






主要集合类
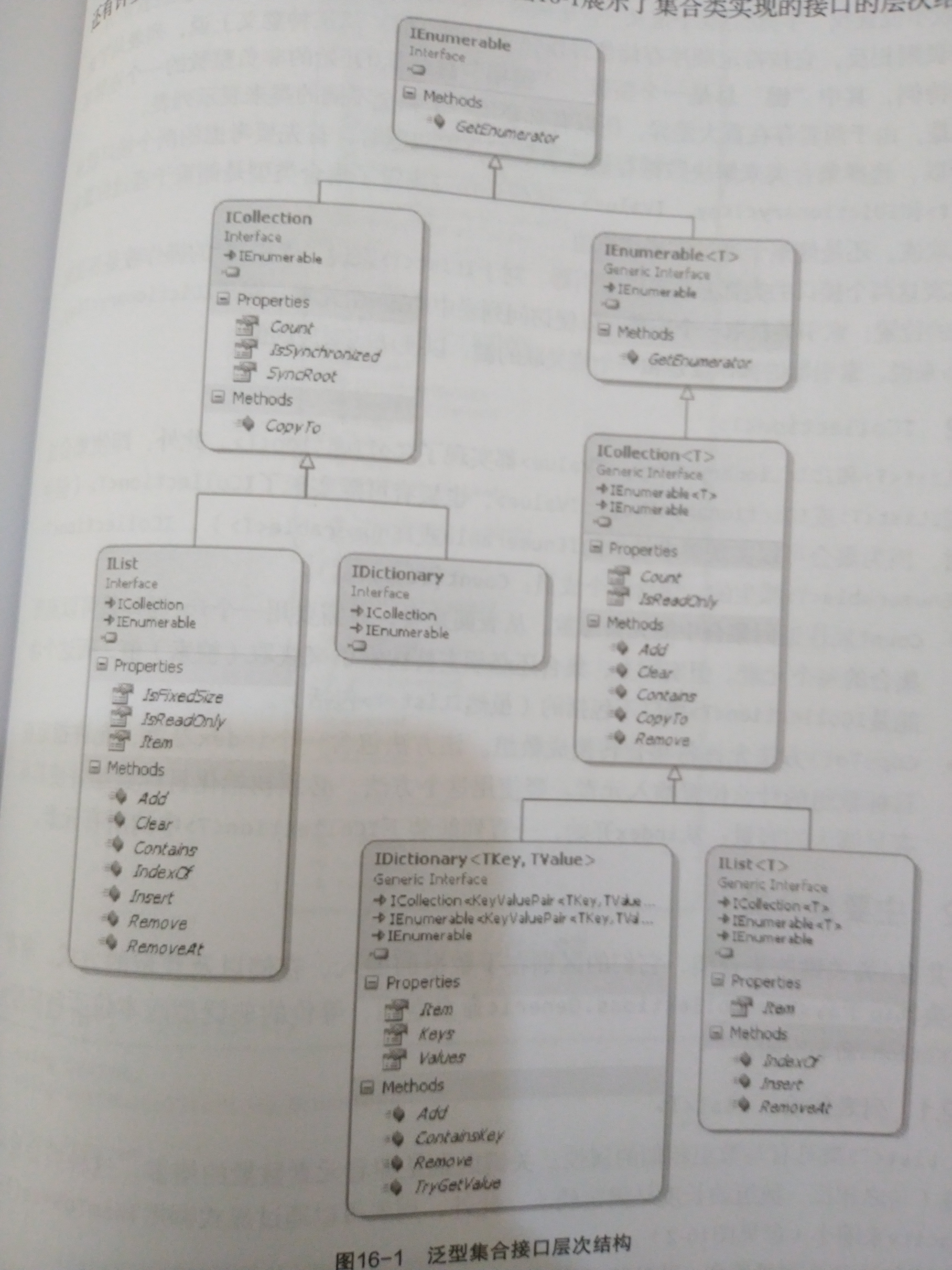
接口层级接口结构
列表集合:List<T>
自定义集合排序
每个元素都可以通过索引来单独访问,List<T>是有序集合,在调用自带方法 Sort()之后会是元素按照字母顺序重新排序。
如果元素类型实现了泛型 IComparable<T>或者非泛型接口 IComparable排序算法就默认用它来决定排序的顺序。
如果没有实现,或者是默认逻辑不符合要求,可以调用 List<T>.Sort()的重载版本,他获取一个 IComparaer<T>作为实参
IComparable<T> 和IComparaer<T>的区别在于,前者知道如何将我自己和同一类型的另一实例进行比较,后者知道如何比较给定类型的两个实例
实现排序逻辑的时候要保证全序,确保相同数据的排列组合会产生一致的结果,比如判断可传递,与自身相等…
值得注意的是,在判断中不能有一元素为null就返回相等,否则两个非null元素都等于null却互不相等,null在判断符左右两侧要返回不同的值
字典:Dictionary<TKey,TValue>
var colorMap = new Dictionary<string, ConsoleColor>{
["Error"] = ConsoleColor.Red;
["Warning"] = ConsoleColor.Yellow;
}
//插入的两种方式,后面一种还可以用于更改
colorMap.Add("Information", ConsoleColor.Green);
colorMap["Verbose"] = ConsoleColor.White;
//foreach遍历字典
private static void Print( IEnumerable<KeyValuePair<string, ConsoleColor>> items){
foreach(KeyValuePair<string, ConsoleColor> item in items){
Console.WriteLine(item.Key);
}
}
同样,字典的元素顺序也不是确定的,不要对其依赖
字典为了判断是否与现有的键匹配,如果字典的值是自定义的,就要实现判断逻辑,此外还要实现一个返回“散列码”的方法来快速索引
索引器
数组,字典和列表都提供了索引器,可以定义自己的索引器
//定义了一个只包含两个元素的集合
public enum PairItem{
First,
Second
}
public struct Pair<T> {
public Pair(T first, Tsecond){
First = first;
Second = second;
}
public T First { get; }
public T Second { get; }
public T this[PairItem index]{
get{
switch(index){
case PairItem.First:
return First;
case PairItem.Second:
return Second;
default:
throw new NotImplementedException(
string.Format("The enum {0} has not been implemented"), index.ToString())
);
}
}
}
//和属性的声明很相似,但是用关键词this,后面包含[参数列表],可以有多个参数
//如果集合为空,最好不要返回null,
//而是返回一个不包含任何数据项的集合实例,可以使用Enumerable.Empty<T>()来生成
//这样不用在遍历集合元素之前检查null值
}
迭代器
foreach循环
确定了第一个元素,下一个元素以及最后一个元素就不需要知道元素总数
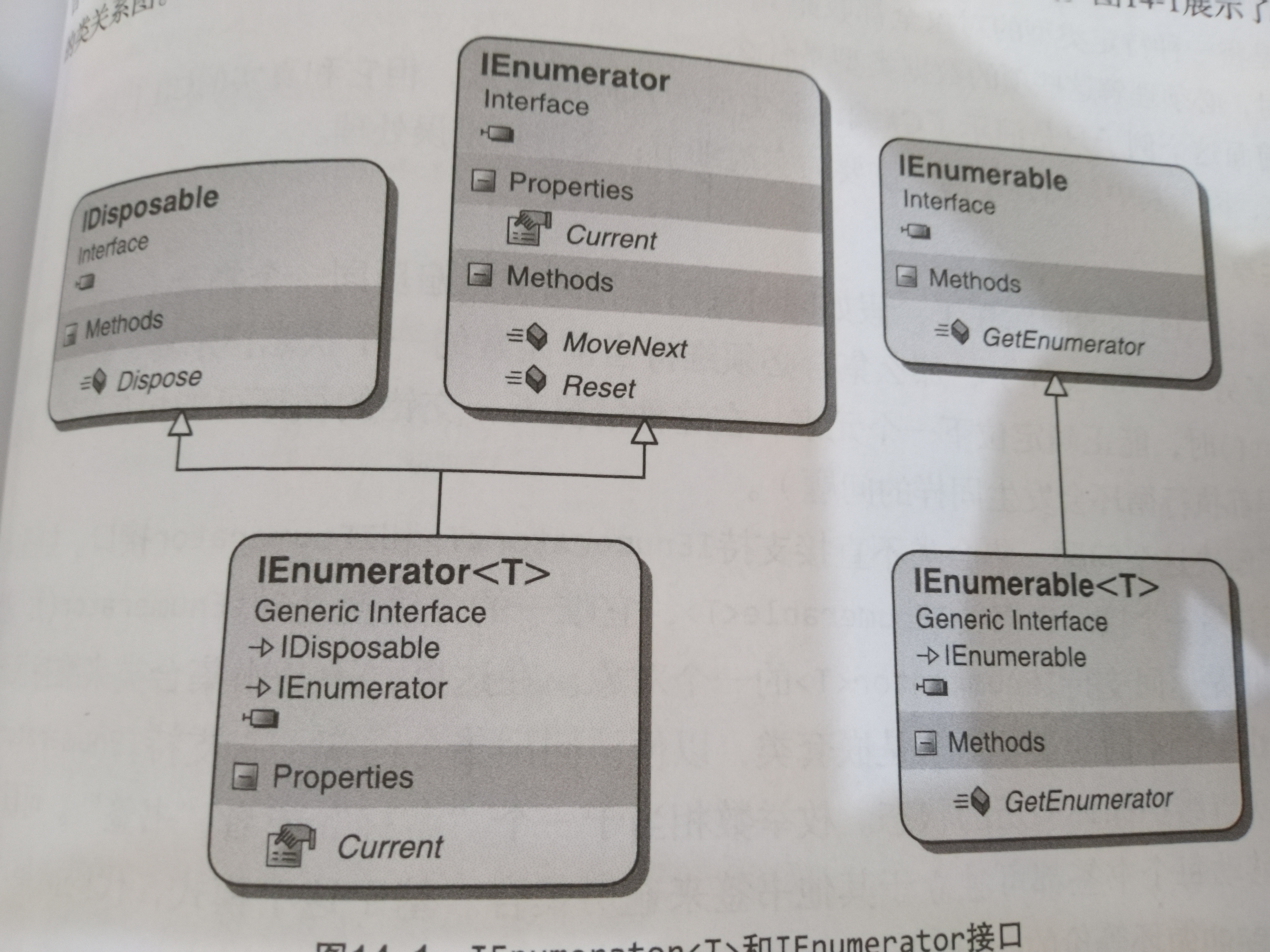
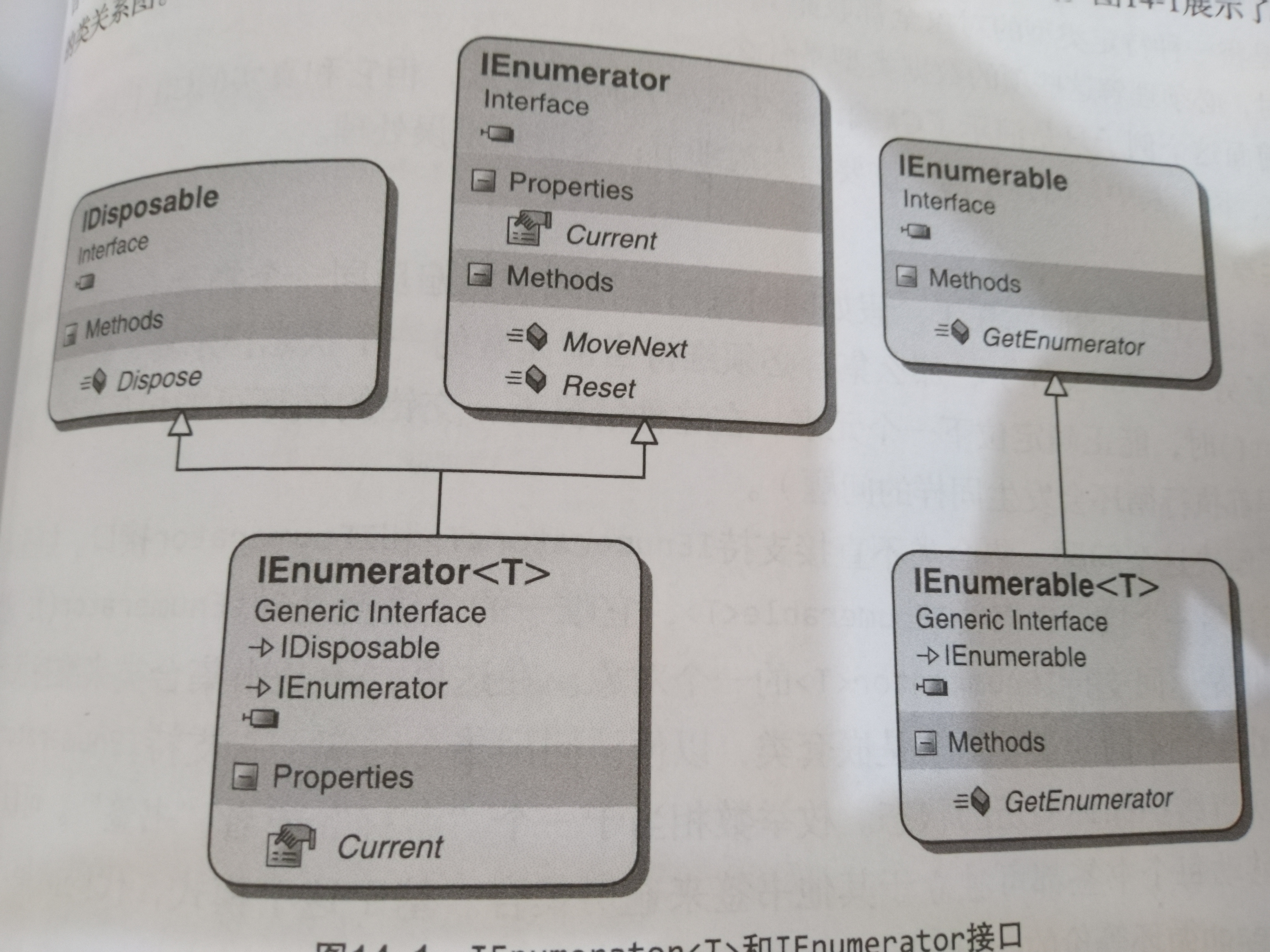
重新来看这幅图,IEnumerable的唯一方法是 GetEnumerator()作用是返回支持IEnumerator<T>的一个对象,相当于一个书签来使循环交错遍历一个集合时不相互干扰。
foreach用while的等效代码如下
Stack<int> stack = new Stack<int>();
int number;
Stack<int>.Enumerator enumerator;
enumerator = stack.GetEnumerator();
while(enumerator.MoveNext()){
number = enumerator.Current;
Console.WriteLine(number);
}
从代码我们也能够看出为什么编译器禁止对number进行赋值,因为他只是局部变量,并不会改变集合元素本身。
迭代器生成值
迭代器类似于函数,但他不是返回值(return),而是生成值(yield)。
为什么yield后面还要加return呢,因为C#专家认为只为了这一种情况就增加一个新关键词不行,所以将yield return整体作为一个关键词,yield单独出现时什么都不会发生。
迭代器每次遇到yield return都会生成一个值,立即返回到请求数据项的调用者。然后在请求下一项时,会紧接在上一个yield return语句后执行。
foreach的每次循环都以一个 MoveNext开始,生成一个值后把他返回到位于调用点的foreach语句。 执行yield return之后, GetEnumerator()方法暂停并等待下一个 MoveNext()
如果需要取消迭代,则采用 yield break来使控制立即返回到调用者并终止循环
查询表达式
C#对于集合能够通过查询表达式来对集合进行筛选,以及对集合进行投射。他的语法和SQL语言几乎一模一样
static string[] Keywords = {"abstract", "add*", "alias", "async*"};
private static void ShowSpeacilWords{
IEnumerable<string> selection =
form word in Keywords
where !word.Contains('*')
select word;
foreach(string keyword in selection){
Console.Write(keyword + "");
}
}
和SQL语句的主要区别就是C#查询表达式的字句顺序是from、where、select,而SQL语句是SELECT、FROM、WHERE
此外还有group by,order by等一系列关键词
private static void GroupKeyword(){
IEnumerable<IGrouping<bool,string>> selection =
from word in Keyword
group word by word.Contains('*');
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









