






Kafka
1.集群模式的结构
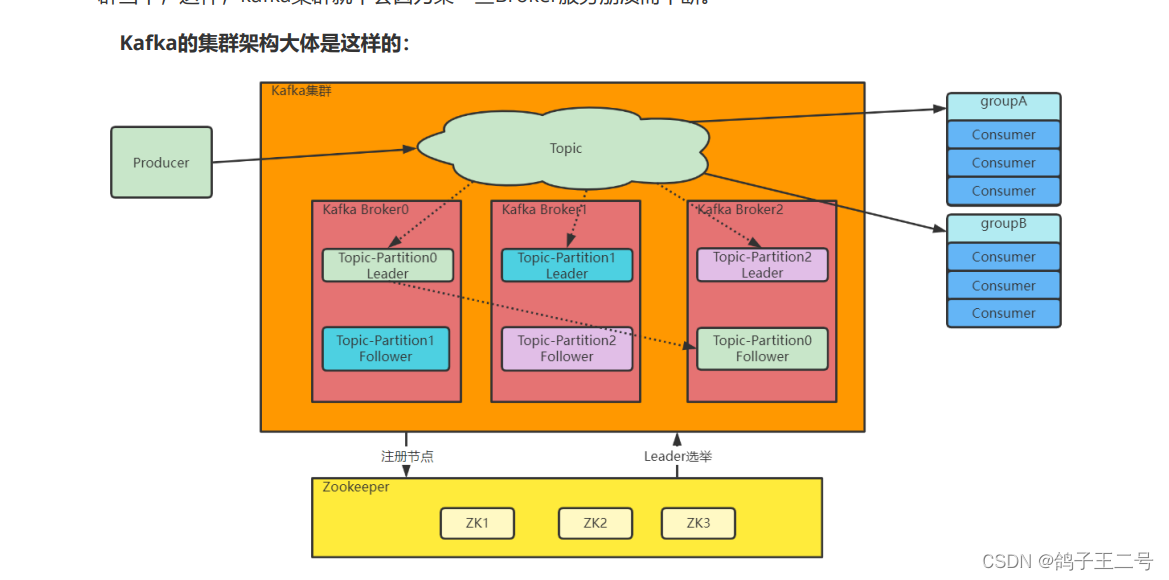
服务端中会有很多的topic,每个topic中会patitions分成多个区域,brokeid 代表的是节点id 也就是集群中启动的数量, 每个borke中都会存储相同数量的partition ,一个为领导节点 其他为副本节点; 副本节点主要是为了备份;主节点用于写入;
写入的流程
先会写入到领导节点 ,再去写入到follower节点进行备份

在这里插入图片描述
1、Topic是一个逻辑概念,Producer和Consumer通过Topic进行业务沟通。
2、Topic并不存储数据,Topic下的数据分为多组Partition,尽量平均的分散到各个Broker上。每组 Partition包含Topic下一部分的消息。每组Partition包含一个Leader Partition以及若干个Follower Partition 进行备份,每组Partition的个数称为备份因子 replica factor。
3、Producer将消息发送到对应的Partition上,然后Consumer通过Partition上的Offset偏移量,记录自己所属消费者组Group在当前Partition上消费消息的进度。
4、Producer发送给一个Topic的消息,会由Kafka推送给所有订阅了这个Topic的消费者组进行处理。但是 在每个消费者组内部,只会有一个消费者实例处理这一条消息。
5、最后,Kafka的Broker通过Zookeeper组成集群。然后在这些Broker中,需要选举产生一个担任 Controller角色的Broker。这个Controller的主要任务就是负责Topic的分配以及后续管理工作。
注意:Controller是由zookeeper选择出来的
2.客户端的属性
1.消费者分组消费机制
就是消费者可以被分配到一个消费者组中
public static final String GROUP_ID_CONFIG = "group.id";

当消息发送给topic后,topic会将消息发送给订阅了该topic的消费者组中,消费者组中的消费者去消费这一组消息,不同的消费者组会重复的消费同一份消息;
消费者组会记录每一个partition的offset值;
Offset偏移量,需要消费者处理完成后主动向Kafka的Broker提交。提交完成后,Broker就会更新消 费进度,表示这个消息已经被这个消费者组处理完了。但是如果消费者没有提交Offset,Broker就会认为这 个消息还没有被处理过,就会重新往对应的消费者组进行推送,不过这次,一般会尽量推送给同一个消费者 组当中的其他消费者实例。
一个partition只能被一个消费者消费,多个消费者的话会导致offset错乱;
消费者来提交offset,有三种选择
ConsumerConfig.AUTO_OFFSET_RESEWT_CONFIG :
当Server端没有对应的Offset时,要如何处理。
可选项:
earliest: 自动设置为当前最早的offset
latest:自动设置为当前最晚的offset
none: 如果消费者组对应的offset找不到,就向Consumer抛异常。 其他选项: 向Consumer抛异常。
消费者提交offset有异步和同步两钟方法:
1.异步提交:就是一边处理业务一边提交offset 但是如果信息没有消费成功,但是提交了offset 会导致消息丢失
2.同步提交:业务处理完成后,再提交offset,这样会导致处理消息的效率很慢
2.拦截器机制
无论消费者或者是生产者都可以配置拦截器
public static final String INTERCEPTOR_CLASSES_CONFIG = "interceptor.classes";
简单拿消费者的拦截器做说明
@Component
public class MyInterceptor implements ConsumerInterceptor<String,String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> consumerRecords) {
return consumerRecords;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> map) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
properties:
enable.idempotence: true
yaml里配置一下就可以给消费者添加拦截器;
拦截器主要可以做一些统一的日志管理;
3.序列化
因为需要用到网络传输,所以必须要序列化,进行内部的通信;就是对key - value 分别做序列化和反序列化
kafka自带一些序列化机制;
spring:
kafka:
bootstrap-servers: 47.120.41.107:9092
producer:
retries: 1
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: all
properties:
enable.idempotence: true
consumer:
auto-commit-interval: 1S
auto-offset-reset: latest
enable-auto-commit: true
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
group-id: defaultConsumerGroup
profiles:
active: dev
这的的StringSerializer 和 StringDeserializer 就是序列化 和反序列化;
也可以自定义序列化 ;
encode可以转化为byte数组
decode可以根据设置长度值进行反序列化;
4.路由机制
路由机制就是可以有很多策略决定消费者组中的消费者可以如何选择partitions进行消费;
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG ="partition.assignment.strategy";
- range策略: 比如一个Topic有10个Partiton(partition 0~9) 一个消费者组下有三个 Consumer(consumer13)。Range策略就会将分区03分给一个Consumer,4~6给一个Consumer, 7~9给一个Consumer。
- round-robin策略:轮询分配策略,可以理解为在Consumer中一个一个轮流分配分区。比如0,3,6, 9分区给一个Consumer,1,4,7分区给一个Consumer,然后2,5,8给一个Consumer
- sticky策略:粘性策略。这个策略有两个原则: 1、在开始分区时,尽量保持分区的分配均匀。比如按照Range策略分(这一步实际上是随机的)。 2、分区的分配尽可能的与上一次分配的保持一致。比如在range分区的情况下,第三个 Consumer的服务宕机了,那么按照sticky策略,就会保持consumer1和consumer2原有的分区 分配情况。然后将consumer3分配的7~9分区尽量平均的分配到另外两个consumer上。这种粘性 策略可以很好的保持Consumer的数据稳定性。
三种策略可以选择;
也可以通过
//获取所有的Partition信息。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic)
获取到所有的partitions后来,自定义选择要消费的partition;
5.生产者的缓存机制
Kafka生产者为了避免高并发请求对服务端造成过大压力,每次发消息时并不是一条一条发往服务端,而 是增加了一个高速缓存,将消息集中到缓存后,批量进行发送。这种缓存机制也是高并发处理时非常常用的 一种机制
//1.记录累加器
int batchSize = Math.max(1, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG));
this.accumulator = new
RecordAccumulator(logContext,batchSize,this.compressionType,lingerMs(config),retryBa
ckoffMs,deliveryTimeoutMs,
partitionerConfig,metrics,PRODUCER_METRIC_GROUP_NAME,time,apiVersions,transactionMan
ager,new BufferPool(this.totalMemorySize, batchSize, metrics, time,
PRODUCER_METRIC_GROUP_NAME));
//2. 数据发送线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
其中RecordAccumulator,就是Kafka生产者的消息累加器。KafkaProducer要发送的消息都会在 ReocrdAccumulator中缓存起来,然后再分批发送给kafka broker。
在RecordAccumulator中,会针对每一个Partition,维护一个Deque双端队列,这些Dequeue队列基本 上是和Kafka服务端的Topic下的Partition对应的。每个Dequeue里会放入若干个ProducerBatch数据。 KafkaProducer每次发送的消息,都会根据key分配到对应的Deque队列中。然后每个消息都会保存在这些 队列中的某一个ProducerBatch中。而消息分发的规则,就是由上面的Partitioner组件完成的。
会调用send线程完成发送


Sender也并不是一次就把RecordAccumulator中缓存的所有消息都发送出去,而是每次只拿一部分消 息。他只获取RecordAccumulator中缓存内容达到BATCH_SIZE_CONFIG大小的ProducerBatch消息。当 然,如果消息比较少,ProducerBatch中的消息大小长期达不到BATCH_SIZE_CONFIG的话,Sender也不会 一直等待。最多等待LINGER_MS_CONFIG时长。然后就会将ProducerBatch中的消息读取出来。
6.ack机制
就是producer将消息发送给服务器,等待服务器回ack
- acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。吞吐量是最高 的,但是数据安全性是最低的。
- acks=all or -1,生产者需要等Broker端的所有Partiton(Leader Partition以及其对应的Follower Partition都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞 吐量是最低的。
- acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回 结果。
7.幂等性问题
kafka内部增加了一些概念
- PID:每个新的Producer在初始化的过程中就会被分配一个唯一的PID。这个PID对用户是不可见的。
- Sequence Numer: 对于每个PID,这个Producer针对Partition会维护一个sequenceNumber。这是一 个从0开始单调递增的数字。当Producer要往同一个Partition发送消息时,这个Sequence Number就 会加1。然后会随着消息一起发往Broker。
- Broker端则会针对每个维护一个序列号(SN),只有当对应的SequenceNumber = SN+1时,Broker才会接收消息,同时将SN更新为SN+1。否则,SequenceNumber过小就认为消息已 经写入了,不需要再重复写入。而如果SequenceNumber过大,就会认为中间可能有数据丢失了。对 生产者就会抛出一个OutOfOrderSequenceException。
简单来说 就是根据发送消息的seq 和 pid 去对比partition中的pid 和sn 的值,而去判断是否消费过了;

整体的大致流程

3.zookeeper中kafka
kafka中许多元数据都会被存入到zookeeper中;zookeeper跨域监控集群的情况 ,监控brokers ids的情况

1.Controller Broker选举机制
所有的节点都会去注册zookeeper中的controller ,谁先注册谁就是controller;如果这个broke宕机了,那么zookeeper会自动删除,重新让一个活的broker去注注册controller;
controller的作用是:
- 监听Zookeeper中的/brokers/ids节点,感知Broker增减变化。
- 监听/brokers/topics,感知topic以及对应的partition的增减变化。
- 监听/admin/delete_topic节点,处理删除topic的动作。
- 另外,Controller还需要负责将元数据推送给其他Broker。
2.leader partition选择机制
有一些基础的概念:
AR: Assigned Repllicas。 表示Kafka分区中的所有副本(存活的和不存活的)
ISR: 表示在所有AR中,服务正常,保持与Leader同步的Follower集合。如果Follower长时间没有向 Leader发送通信请求(超时时间由replica.lag.time.max.ms参数设定,默认30S),那么这个Follower 就会被提出ISR中。(在老版本的Kafka中,还会考虑Partition与Leader Partition之间同步的消息差值, 大于参数replica.lag.max.messages条就会被移除ISR。现在版本已经移除了这个参数。)
OSR:表示从ISR中踢出的节点。记录的是那些服务有问题,延迟过多的副本。
比图:

kafka中有高效的选举机制:
会选择Replicas 中的第一个当作leader节点 但前提是这个节点存在isr中;
如果有一些broker节点宕机了,那么会触发kafka的自动平衡机制:
在一组Partiton中,Leader Partition通常是比较繁忙的节点,因为他要负责与客户端的数据交互,以及向 Follower同步数据。默认情况下,Kafka会尽量将Leader Partition分配到不同的Broker节点上,用以保证 整个集群的性能压力能够比较平均。 但是,经过Leader Partition选举后,这种平衡就有可能会被打破,让Leader Partition过多的集中到同一 个Broker上。这样,这个Broker的压力就会明显高于其他Broker,从而影响到集群的整体性能。 为此,Kafka设计了Leader Partition自动平衡机制,当发现Leader分配不均衡时,自动进行Leader Partition调整。 Kafka在进行Leader Partition自平衡时的逻辑是这样的:他会认为AR当中的第一个节点就应该是Leader 节点。这种选举结果成为preferred election 理想选举结果。Controller会定期检测集群的Partition平衡情 况,在开始检测时,Controller会依次检查所有的Broker。当发现这个Broker上的不平衡的Partition比例高 于leader.imbalance.per.broker.percentage阈值时,就会触发一次Leader Partiton的自平衡。
#1 自平衡开关。默认true
auto.leader.rebalance.enable
Enables auto leader balancing. A background thread checks the distribution of
partition leaders at regular intervals, configurable by
`leader.imbalance.check.interval.seconds`. If the leader imbalance exceeds
`leader.imbalance.per.broker.percentage`, leader rebalance to the preferred leader
for partitions is triggered.
Type: boolean
Default: true
Valid Values:
Importance: high
Update Mode: read-only
#2 自平衡扫描间隔
leader.imbalance.check.interval.seconds
The frequency with which the partition rebalance check is triggered by the
controller
Type: long
Default: 300
Valid Values: [1,...]
Importance: high
Update Mode: read-only
#3 自平衡触发比例
leader.imbalance.per.broker.percentage
The ratio of leader imbalance allowed per broker. The controller would trigger a
leader balance if it goes above this value per broker. The value is specified in
percentage.
Type: int
Default: 10
Valid Values:
Importance: high
Update Mode: read-only
自动平衡机制的一些参数;
3.kafka的可靠性 故障恢复
内部维护一个hw ; hw的意义就是代表了哪一些消息是被消费过的;

内部维护一个hw ; hw的意义就是代表了哪一些消息是被消费过的;
消息会先发给leader ,在由leader发给follow ; 每个副本都会维护一个hw ,因为是依靠网络传输,可能会导致每个副本中的hw的值不一致,
但会以leader为主;
如果leader发生了宕机,那么会选举follow当选新的leader,但是follow的leo 会比 原来的leader中leo要小,那么这一段的数据就会丢失















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









