在每台机器上建立文件夹
mkdir -p /data/hadoop/nn
mkdir -p /data/hadoop/dn
mkdir -p /data/hadoop/nm-log
mkdir -p /data/hadoop/nm-local修改每台机器环境变量 vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile 一下生效
这样直接可以在任意位置执行hadoop脚本命令
四、启动集群
格式化namenode,在主节点node12上执行format命令,格式化命令只执行一次!
-
hadoop namenode -format
然后启动hdfs
-
start-dfs.sh # 如需停止可以执行 stop-dfs.sh
启动yarn
-
start-yarn.sh # 如需停止可以执行 stop-yarn.sh
启动历史服务器
mapred --daemon start historyserver
# 如需停止将start更换为stop
mapred --daemon stop historyserver启动web代理服务器
yarn-daemon.sh start proxyserver
# 如需停止将start更换为stop
yarn-daemon.sh stop proxyserver启动完毕,验证一下是否成功
在node12、node13、node15上通过jps命令验证进程是否都启动成功
node12:应该包含DataNode和NameNode,ResourceManager进程
node13和node15:应该包含DataNode, NodeManager进程
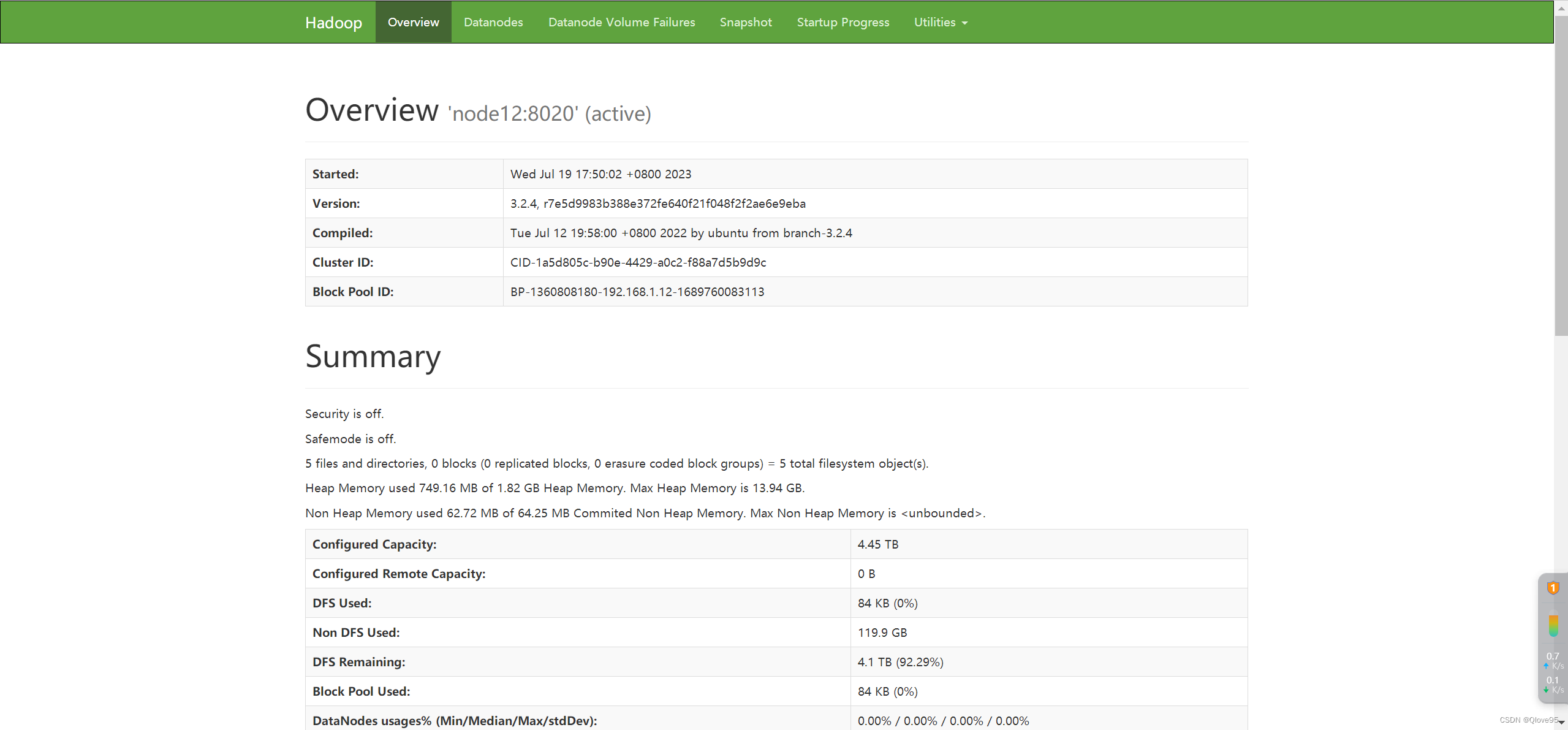
验证HDFS:浏览器打开:http://192.168.1.12:9870,可正常访问
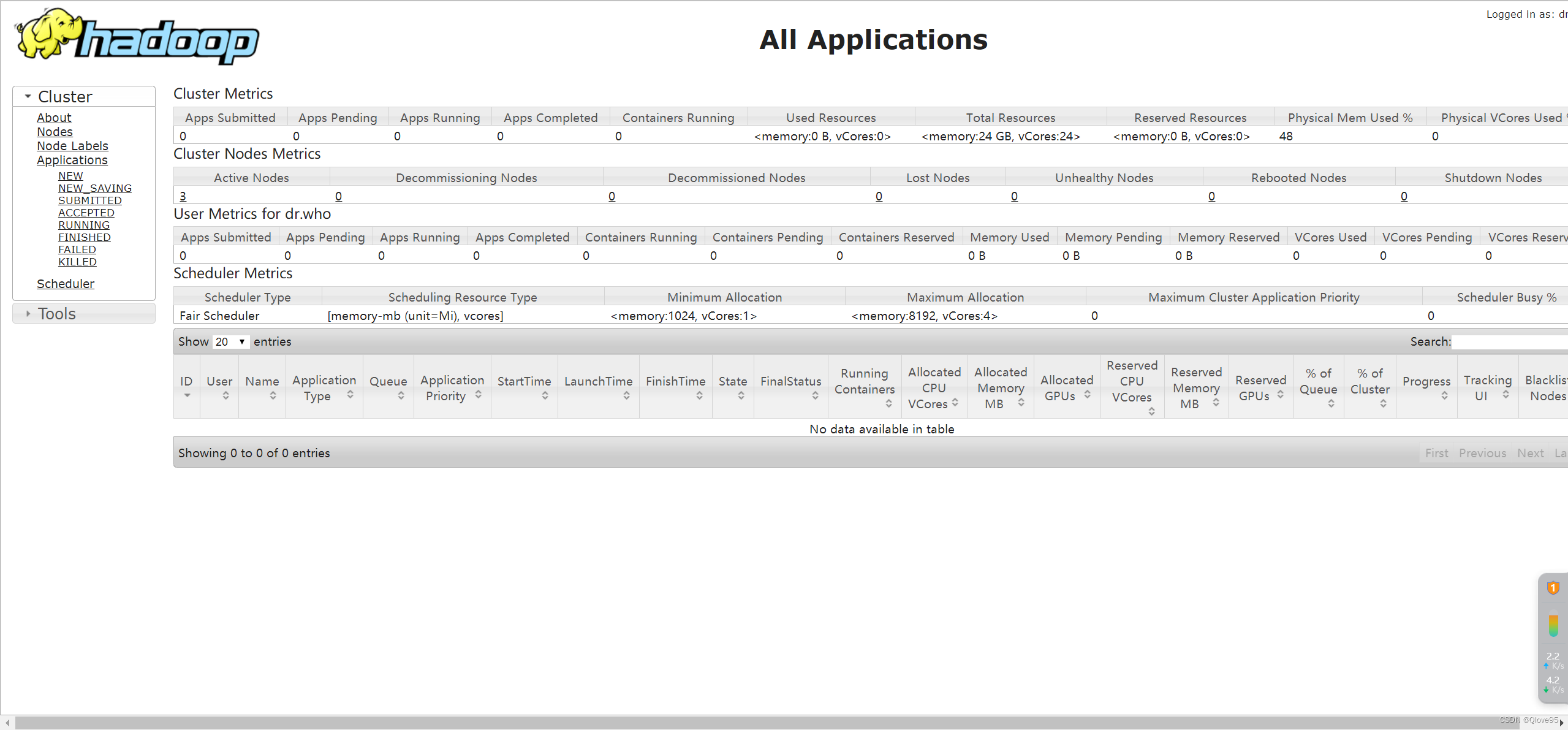
验证YARN:浏览器打开:http://192.168.1.12:8088,可正常访问
hadoop集群部署成功,可以继续研究hadoop了















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









