







 本文档介绍了如何利用SpeechRecognitionEngine在.NET Framework 4中实现speech-to-text功能。首先,初始化语音识别引擎并配置区域设置、输入类型等。接着,设置语音输入源,如从.wav文件获取。然后,不深入研究语法规范,采用默认设置。最后,注册事件监听器以实现实时和识别后的内容处理。提供了使用VS2012的源代码示例和音频文件链接。
本文档介绍了如何利用SpeechRecognitionEngine在.NET Framework 4中实现speech-to-text功能。首先,初始化语音识别引擎并配置区域设置、输入类型等。接着,设置语音输入源,如从.wav文件获取。然后,不深入研究语法规范,采用默认设置。最后,注册事件监听器以实现实时和识别后的内容处理。提供了使用VS2012的源代码示例和音频文件链接。
利用microsoft help view,可以得到相关的简单示例,在这里,就简单梳理下,speech-to-text的过程操作。
第一步,实例化一个语音识别引擎SpeechRecognitionEngine,进行相关的属性配置,比如有区域设置、语音输入类型、语法规范,等等
1.区域配置,其实,可以在初始化引擎对象时,默认就行;也就可以这样制定初始化new SpeechRecognitionEngine(new CultureInfo("en-US"))。
通过help view示例,可查询到引擎的默认属性。
RecognizerInfo info = sre1.RecognizerInfo;
string AudioFormats = "";
foreach (SpeechAudioFormatInfo fmt in info.SupportedAudioFormats)
{
AudioFormats += String.Format(" {0}\n", fmt.EncodingFormat.ToString());
}
string AdditionalInfo = "";
foreach (string key in info.AdditionalInfo.Keys)
{
AdditionalInfo += String.Format(" {0}: {1}\n", key, info.AdditionalInfo[key]);
}
Console.WriteLine(String.Format(
"Name: {0 }\n" +
"Description: {1} \n" +
"SupportedAudioFormats:\n" +
"{2} " +
"Culture: {3} \n" +
"AdditionalInfo: \n" +
" {4}\n",
info.Name.ToString(),
info.Description.ToString(),
AudioFormats,
info.Culture.ToString(),
AdditionalInfo));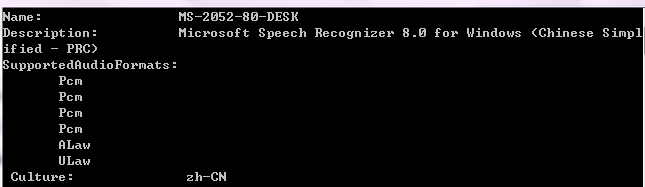
2.语音输入类型
提供有SetInputToAudioStream(),SetInputToDefaultAudioDevice(),SetInputToNull(),SetInputToWaveFile(),SetInputToWaveStream()五种方法,详见help文档
这里使用了通过win7的录音笔,录制的音频wma,再通过格式转化为wav。
3.语法规范
没有深究,help文档也有详细说明,直接就按默认的。
第二步,设置事件响应。在本示例中,设置了两个事件,即实时读取识别内容和识别后在读取。注意:分别测试两个事件较好。
sre1.SpeechRecognized += new EventHandler<SpeechRecognizedEventArgs>(SpeechRecognized); //sre1为语音引擎实例化的对象
sre1.SpeechHypothesized += new EventHandler<SpeechHypothesizedEventArgs>(SpeehchHypothesizing);
//响应事件后,打印识别内容。
static void SpeechHypothesizing(object sender, SpeechHypothesizedEventArgs e)
{
Console.WriteLine(e.Result.Text);
}

原文是:本书的产品设计应用神经生物学、认知科学、以及学习理论,这使得这本书能够将这些知识深深地印在你的脑海里,不容易被遗忘。
下面是用vs2012写的源代码和音频文件。
http://download.csdn.net/detail/jixiang1234567/6294101















 2092
2092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









