






[TOC]
概述
RocketMQ 4.9.1 版本 针对 Broker 做了一系列性能优化,提升了消息发送的 TPS。前文曾就 4.9.1 版本的优化做了深入分析。
在 2022 年的 2 月底,RocketMQ 4.9.3 版本 发布,其对 Broker 做了更进一步的性能优化,本次优化中也包含了生产和消费性能的提升。
本文将会详解 4.9.3 版本中的性能优化点。在 4.9.3 版本中对延迟消息的优化已经在另一篇文章中详解。
本次和上次的性能优化主要由快手的黄理老师提交,在 ISSUE#3585 中集中记录。先来看一下本次性能优化的所有优化项
We have some performance improvements based on 4.9.2
- [Part A] eliminate reverse DNS lookup in MessageExt
- [Part B] Improve header encode/decode performance
- [Part B] Improve RocketMQSerializable performance with zero-copy
- [Part C] cache result for parseChannelRemoteAddr()
- [Part D] improve performance of createUniqID()
- [Part E] eliminate duplicated getNamespace() call when where is no namespace
- [Part F] eliminate regex match in topic/group name check
- [Part G] [Work in progress] support send batch message with different topic/queue
- [Part H] eliminate StringBuilder auto resize in PullRequestHoldService.buildKey() when topic length is greater than 14, this method called twice for each message.
- [Part I] Avoid unnecessary StringBuffer resizing and String Formatting
- [Part J] Use mmap buffer instead of FileChannel when writing consume queue and slave commit log, which greatly speed up consume tps.
- Part K move execution of notifyMessageArriving() from ReputMessageService thread to PullRequestHoldService thread.
These commits almost eliminate bad performance methods in the cpu flame graph in producer side.
下面来逐条剖析
性能优化
想要优化性能,首先需要找到 RocketMQ 的 Broker 在处理消息时性能损耗的点。使用火焰图可以清晰地看出当前耗时比较多的方法,从耗时较多的方法想办法入手优化,可以更大程度上提升性能。
具体的做法是开启 Broker 的火焰图采样,然后对其进行压测(同时生产和消费),然后观察其火焰图中方法的时间占用百分比,优化占用时间高且可以优化的地方。
A. 移除 MessageExt 中的反向 DNS 查找
eliminate reverse DNS lookup in MessageExt

inetAddress.getHostName() 方法中会有反向 DNS 查找,可能耗时较多。于是优化成没有反向 DNS 查找的 getHostString() 方法
(MessageExt#getBornHostNameString() 方法在一个异常流程中被调用,优化此方法其实对性能没有什么提升)
B.1. 优化 RocketMQ 通信协议 Header 解码性能
[Part B] Improve header encode/decode performance
(该提交未合入 4.9.3 版本,将于 4.9.4 版本发布)
PartB 有两个提交,其实作用不同,但是由于第二个提交依赖第一个所以只能放到一起
寻找优化点

RocketMQ 的通信协议定义了各种指令(消息发送、拉取等等)。其中 Header 是协议头,数据是序列化后的json。json 的每个 key 字段都是固定的,不同的通讯请求字段不一样,但是其中有一个 extField 是完全自定义的,每个指令都不一样。所有指令当前共用了一个通用的解析方法 RemotingCommand#decodeCommandCustomHeader,基于反射来解析和设置消息 Header。
// SendMessageRequestHeaderV2
{
"code":310,
"extFields":{
"f":"0",
"g":"1482158310125",
"d":"4",
"e":"0",
"b":"TopicTest",
"c":"TBW102",
"a":"please_rename_unique_group_name",
"j":"0",
"k":"false",
"h":"0",
"i":"TAGS\u0001TagA\u0002WAIT\u0001true\u0002"
},
"flag":0,
"language":"JAVA",
"opaque":206,
"version":79
}上面是一个发送消息的请求 Header。由于各种指令对应的 Header 的 extField 不同,这个解析 Header 方法内部大量使用反射来设置属性,效率很低。而且这个解码方法应用广泛,在 RocketMQ 网络通信时都会用到(如发送消息、拉取消息),所以很有优化的必要。
优化方案
优化的方案是尽量减少反射的使用,将常用的指令解码方法抽象出来。
这里引入了 FastCodesHeader 接口,只要实现这个接口,解码时就走具体的实现类而不用反射。

然后为生产消息和消费消息的协议单独实现解码方法,内部可以不用反射而是直接进行字段赋值,这样虽然繁琐但是执行速度最快。
// SendMessageRequestHeaderV2.java
@Override
public void decode(HashMap<String, String> fields) throws RemotingCommandException {
String str = getAndCheckNotNull(fields, "a");
if (str != null) {
a = str;
}
str = getAndCheckNotNull(fields, "b");
if (str != null) {
b = str;
}
str = getAndCheckNotNull(fields, "c");
if (str != null) {
c = str;
}
str = getAndCheckNotNull(fields, "d");
if (str != null) {
d = Integer.parseInt(str);
}
// ......
}
B.2. 提高编解码性能
[Part B] Improve RocketMQSerializable performance with zero-copy
(该提交未合入 4.9.3 版本,将于 4.9.4 版本发布)
改动背景

RocketMQ 的协议 Header 序列化协议有俩
- RemotingSerializable:内部用 fastjson 进行序列化反序列化,为当前版本使用的序列化协议。
- RocketMQSerializable:RocketMQ 实现的序列化协议,性能对比 fastjson 没有决定性优势,当前默认没有使用。
// RemotingCommand.java
private static SerializeType serializeTypeConfigInThisServer = SerializeType.JSON;
private byte[] headerEncode() {
this.makeCustomHeaderToNet();
if (SerializeType.ROCKETMQ == serializeTypeCurrentRPC) {
return RocketMQSerializable.rocketMQProtocolEncode(this);
} else {
return RemotingSerializable.encode(this);
}
}优化方法
这个提交优化了 RocketMQSerializable 的性能,具体的方法是消除了 RocketMQSerializable 中多余的拷贝和对象创建,使用 Netty 的 ByteBuf 替换 Java 的 ByteBuffer,性能更高。
- 对于写字符串:Netty 的
ByteBuf有直接 put 字符串的方法writeCharSequence(CharSequence sequence, Charset charset),少一次内存拷贝,效率更高。 - 对于写 Byte:Netty 的
writeByte(int value)传入一个int,Java 传入一个字节put(byte b)。当前 CPU 都是 32 位、64 位的,对 int 处理更高效。
(该改动要在 Producer 和 Consumer 设置使用 RocketMQ 序列化协议才能生效)
System.setProperty(RemotingCommand.SERIALIZE_TYPE_PROPERTY, SerializeType.ROCKETMQ.name());提交说明上的 zero-copy 说的不是操作系统层面上的零拷贝,而是对于 ByteBuf 的零拷贝。
在 NettyEncoder 中用 fastEncodeHeader 替换原来的 encodeHeader 方法,直接传入 ByteBuf 进行操作,不需要用 Java 的 ByteBuffer 中转一下,少了一次拷贝。

public void fastEncodeHeader(ByteBuf out) {
int bodySize = this.body != null ? this.body.length : 0;
int beginIndex = out.writerIndex();
// skip 8 bytes
out.writeLong(0);
int headerSize;
// 如果是 RocketMQ 序列化协议
if (SerializeType.ROCKETMQ == serializeTypeCurrentRPC) {
if (customHeader != null && !(customHeader instanceof FastCodesHeader)) {
this.makeCustomHeaderToNet();
}
// 调用 RocketMQ 序列化协议编码
headerSize = RocketMQSerializable.rocketMQProtocolEncode(this, out);
} else {
this.makeCustomHeaderToNet();
byte[] header = RemotingSerializable.encode(this);
headerSize = header.length;
out.writeBytes(header);
}
out.setInt(beginIndex, 4 + headerSize + bodySize);
out.setInt(beginIndex + 4, markProtocolType(headerSize, serializeTypeCurrentRPC));
}rocketMQProtocolEncode 中直接操作 ByteBuf,没有拷贝和新对象的创建。
public static int rocketMQProtocolEncode(RemotingCommand cmd, ByteBuf out) {
int beginIndex = out.writerIndex();
// int code(~32767)
out.writeShort(cmd.getCode());
// LanguageCode language
out.writeByte(cmd.getLanguage().getCode());
// int version(~32767)
out.writeShort(cmd.getVersion());
// int opaque
out.writeInt(cmd.getOpaque());
// int flag
out.writeInt(cmd.getFlag());
// String remark
String remark = cmd.getRemark();
if (remark != null && !remark.isEmpty()) {
writeStr(out, false, remark);
} else {
out.writeInt(0);
}
int mapLenIndex = out.writerIndex();
out.writeInt(0);
if (cmd.readCustomHeader() instanceof FastCodesHeader) {
((FastCodesHeader) cmd.readCustomHeader()).encode(out);
}
HashMap<String, String> map = cmd.getExtFields();
if (map != null && !map.isEmpty()) {
map.forEach((k, v) -> {
if (k != null && v != null) {
writeStr(out, true, k);
writeStr(out, false, v);
}
});
}
out.setInt(mapLenIndex, out.writerIndex() - mapLenIndex - 4);
return out.writerIndex() - beginIndex;
}C. 缓存 parseChannelRemoteAddr() 方法的结果
cache the result of parseChannelRemoteAddr()
寻找优化点
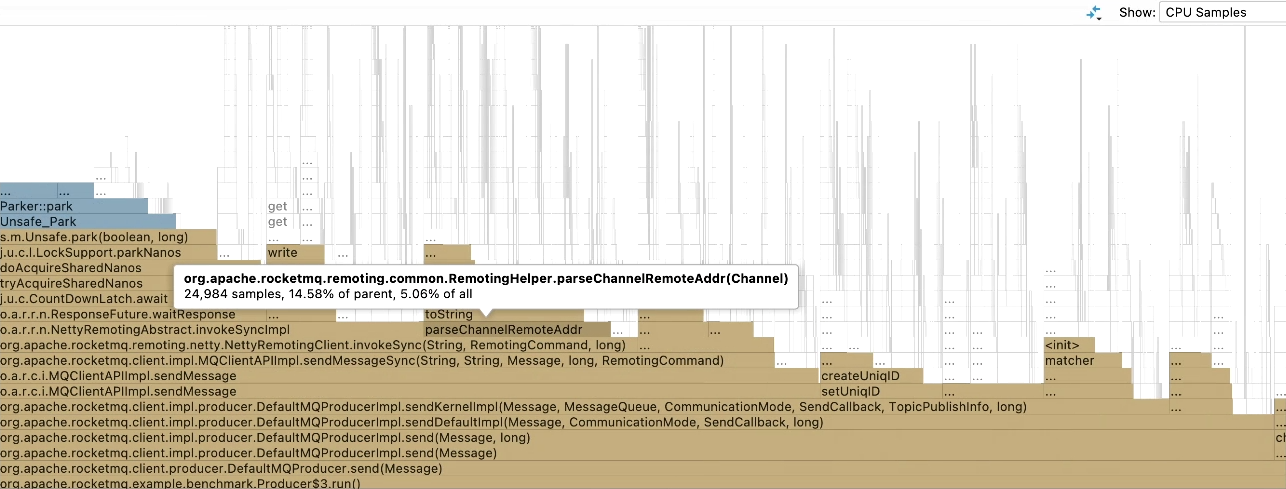
从火焰图中可以看到,parseChannelRemoteAddr() 这个方法占用了 5% 左右的总耗时。
这个方法被客户端在发送消息时调用,每次发送消息都会调用到这个方法,这也是他占用如此高 CPU 耗时百分比的原因。
那么这个方法做了什么?Netty 的 Channel 相当于一个 HTTP 连接,这个方法试图从 Channel 中获取远端的地址。
从火焰图上看出,该方法的 toString占用大量时间,其中主要包含了复杂的 String 拼接和处理方法。
那么想要优化这个方法最直接的方式就是——缓存其结果,避免多次调用。
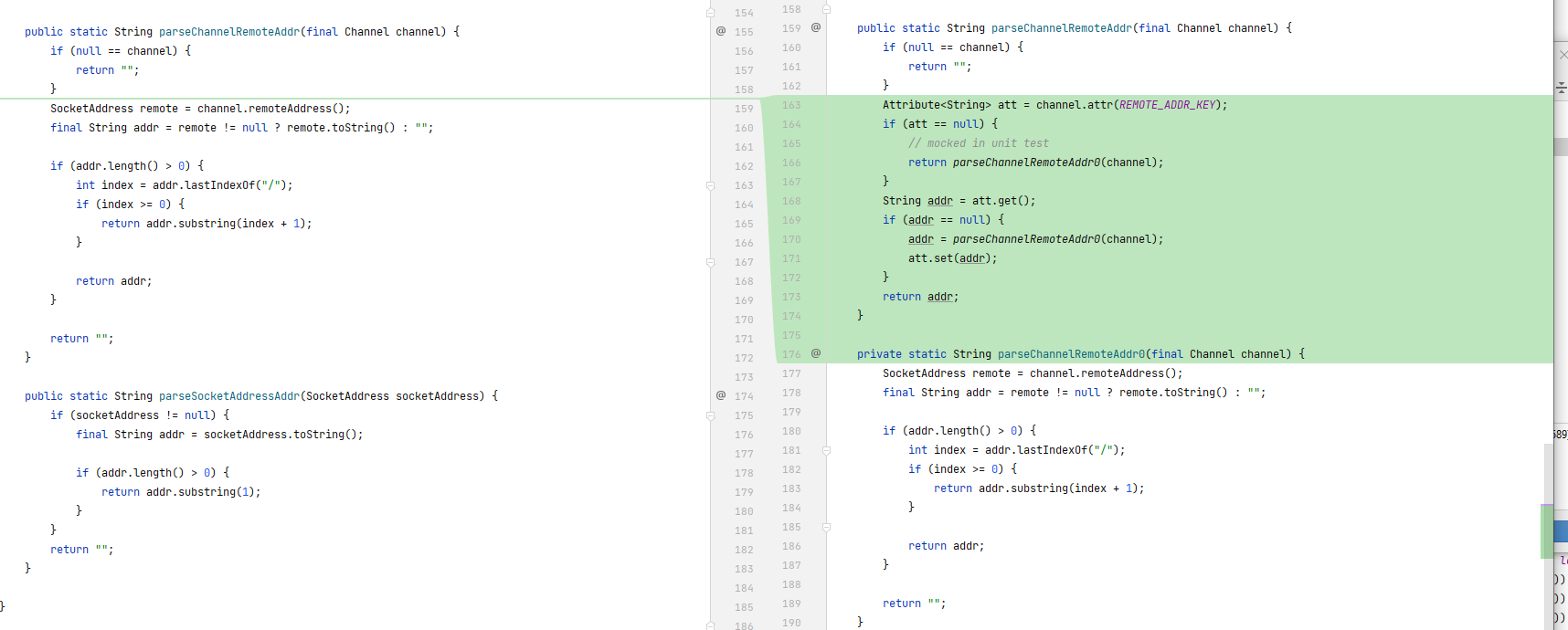
具体优化方法
Netty 提供了 AttributeKey 这个类,用于将 HTTP 连接的状态保存在 Channel 上。AttributeKey 相当于一个 Key-Value 对,用来存储状态。
要使用 AttributeKey,需要先初始化它的 Key,这样它就可以预先计算 Key 的 HashCode,查询该 Key 的时候效率就很高了。
private static final AttributeKey<String> REMOTE_ADDR_KEY = AttributeKey.valueOf("RemoteAddr");然后优化该方法,第一次调用该方法时尝试从 Channel 上获取属性RemoteAddr,如果获取不到,则调用原来的逻辑去获取并且缓存到该 AttributeKey 中。
修改过后在火焰图上已经几乎看不到该方法的用时。
D. 提升 createUniqID() 的性能
Improve performance of createUniqID().
寻找优化点
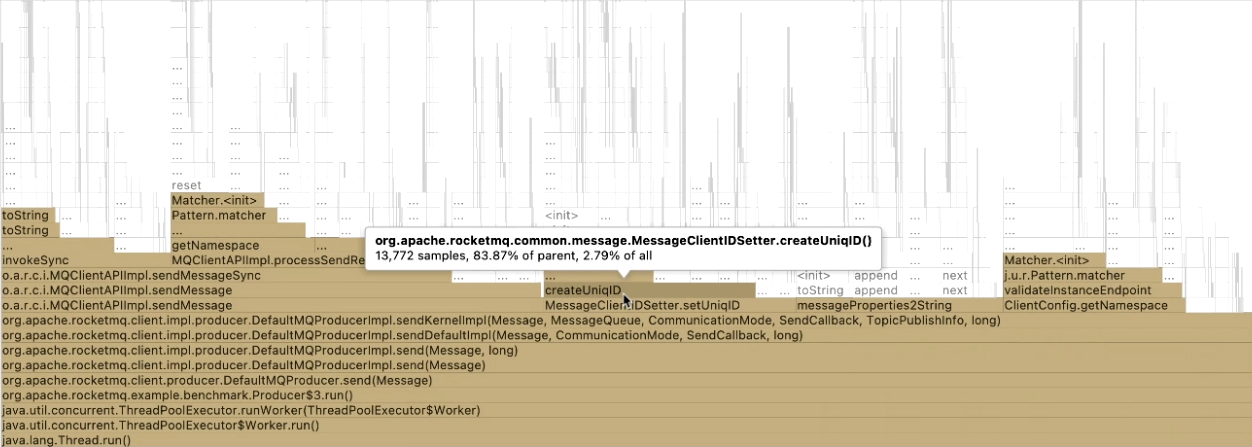
createUniqID() 这个方法用于创建消息的全局唯一 ID,在客户端每次发送消息时会调用,为每个消息创建全局唯一 ID。
RocketMQ 中包含两个消息 ID,分别为全局唯一 ID(UNIQUE_ID,消息发送时由客户端生产)和偏移量 ID(offsetMsgId,Broker 保存消息时由保存的偏移量生成),关于这两个 ID 的生成方法和使用可以看丁威老师的 RocketMQ msgId与offsetMsgId释疑。
原本生成全局 ID 的方法将客户端 IP、进程 ID 等信息组合计算生成一个字符串。方法逻辑里面包含了大量字符串和 ByteBuffer 操作,所以耗时较高。
优化方法
原先的方法实现中,每次调用都会创建 StringBuilder 、ByteBuffer、多个字符串……包含大量字符串操作,字符串操作的 CPU 耗时开销很大。
优化的方法主要通过字符数组运算替代字符串操作,避免多余的字符串对象产生;使用缓存,避免每次调用都重新计算和创建字符串对象。
将原来的
FIX_STRING字符串换成char[]字符数组,然后可以使用System.arraycopy替换原来的StringBuilder操作,避免多余对象产生。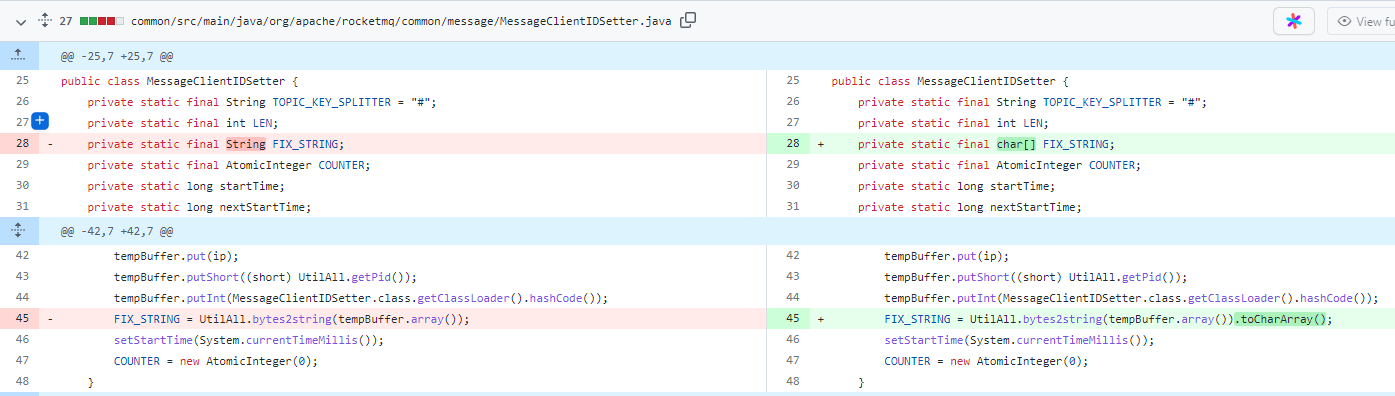
新增了
void writeInt(char[] buffer, int pos, int value)和writeShort(char[] buffer, int pos, int value)方法,用于写入字符串数组。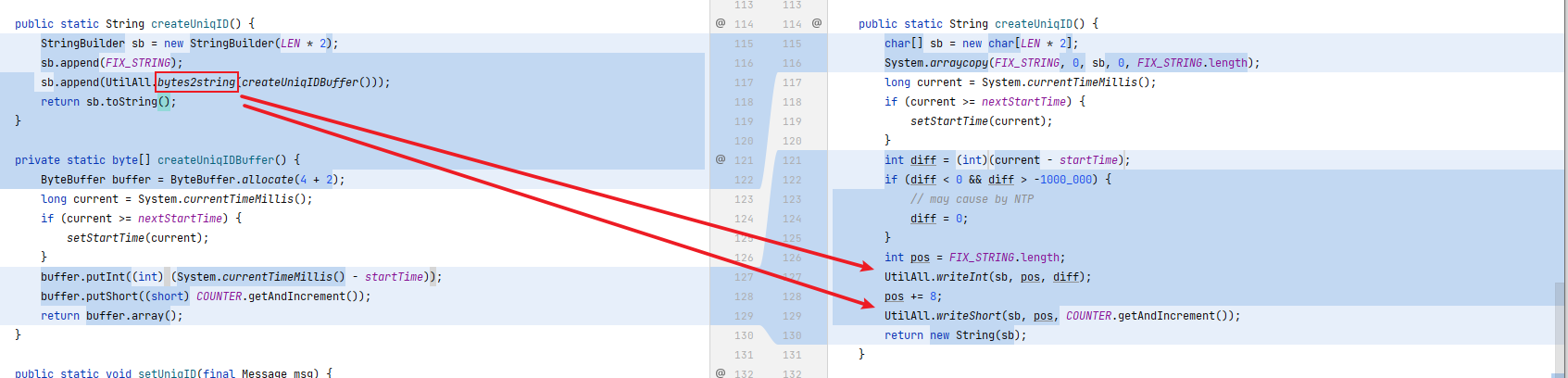
原先的
byte2string方法创建了char[]对象和String对象,并且 String 对象构造时需要拷贝一遍 char[]。优化之后完全没有新对象产生。
E. 当没有用到 namespace 时,避免其被多次调用
eliminate duplicated getNamespace() call when where is no namespace
寻找优化点
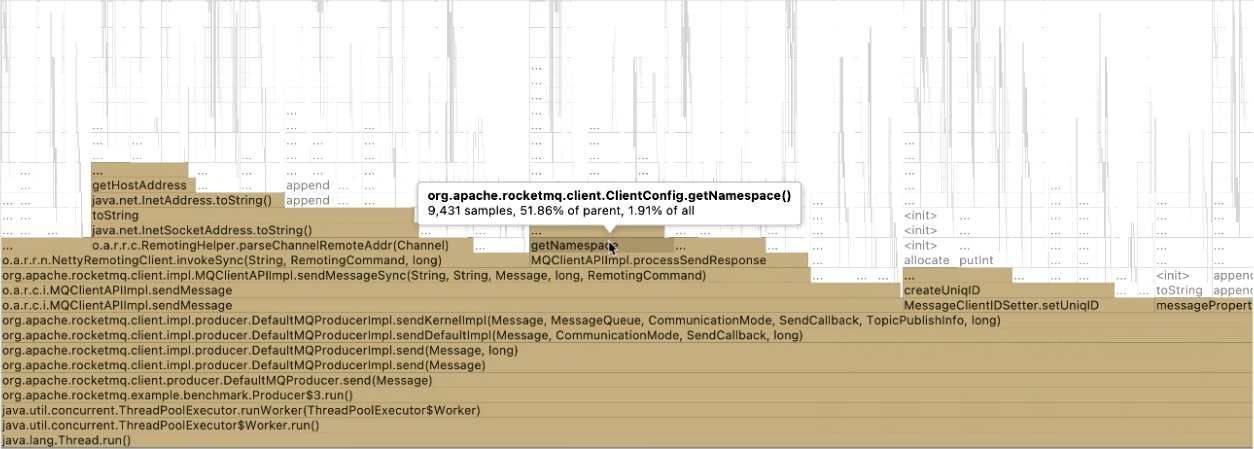
客户端在发送消息时会调用 getNamespace 方法。Namespace 功能在 RocketMQ 中用的很少,它在 4.5.1 版本中被引进,具体可以看 #1120。它的作用是引入 Namespace 的概念,相同名称的 Topic 如果 Namespace 不同,那么可以表示不同的 Topic。
优化方法
由于大部分情况下都用不到 Namespace,所以可以增加一个判断,如果不用 Namespace,就不走 Namespace 的一些验证和匹配逻辑。
具体的方法很简单,在 ClientConfig 设一个布尔值,用来表示 Namespace 是否初始化(是否使用),如果不使用,则跳过 getNamespace() 方法中后面的逻辑。
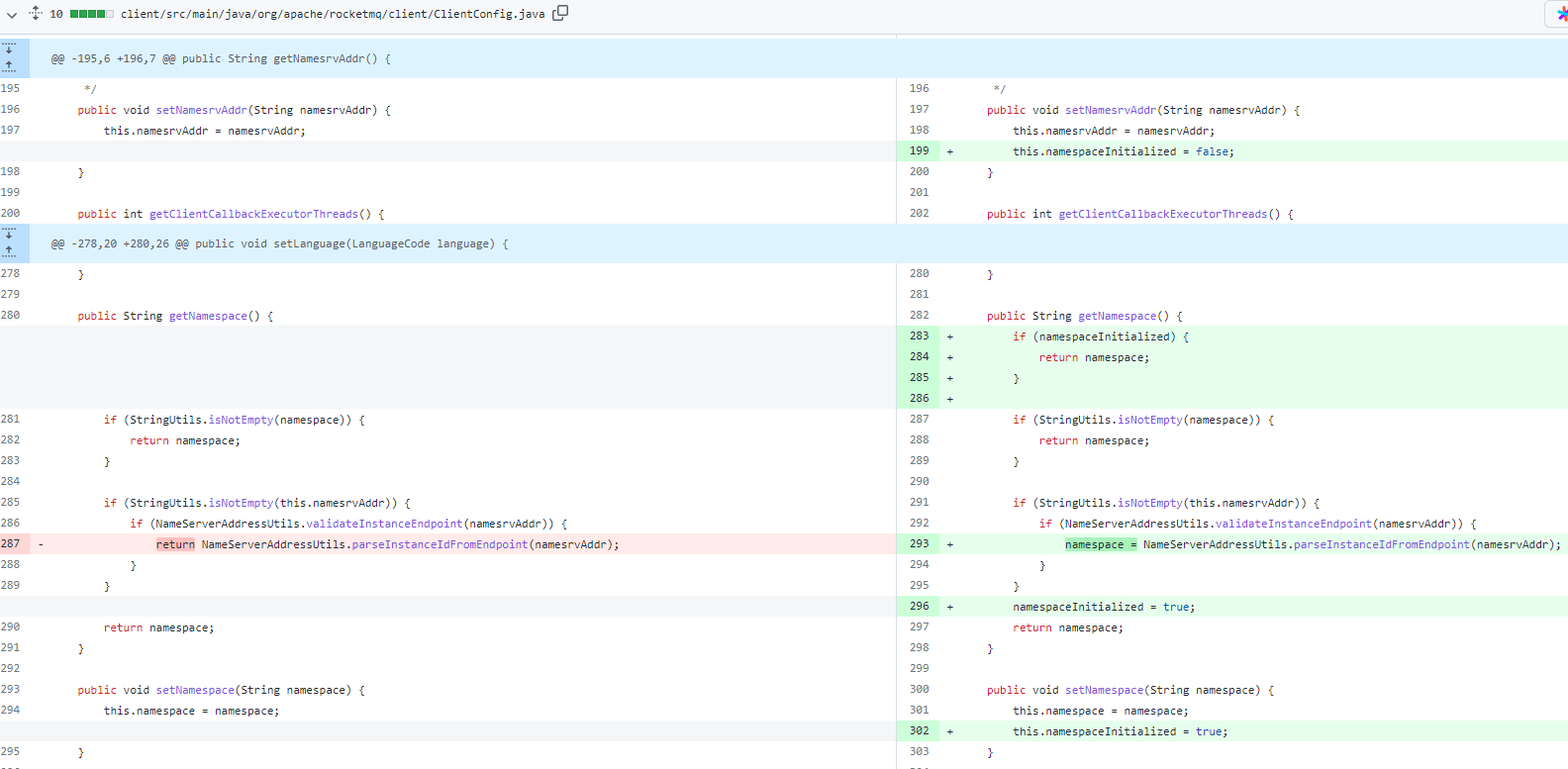
F. 去除 Topic/Group 名称的正则匹配检查
eliminate regex match in topic/group name check
每次发消息时,无论是客户端还是服务端都需要检查一次这个消息的 Topic/Group 是否合法。检查通过正则表达式匹配来进行,匹配规则很简单,就是检查这个名称的字符是否在一些字符范围内 String VALID_PATTERN_STR = "^[%|a-zA-Z0-9_-]+$"。那么就可以把这个正则表达式匹配给优化掉,使用字符来匹配,将正则匹配简化成位图查表的过程,优化性能。
因为正则表达式匹配的字符编码都在 128 范围内,所以先创建一个位图,大小为 128。
public static final boolean[] VALID_CHAR_BIT_MAP = new boolean[128];然后用位图匹配的方式替换正则匹配:检查的字符串的每一个字符是否在位图中。
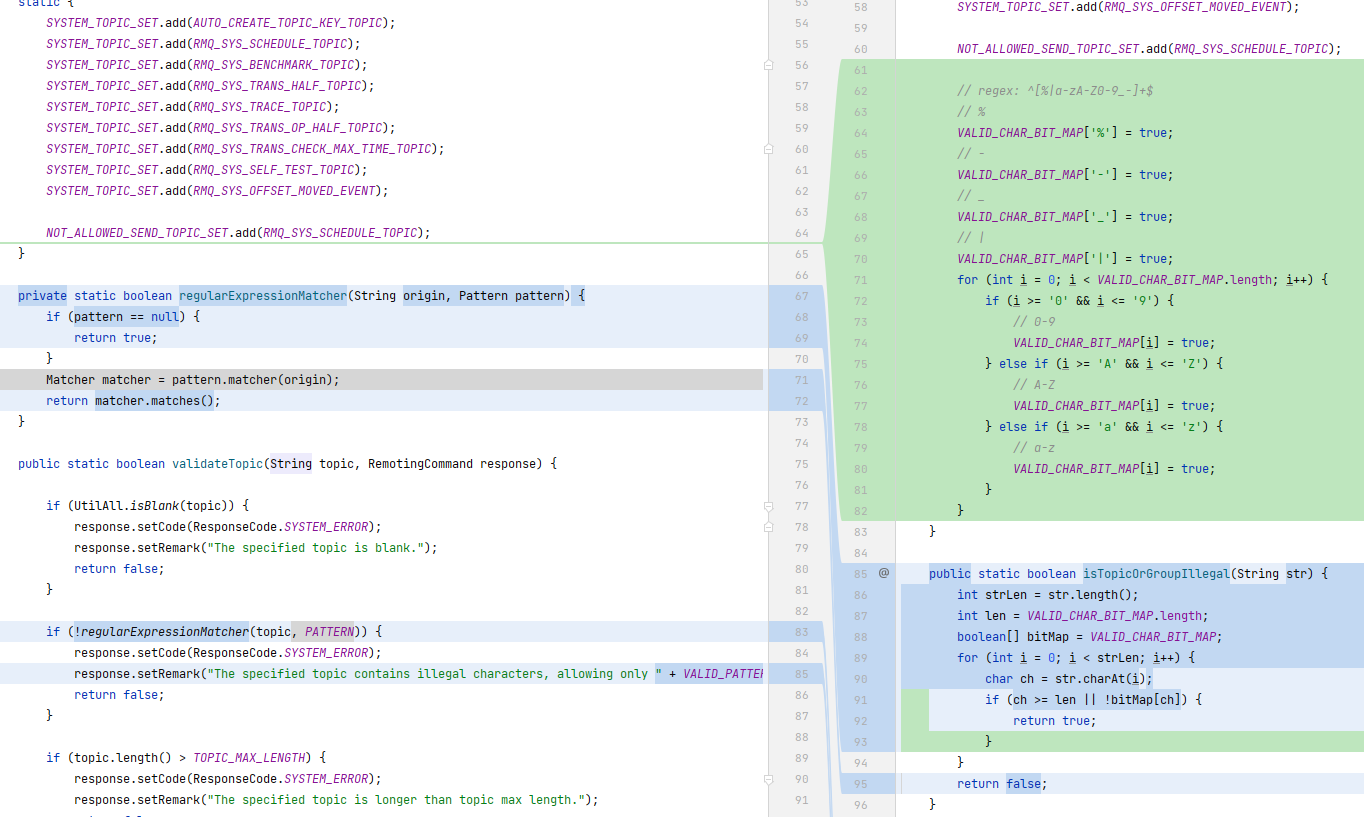
注意这里有一句
// 将位图从堆复制到栈里(本地变量),提高下面循环的变量访问速度
boolean[] bitMap = VALID_CHAR_BIT_MAP;将静态变量位图复制到局部变量中,这样做的用意是将堆中的变量复制到栈上(因为局部变量都位于栈),提高下面循环中访问该位图的速度。
- 栈上存储的数据,很大机会会被虚拟机分配至物理机器的高速寄存器中存储。因而读写效率比从堆内存中读写高很多。
- 栈上分配的数据,释放时只需要通过移动栈顶指针,就可以随着栈帧出栈而自动销毁。而堆内存的释放由垃圾回收器负责完成,这一过程中整理和回收内存都需要消耗更多的时间。
- 栈操作可以被 JIT 优化,得到 CPU 指令的加速
- 栈没有碎片,寻址间距短,可以被 CPU 预测行为
- 栈无需释放内存和进行随机寻址
G. 支持发送 batch 消息时支持不同的 Topic/Queue
support send batch message with different topic/queue
该改动依赖 Part.B ,还未提交 PR
H. 避免无谓的 StringBuilder 扩容
eliminate StringBuilder auto resize in PullRequestHoldService.buildKey() when topic length is greater than 14, this method called twice for each message
在 Broker 处理消息消费逻辑时,如果长轮询被启用,PullRequestHoldService#buildKey 每条消息会被调用 2 次。长轮询相关逻辑请移步之前的分析
该方法中初始化一个 StringBuilder,默认长度为 16。StringBuilder 会将 Topic 和 QueueId 进行拼接,如果 Topic 名称过长,会造成 StringBuilder 的扩容,内部包含字符串的拷贝。在比较坏的情况下,扩容可能会发生多次。
那么既然已经直到 Topic 的长度,为什么不在 StringBuilder 初始化的时候就设定长度呢?这就是这个优化的改动。

为什么这里是 toipic.length() + 5?因为一般 QueueId 不会超过 4 位数(一个 Topic 下面不会超过 9999 个队列),再加上一个分隔符,得到 5。
I. 避免无谓的 StringBuffer 扩容和 String 格式化
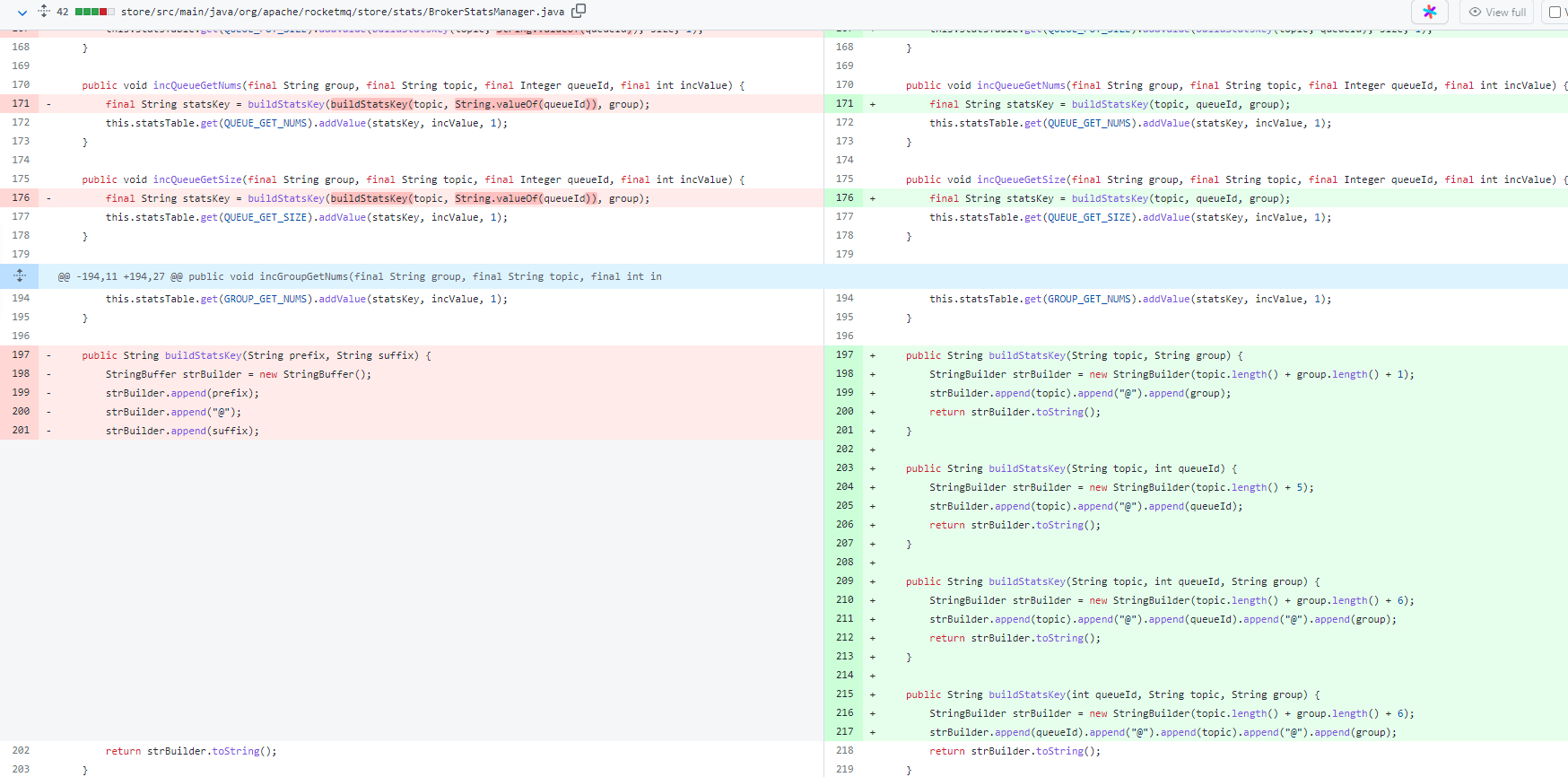
Avoid unnecessary StringBuffer resizing and String Formatting
寻找优化点

从火焰图上看出,在 Broker 处理消息消费消息请求时,有许多 String.format 方法开销非常大,这些方法都是数据统计用的,用来拼接数据统计字典的 Key。可以想办法进行优化。
优化方法
首先这里面有使用 StringBuffer 拼接的逻辑,也没有预先设定长度,存在扩容可能性。这里也没有多线程的情况,所以改成 StringBuilder,并且先计算好长度,避免扩容。
J. 在写 ConsumeQueue 和 从节点的 CommitLog 时,使用 MMap 而不是 FileChannel,提升消息消费 TPS
Use MappedByteBuffer instead of FileChannel to write consume queue and slave commitlog.
当消费的 Queue 数量特别多时( 600 个),消费的 TPS 跟不上。即在 Queue 比较少时(72 个)消费速度可以跟上生产速度(20W),但是当 Queue 比较多时,消费速度只有 7W。
这个修改可以提升 Queue 特别多时的消费速度。
- 72 个 Queue,消费速度从 7W 提升到 20W
- 600 个 Queue,消费速度从 7W 提升到 11W
寻找优化点
对 Broker 进行采样,发现创建消费索引的 reput 线程中有较大的耗时占比。

从火焰图上可以看出,FileChannel 写数据的耗时占比比较大,有没有办法来优化一下?
优化方法
我们知道 RocketMQ 写 CommitLog 是利用 MMap 来提升写入速度。但是在写 ConsumeQueue 时原先用的是 FileChannel 来写,于是这里改成也使用 MMap 来写入。
MappedFile.java
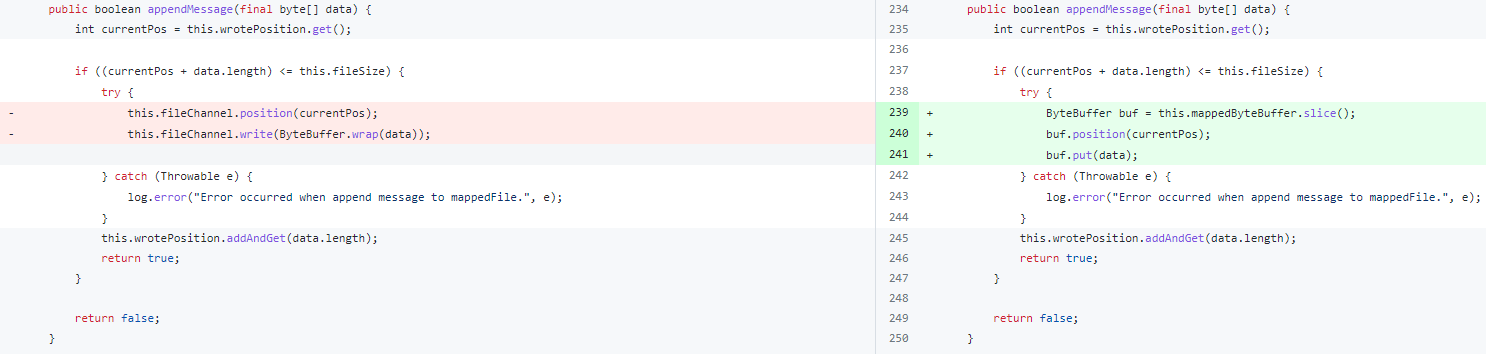
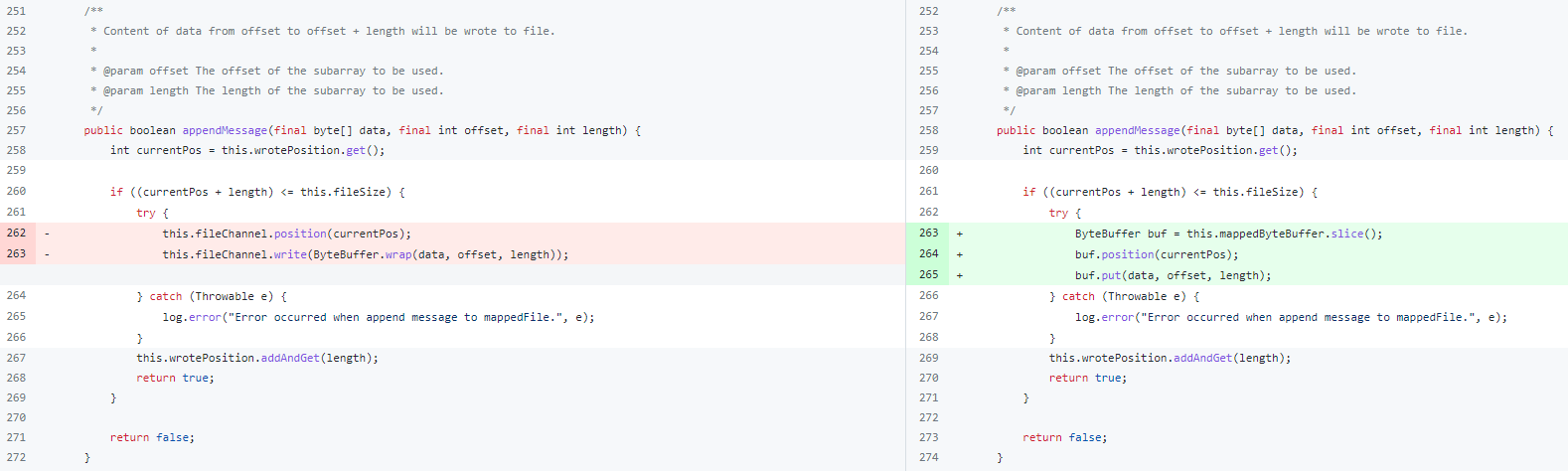
具体修改如上两图所示,这样修改之后会影响两个地方:ConsumeQueue (消费索引)的写入和 Slave 节点 CommitLog 的写入

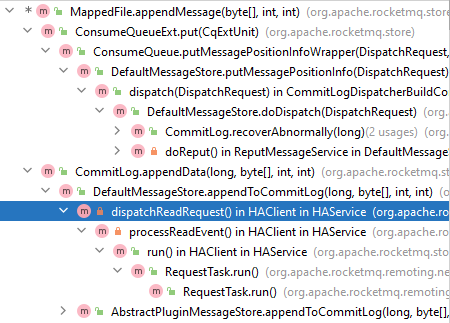
优化过后构建 ConsumeQueue 的时间占比大大减少

K. 将 notifyMessageArriving() 的调用从 ReputMessageService 线程移到 PullRequestHoldService 线程
move execution of notifyMessageArriving() from ReputMessageService thread to PullRequestHoldService thread
This commit speed up consume qps greatly, in our test up to 200,000 qps.
(该提交未合入 4.9.3 版本,当前仍未合入)
这一部分其实也是为了优化 Part.J 中所说的消费速度所做的另一个改动。经过 Part.J 的修改,600 队列下的消费 TPS 能够达到 10w(生产 20w)。这个修改将消费 TPS 提升到 20w。
寻找优化点

依然是通过查看火焰图的方法,查看到构造消费索引的方法中包含了 notifyMessageArriving() 这样一个方法,占用较大快的 CPU 时间。
这个方法具体在 轮询机制 这篇文章中有详细解释。消息消费的轮询机制指的是在 Push 消费时,如果没有新消息不会马上返回,而是挂起一段时间再重试查询。
notifyMessageArriving() 的作用是在收到消息时提醒消费者,有新消息来了可以消费了,这样消费者会马上解除挂起状态开始消费消息。
这里的优化点就是想办法把这个方法逻辑从构建消费索引的逻辑中抽离出去。
优化方案 1
首先想到的方法是将 notifyMessageArriving() 用一个单独的线程异步调用。于是在 PullRequestHoldService 里面采用生产-消费模式,启动了一个新的工作线程,将 notify 任务扔到一个队列中,让工作线程去处理,主线程直接返回。
工作线程每次从队列中 poll 一批任务,批量进行处理(1000 个)。经过这个改动,TPS 可以上升到 20w,但这带来了另一个问题——消息消费的延迟变高,达到 40+ms。
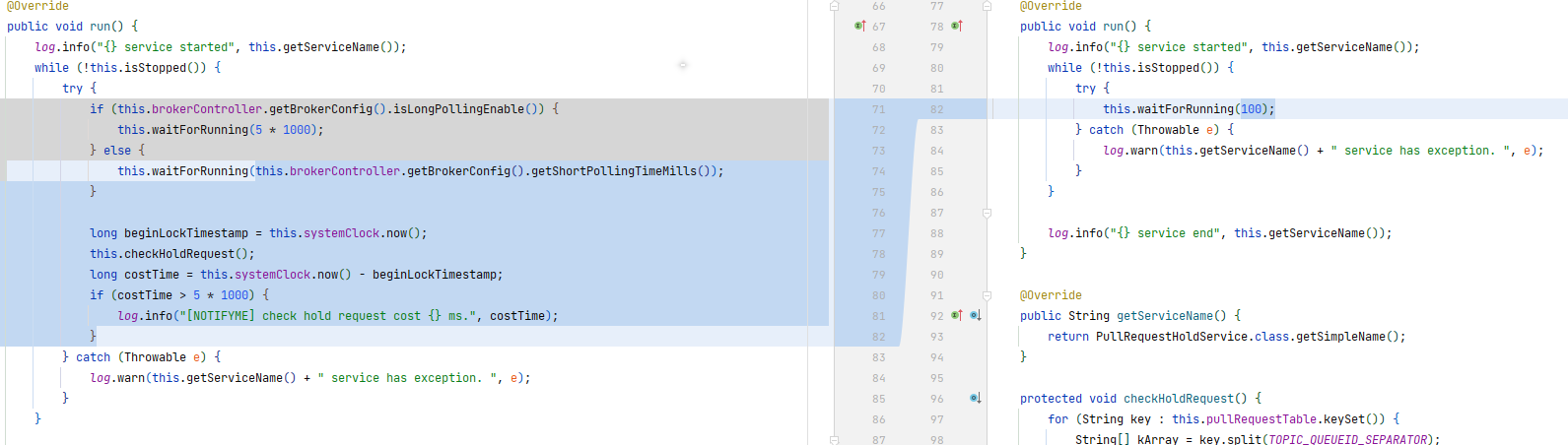
延迟变高的原因是—— RocketMQ 中 ServiceThread 工作线程的 wakeup() 和 waitForRunning() 是弱一致的,没有加锁而是采用 CAS 的方法,造成多线程情况下可能会等待直到超时。
public void wakeup() {
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
}
protected void waitForRunning(long interval) {
if (hasNotified.compareAndSet(true, false)) {
this.onWaitEnd();
return;
}
//entry to wait
waitPoint.reset();
try {
waitPoint.await(interval, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("Interrupted", e);
} finally {
hasNotified.set(false);
this.onWaitEnd();
}
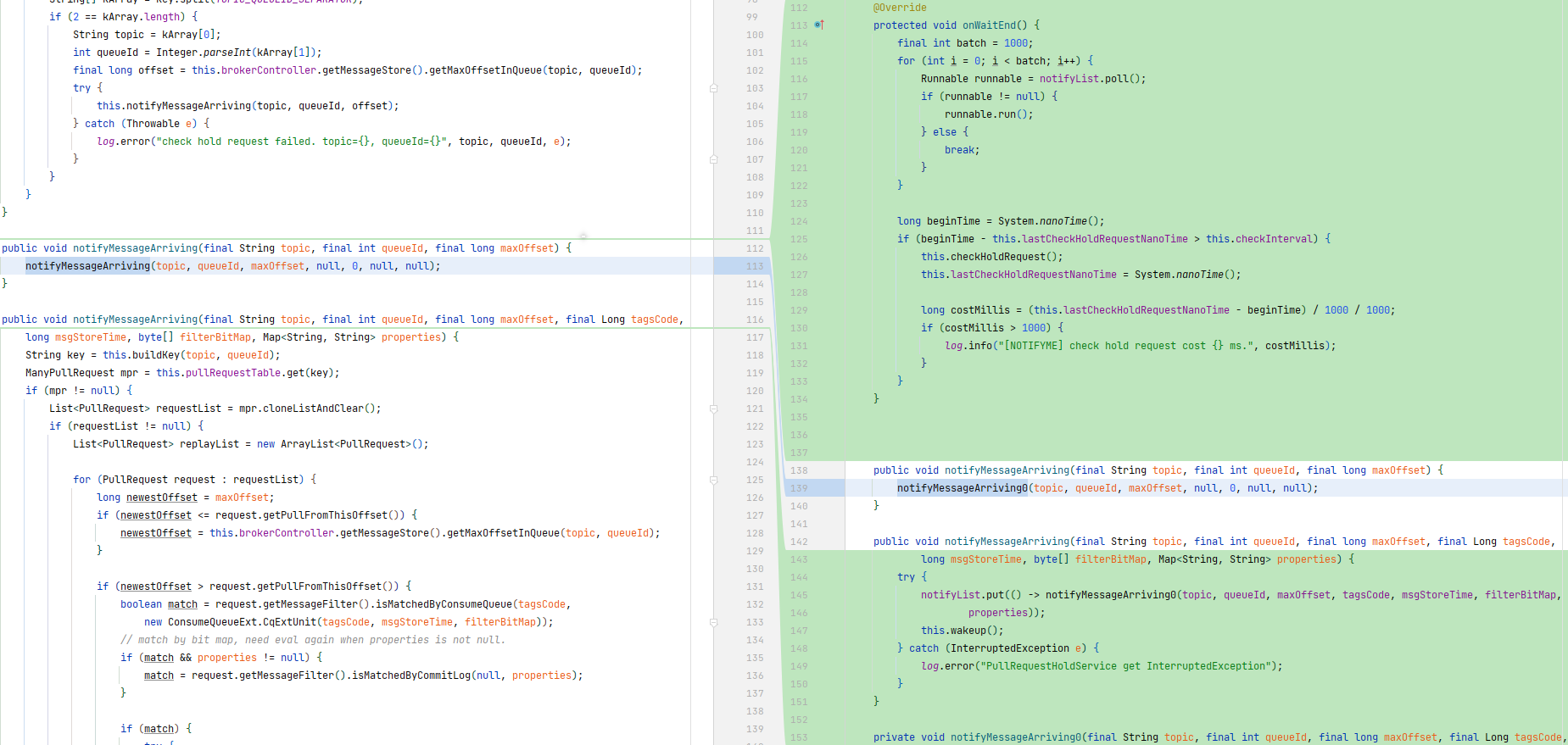
}优化方案 2
这个方案是实际提交的优化方案,方案比较复杂。主要的思想就是将原先的每条消息都通知一次转化为批通知,减少通知次数,减少通知开销以提升性能。
同样用生产-消费模式,为了同时保证低延迟和高吞吐引入了 PullNotifyQueue。生产者和消费者仍然是操作通知任务
生产者线程将消息 put 到队列中,消费者调用 drain 方法消费。
drain 方法中根据消费 TPS 做了判断
- 如果 TPS 小于阈值,则拉到一个任务马上进行处理
- 如果 TPS 大于阈值(默认 10w),批量拉任务进行通知。一批任务只需要一次 notify(原先每个消息都会通知一次)。此时会略微增加消费时延,换来的是消费性能大幅提升。
小结
本文介绍了 RocketMQ 4.9.3 版本中的性能优化,主要优化了消息生产的速度和大量队列情况下消息消费的速度。
优化的步骤是根据 CPU 耗时进行采样形成火焰图,观察火焰图中时间占比较高的方法进行针对性优化。
总结一下用到的优化方法主要有
- 代码硬编码属性,用代码复杂度换性能
- 对字符串和字节数组操作时减少创建和拷贝
- 对于要多次计算的操作,缓存其结果
- 锁内的操作尽量移动到锁外进行,提前进行计算或者用函数式接口懒加载
- 使用更高效的容器,如 Netty
ByteBuf - 使用容器时在初始化时指定长度,避免动态扩容
- 主流程上的分支操作,使用异步而非同步
- 对于磁盘 I/O,MMap 和 FileChannel 的选择,需要实际压测,大部分情况下 MMap 速度更快且更稳定;每次写入较大数据长度时(4k 左右) FileChannel 速度才更快。具体压测结果请看 java-io-benchmark
欢迎关注公众号【消息中间件】,更新消息中间件的源码解析和最新动态!

本文由博客一文多发平台 OpenWrite 发布!














 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









