






Mysql 工作原理:
https://blog.csdn.net/inthat/article/details/123244844
二进制日志文件并不是每次写的时候同步到磁盘。因此当数据库所在操作系统发生宕机时,可能会有最后一部分数据没有写入二进制日志文件中,这给恢复和复制带来了问题。
参数sync_binlog=[N]表示每写缓冲多次就同步到磁盘。如果将N设为1,即sync_binlog=1表示采用同步写磁盘的方式来写二进制日志,这时写操作不使用才做系统的缓冲来写二进制日志。(备注:该值默认为0,采用操作系统机制进行缓冲数据同步)。
当sync_binlog=1,还会存在另外问题。当使用InnoDB存储引擎时,在一个事务发出commit动作之前,由于sync_binlog设为1,因此会将二进制日志立即写入磁盘。如果这时已经写入了二进制日志,但是提交还没有发生,并且此时发生了宕机,那么在Mysql数据库下次启动时,由于commit操作并没有发生,所以这个事务会被回滚掉。但是二进制日志已经记录了该事务信息,不能被回滚。
这个问题,可以将innodb_support_xa设为1来解决,确保二进制日志和InnoDB存储引擎数据文件的同步。
从官方解释来看,innodb_support_xa的作用是分两类:
第一,支持多实例分布式事务(外部xa事务),这个一般在分布式数据库环境中用得较多。
第二,支持内部xa事务,说白了也就是说支持binlog与innodb redo log之间数据一致性。(不像别的库只有事务库,redo的追加就是binlog)

Binlog只记录提交的
将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。
为什么必须有“两阶段提交”呢?
如果不使用两阶段提交,假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
1.先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。
然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
2.先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
binlog 的写入机制
Binlog只记录提交的,没有提交的cache数据不要了,
多个事务同时提交,同样很大的影响MySQL和IO性能。可以通过group commit的补丁缓解
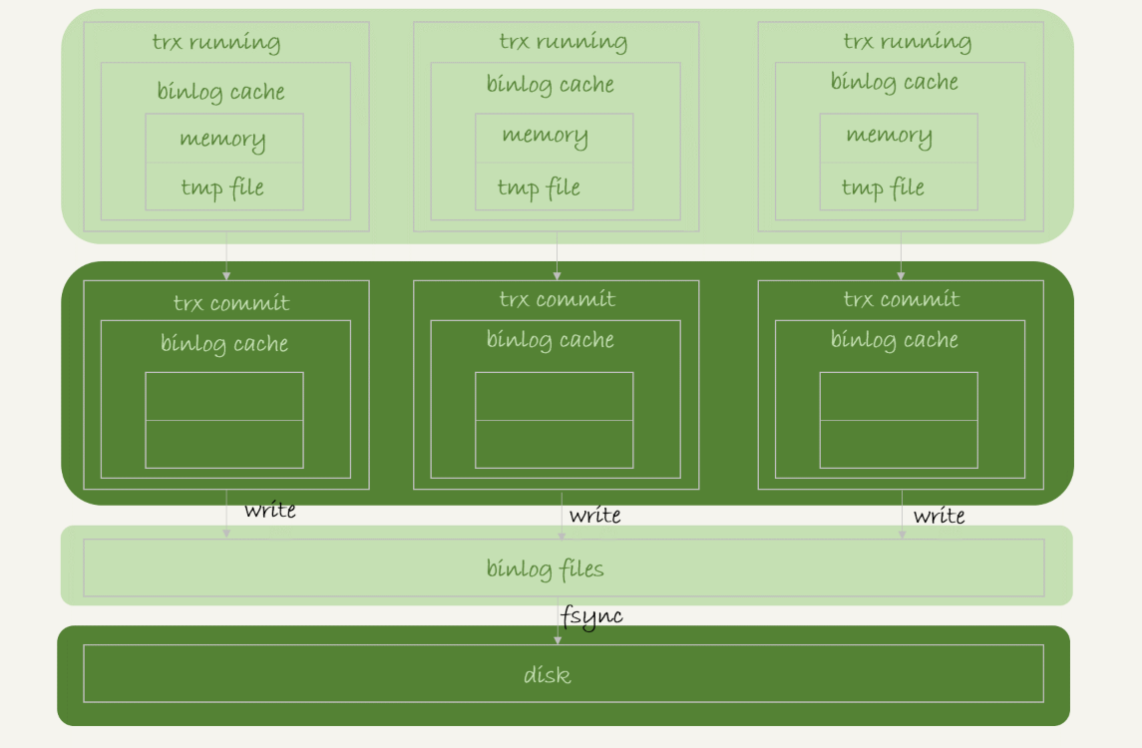
binlog 的写入逻辑比较简单:事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这就涉及到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。状态下图所示。
可以看到,每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
(1) 图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
(2) 图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的 IO。
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
innodb_flush_log_at_trx_commit
提交事务的时候将 redo 日志写入磁盘中,所谓的 redo 日志,就是记录下来你对数据做了什么修改,比如对 “id=10 这行记录修改了 name 字段的值为 xxx”,这就是一个日志。如果我们想要提交一个事务了,此时就会根据一定的策略把 redo 日志从 redo log buffer 里刷入到磁盘文件里去。此时这个策略是通过 innodb_flush_log_at_trx_commit 来配置的,他有几个选项。
值为0 : 提交事务的时候,不立即把 redo log buffer 里的数据刷入磁盘文件的,而是依靠 InnoDB 的主线程每秒执行一次刷新到磁盘。此时可能你提交事务了,结果 mysql 宕机了,然后此时内存里的数据全部丢失。
值为1 : 提交事务的时候,就必须把 redo log 从内存刷入到磁盘文件里去,只要事务提交成功,那么 redo log 就必然在磁盘里了。注意,因为操作系统的“延迟写”特性,此时的刷入只是写到了操作系统的缓冲区中,因此执行同步操作才能保证一定持久化到了硬盘中。
值为2 : 提交事务的时候,把 redo 日志写入磁盘文件对应的 os cache 缓存里去,而不是直接进入磁盘文件,可能 1 秒后才会把 os cache 里的数据写入到磁盘文件里去。
可以看到,只有1才能真正地保证事务的持久性,但是由于刷新操作 fsync() 是阻塞的,直到完成后才返回,我们知道写磁盘的速度是很慢的,因此 MySQL 的性能会明显地下降。如果不在乎事务丢失,0和2能获得更高的性能。
# 查询select @@innodb_flush_log_at_trx_commit;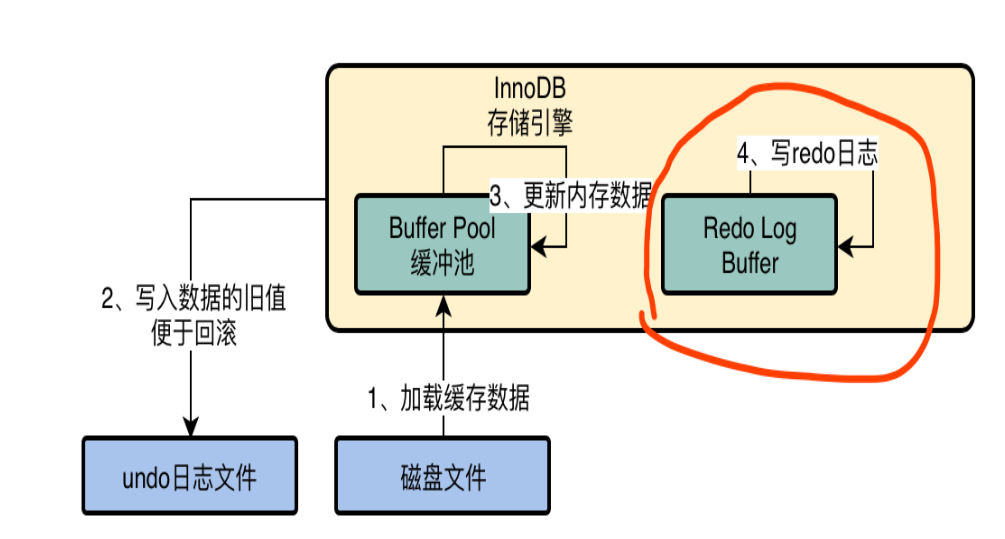
sync_binlog
该参数控制着二进制日志写入磁盘的过程。
该参数的有效值为0 、1、N:
0:默认值。事务提交后,将二进制日志从缓冲写入磁盘,但是不进行刷新操作(fsync()),此时只是写入了操作系统缓冲,若操作系统宕机则会丢失部分二进制日志。
1:事务提交后,将二进制文件写入磁盘并立即执行刷新操作,相当于是同步写入磁盘,不经过操作系统的缓存。
N:每写N次操作系统缓冲就执行一次刷新操作。
将这个参数设为1以上的数值会提高数据库的性能,但同时会伴随数据丢失的风险。
二进制日志文件涉及到数据的恢复,以及想在主从之间获得最大的一致性,那么应该将该参数设置为1,但同时也会造成一定的性能损耗。
优化案例
MySQL中Binlog日志应用慢,该怎么办?
DBA的辛酸事儿2021-07-15647
今天有一个业务需求,需要进行数据恢复操作,需要恢复到2021-07-11 15:21:00,大家应该都了解,这种基于时间点的恢复,首先通过物理备份将mysql全量恢复到异机中,然后再进行增量恢复binlog,从而实现基于时间点的恢复;
业务环境数据量大小150G左右,按照之前做的大量的随机恢复测试总时间分析看,150G的数据量恢复大概可以控制在30min内完成;
正常情况下,1G的binlog应用时间大概在1~3min左右,但是在本次恢复应用binlog的过程,花费了将近15min还没有结束,导致整个恢复时间40多分钟还没有结束;这种情况别说业务人员不能接受,作为DBA估计不能接受吧!
下面就来就针对Binlog回放慢的问题做一个简单的分析:
问题现象:
登录到恢复实例上看一下目前的应用状态,查看到线程目前一直处于Waiting for GTID to be committed的状态,从该状态看,是在等待GTID提交,GTID为548723ca-1f7f-11e9-b3ab-005056b748c5:1655852015
mysql>show processlist;+----+-----------+-----------------+------+---------+--------+----------------------------------+----------------------------------------------------------------------------+-----------+---------------+| Id | User | Host | db | Command | Time | State | Info | Rows_sent | Rows_examined |+----+-----------+-----------------+------+---------+--------+----------------------------------+----------------------------------------------------------------------------+-----------+---------------+|6| dba_admin |127.0.0.1:6492| NULL | Sleep | 218132 || NULL |0| 0 || 16 | dba_admin | 127.0.0.1:11286 | NULL | Query |218078| Waiting for GTID to be committed | SET @@SESSION.GTID_NEXT= '548723ca-1f7f-11e9-b3ab-005056b748c5:1655852015'| 0 |0||17| dba_admin |127.0.0.1:11294| NULL | Query | 0 | starting | show processlist |0| 0 |+----+-----------+-----------------+------+---------+--------+----------------------------------+----------------------------------------------------------------------------+-----------+---------------+3 rows in set (0.00 sec)问题分析:
1、首先检查恢复机资源使用情况,特别是IO,经过查看 ,发现恢复机的负载非常的低,资源非常的空闲,所以应该不是资源繁忙导致的

2、那有可能是大事务导致binlog应用的比较慢,接下来分析下binlog的中是否有大事务
$ mysqlbinlog mysqlbin.002032 | grep"GTID$(printf '\t')last_committed" -B 1 | grep -E '^# at' | awk '{print $3}'| awk 'NR==1 {tmp=$1} NR>1 {print ($1-tmp);tmp=$1}'| sort -n -r | head -n 10mysqlbinlog: [Warning] unknown variable 'loose-default-character-set=utf8'203995532518143518103518055518045518043518037518035518033518023从结果看,竟然有一个200M的大事务,我的天哪,估计就是这个大事务导致回放比较慢,那到底是不是这个大事务导致的呢?
3、 接下来根据长时间运行线程状态提供的GTID的信息,解析下binlog文件查看下卡主的GTID事务具体在执行什么操作?
# at 156880949#210711 2:00:05 server id 255 end_log_pos 156881014 CRC32 0x9c02b320 GTID last_committed=127167 sequence_number=127168SET @@SESSION.GTID_NEXT= '548723ca-1f7f-11e9-b3ab-005056b748c5:1655852015'/*!*/;# at 156881014#210711 2:00:05 server id 255 end_log_pos 156881077 CRC32 0xf27b8fdc Query thread_id=55553520 exec_time=54 error_code=0SETTIMESTAMP=1625940005/*!*/;BEGIN/*!*/;# at 156881077#210711 2:00:05 server id 255 end_log_pos 156881203 CRC32 0xf297d5f2 Rows_query# delete from tabname where create_time <= date_sub(CURRENT_TIMESTAMP, interval 24 hour)# at 156881203#210711 2:00:05 server id 255 end_log_pos 156881301 CRC32 0xa101984d Table_map: `test_db`.`tabname` mapped to number 110# at 156881301#210711 2:00:05 server id 255 end_log_pos 156889457 CRC32 0xbe518068 Delete_rows: table id 110# at 156889457#210711 2:00:05 server id 255 end_log_pos 156897608 CRC32 0x54e957f0 Delete_rows: table id 110# at 156897608#210711 2:00:05 server id 255 end_log_pos 156905781 CRC32 0x8d2612ad Delete_rows: table id 110# at 156905781#210711 2:00:05 server id 255 end_log_pos 156913928 CRC32 0xb15a94ea Delete_rows: table id 110# at 156913928#210711 2:00:05 server id 255 end_log_pos 156922097 CRC32 0x6393fa7c Delete_rows: table id 110# at 156922097#210711 2:00:05 server id 255 end_log_pos 156930266 CRC32 0x2b3d1fda Delete_rows: table id 110# at 156930266#210711 2:00:05 server id 255 end_log_pos 156938414 CRC32 0x78874052 Delete_rows: table id 110# at 156938414#210711 2:00:05 server id 255 end_log_pos 156946567 CRC32 0xb67779fe Delete_rows: table id 110# at 156946567#210711 2:00:05 server id 255 end_log_pos 156954729 CRC32 0x0c0f8899 Delete_rows: table id 110# at 156954729#210711 2:00:05 server id 255 end_log_pos 156962870 CRC32 0x5f79436d Delete_rows: table id 110.......从解析后的binlog可以发现,是一个delete操作, delete from tabname where create_time <= date_sub(CURRENT_TIMESTAMP, interval 24 hour),该SQL删除24小时之前的所有数据,而该操作正是那个200M的事务,到这里就知道了具体的原因,那么该问题该如何解决呢?
解决方案:
1、那就接着等呗,总会应用结束,这你能接受,业务人员估计也是不能接受的;
2、临时调整sync_binlog和innodb_flush_log_at_trx_commit参数,从双1调整成0,之后回放速度就会快很多;
备注:反正是在异机恢复,安全不是重要的,线上环境谨慎考虑;
最后,找业务人员沟通确认该操作的合理性,业务侧将一个大事务拆分成多个小事务执行;
好了,就先说这么多吧,大家有更好的方法欢迎留言一起学习交流














 2263
2263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









