







1. 反压机制
flink的反压机制,在1.4和1.5版本有一个较大改动,在1.5引入了Credit反压机制。
1.1. flink1.5前的反压机制问题
1.5版本前反压机制会存在当一个 Task 出现反压时,可能导致其他正常的 Task 接收不到数据
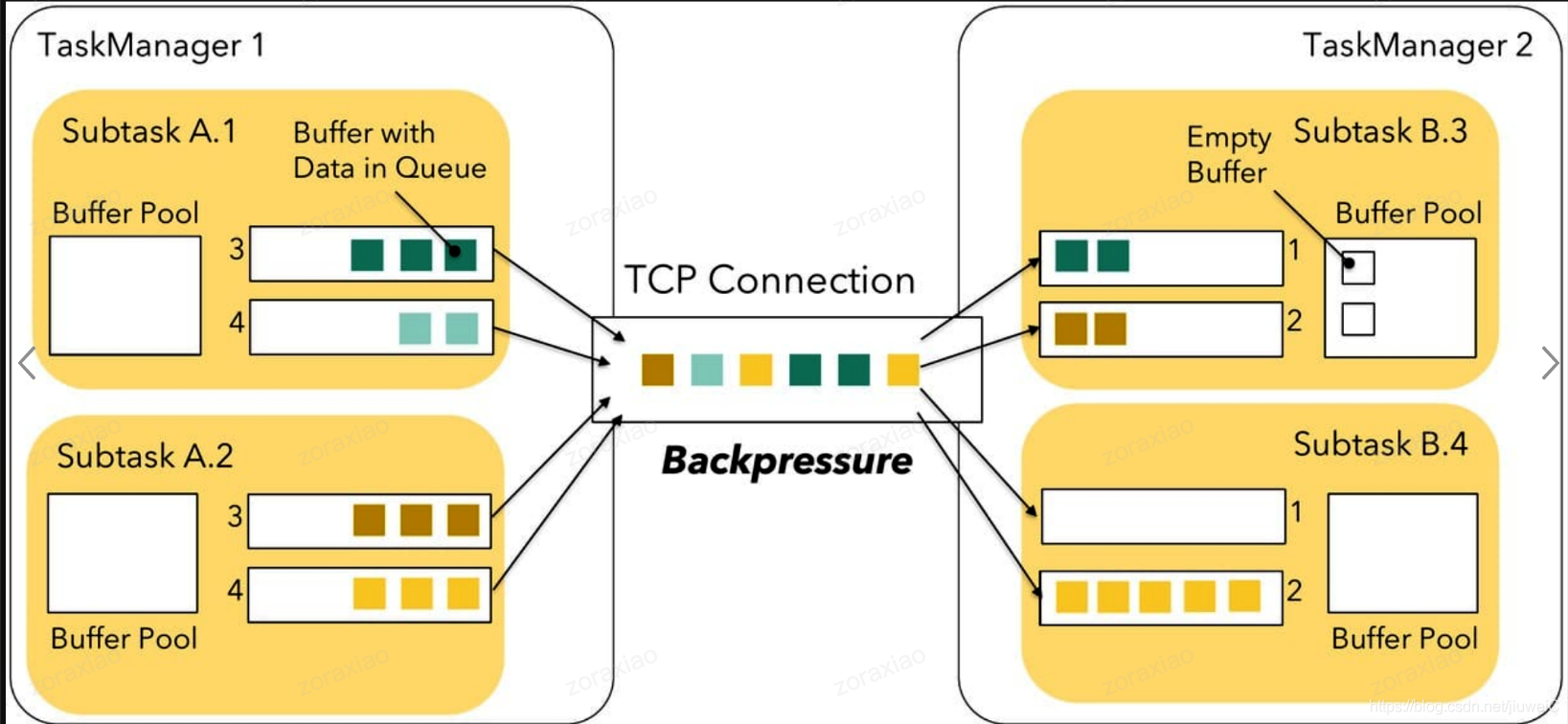
如上图所示,我们的任务有4个 SubTask,SubTask A 是 SubTask B的上游,即 SubTask A 给 SubTask B 发送数据。Job 运行在两个 TaskManager中, TaskManager 1 运行着 SubTask A.1 和 SubTask A.2, TaskManager 2 运行着 SubTask B.3 和 SubTask B.4。
现在假如由于CPU共享或者内存紧张或者磁盘IO瓶颈造成 SubTask B.4 遇到瓶颈、处理速率有所下降,但是上游源源不断地生产数据,所以导致 SubTask A.2 与 SubTask B.4 产生反压。
这里需要明确一点:不同 Job 之间的每个(远程)网络连接将在 Flink 的网络堆栈中获得自己的TCP通道。 但是,如果同一 Task 的不同 SubTask 被安排到同一个TaskManager,则它们与其他 TaskManager 的网络连接将被多路复用并共享一个TCP信道以减少资源使用。例如,图中的 A.1 -> B.3、A.1 -> B.4、A.2 -> B.3、A.2 -> B.4 这四条将会多路复用共享一个 TCP 信道。
现在 SubTask B.3 并没有压力,从上面跨 TaskManager 的反压流程,我们知道当上图中 SubTask A.2 与 SubTask B.4 产生反压时,会把 TaskManager1 端该任务对应 Socket 的 Send Buffer 和 TaskManager2 端该任务对应 Socket 的 Receive Buffer 占满,多路复用的 TCP 通道已经被占住了,会导致 SubTask A.1 和 SubTask A.2 要发送给 SubTask B.3 的数据全被阻塞了,从而导致本来没有压力的 SubTask B.3 现在接收不到数据了。
所以,Flink 1.5 版之前的反压机制会存在当一个 Task 出现反压时,可能导致其他正常的 Task 接收不到数据。
1.2. flink1.5后Credit反压机制问题
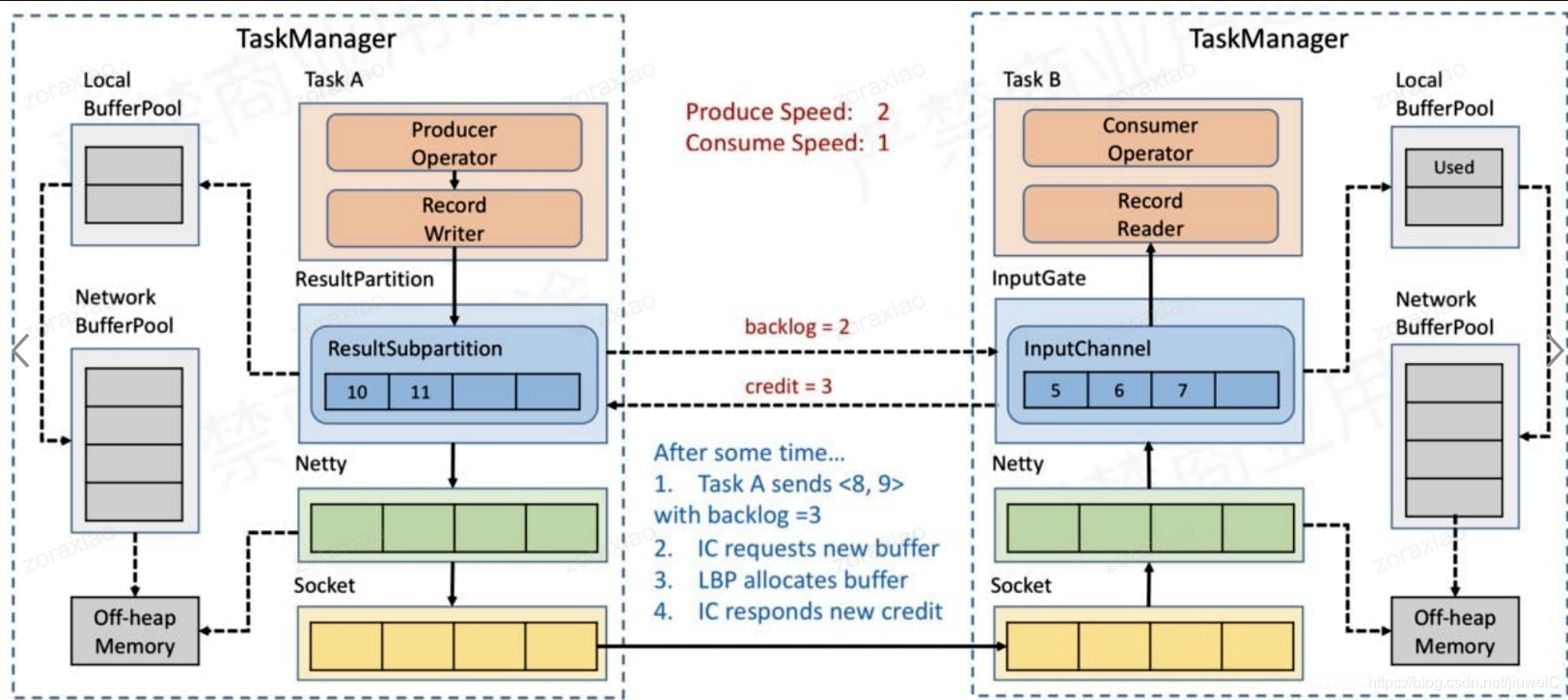
Task A 向 Task B 发送了数据 <8,9> 和 backlog size =3,下游 InputChannel 接受完 <8,9> 后,发现上游目前积压了 3 个buffer的数据,但是自己的缓冲区不够,于是向 LocalBufferPool 申请 buffer 空间,申请成功后,向上游反馈 credit = 3,表示下游目前可以接受 3 条记录(实际上是以 Buffer 为单位,而不是记录数,Flink 将真实记录序列化后的二进制数据放到 Buffer 中),然后上游下次最多发送 3 个buffer的数据给下游。
持续下去,上游生产数据速率比下游消费速率快,所以 LocalBufferPool 和 NetWork BufferPool 都会被申请完,下游的 InputChannel 没有可用的缓冲区了,所以会向上游反馈 credit = 0,然后上游就不会发送数据到 Netty。所以基于 Credit 的反压策略不会导致 Netty 和 Socket 的数据积压。当然上游也不会一直不发送数据到下游,上游会定期地仅发送 backlog size 给下游,直到下游反馈 credit > 0 时,上游就会继续发送真正的数据到下游了。
2. 数据在Buffer内停留方式
2.1. Buffer边满时
Flink 在数据传输时,会把数据序列化成二进制然后写到 Buffer 中,当 Buffer 满了,需要 Flush(默认为32KiB,通过taskmanager.memory.segment-size设置)
2.2. Buffer timeout 时
当流量低峰或者测试环节,可能1分钟都没有 32 KB的数据,就会导致1分钟内的数据都积攒在 Buffer 中不会发送到下游 Task 去处理,从而导致数据出现延迟,这并不是我们想看到的。所以 Flink 有一个 Buffer timeout 的策略,意思是当数据量比较少,Buffer 一直没有变满时,后台的 Output flusher 线程会强制地将 Buffer 中的数据 Flush 到下游。Flink 中默认 timeout 时间是 100ms,即:Buffer 中的数据要么变满时 Flush,要么最多等 100ms 也会 Flush 来保证数据不会出现很大的延迟。当然这个可以通过 env.setBufferTimeout(timeoutMillis) 来控制超时时间。
timeoutMillis > 0 表示最长等待 timeoutMillis 时间,就会flush
timeoutMillis = 0 表示每条数据都会触发 flush,直接将数据发送到下游,相当于没有Buffer了(避免设置为0,可能导致性能下降)
timeoutMillis = -1 表示只有等到 buffer满了或 CheckPoint的时候,才会flush。相当于取消了 timeout 策略
2.3. 特殊事件来临时,例如:CheckPoint 的 barrier 来临时
一些特殊的消息如果通过 RecordWriter 发送,也会触发立即 Flush 缓存的数据。其中最重要的消息包括 Checkpoint barrier 以及 end-of-partition 事件,这些事件应该尽快被发送,而不应该等待 Buffer 被填满或者 Output flusher 的下一次 Flush。当然如果出现反压,CheckPoint barrier 也会等待,不能发送到下游
3. 可用缓冲区大小
一般不需要配置taskmanager总的缓冲区大小
总的可用缓冲区内存为:taskmanager.network.numberOfBufferstaskmanager.memory.segment-size ,即缓冲区个数缓冲区大小。
taskmanager.network.numberOfBuffers :
网络堆栈可用的缓冲区数量。这个数字决定了TaskManager可以同时拥有多少流数据交换通道,以及这些通道的缓冲程度。如果一个作业被拒绝,或者你收到系统没有足够缓冲区可用的警告,增加这个值(默认值:2048,参见flink1.2官方教程,只有1.2版本的文档中找到了默认值)。
官方推荐大小 #slots-per-TM^2 * #TMs * 4,即单个taskmanager的slot数的平方taskManager个数4。例如 20台并行度为8的机器,8*8 *20 *4 =5120。
如果实际需要的缓冲区数小于taskmanager.network.numberOfBuffers,则会报错。java.io.IOException: Insufficient number of network buffers: required 80, but only 8 available. The total number of network buffers is currently set to 128 of 32768 bytes each. You can increase this number by setting the configuration keys ‘taskmanager.network.numberOfBuffers’.
taskmanager.memory.segment-size:单个缓冲区大小
4.实际分配的缓冲区大小
以下只适用于flink1.5后的版本。
一个task,根据并发可能会拥有多个subtask。每个subtask拥有一个resultpartion,一个resultpartion,根据逻辑的channel会分为多个subResultpation。一个逻辑的channel会有一个subResultpation。其中一个逻辑的channel对应下有的一个subTask
每个channel拥有自己独立的buffer池, 每一端所有的Channel会共享一个浮动的buffer池。
| key | 默认值 | 含义 |
|---|---|---|
| taskmanager.network.memory.buffers-per-channel | 2 | Number of exclusive network buffers to use for each outgoing/incoming channel (subpartition/inputchannel) in the credit-based flow control model. It should be configured at least 2 for good performance. 1 buffer is for receiving in-flight data in the subpartition and 1 buffer is for parallel serialization |
| taskmanager.network.memory.floating-buffers-per-gate | 8 | Number of extra network buffers to use for each outgoing/incoming gate (result partition/input gate). In credit-based flow control mode, this indicates how many floating credits are shared among all the input channels. The floating buffers are distributed based on backlog (real-time output buffers in the subpartition) feedback, and can help relieve back-pressure caused by unbalanced data distribution among the subpartitions. This value should be increased in case of higher round trip times between nodes and/or larger number of machines in the cluster. |
| taskmanager.network.memory.max-buffers-per-channel | 10 | Number of max buffers that can be used for each channel. If a channel exceeds the number of max buffers, it will make the task become unavailable, cause the back pressure and block the data processing. This might speed up checkpoint alignment by preventing excessive growth of the buffered in-flight data in case of data skew and high number of configured floating buffers. This limit is not strictly guaranteed, and can be ignored by things like flatMap operators, records spanning multiple buffers or single timer producing large amount of data. |
参考
官方flink网络栈














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









