







00、python中,变量总是一个指向对象的指针,而不是一个可以改变的内存区域的标签。Python中,变量名是没有类型的,类型属于对象,而不是变量名。在python中,从变量到对象的连接称为引用,引用是一种关系,是以内存中的指针的形式来实现。
0、python表达式的类别

python 字符串表达式

python 字符串反斜线字符


python字符串格式化代码

Python字符串格式化的通用结构
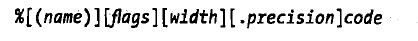
python字符串的方法

python 列表常量和操作


python 字典常量和操作


python 元组常量和操作

python 常见文件运算

1、字符串具有不可变性,即便采用replace,也是生成一个新的字符串
2、正则表达式:
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,
.可以匹配任意字符;要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
更精确地匹配,可以用[]表示范围
[0-9a-zA-Z_]可以匹配一个数字、字母或者下划线;
[0-9a-zA-Z_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如’a100’,’0_Z’,’Py3000’等等;
[a-zA-Z_][0-9a-zA-Z_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
[a-zA-Z_][0-9a-zA-Z_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配’Python’或者’python’。
^表示行的开头,^\d表示必须以数字开头。
表示行的结束,\d 表示必须以数字结束。
re.match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None
切分字符串:
re.split(r’[\s,\;]+’, ‘a,b;; c d’)
[‘a’, ‘b’, ‘c’, ‘d’]
分组字符串:
正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
re.match(r’^(\d+)(0*)$’, ‘102300’).groups()
编译:
import re
编译:
re_telephone = re.compile(r’^(\d{3})-(\d{3,8})$’)
使用:
re_telephone.match(‘010-12345’).groups()
(‘010’, ‘12345’)
re_telephone.match(‘010-8086’).groups()
(‘010’, ‘8086’)
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串
3、使用三引号
(”’或”“”)利用三引号,你可以指示一个多行的字符串。你可以在三引号中自由的使用单引号和双引号
4、类的方法
与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称,按照惯例它的名称是self,
你一定很奇怪Python如何给self赋值以及为何你不需要给它赋值。举一个例子会使此变得清晰。假如你有一个类称为MyClass和这个类的一个实例MyObject。当你调用这个对象的方法MyObject.method(arg1, arg2)的时候,这会由Python自动转为MyClass.method(MyObject, arg1, arg2)——这就是self的原理了。
这也意味着如果你有一个不需要参数的方法,你还是得给这个方法定义一个self参数。
self的用法。注意sayHi方法没有任何参数,但仍然在函数定义时有self。
!/usr/bin/python
Filename: method.py
class Person:
def sayHi(self):
print ‘Hello, how are you?’
p = Person()
p.sayHi()
5、init方法
在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象做一些你希望的 初始化 。注意,这个名称的开始和结尾都是双下划线。
我们把init方法定义为取一个参数name(以及普通的参数self)。在这个init里,我们只是创建一个新的域,也称为name。注意它们是两个不同的变量,尽管它们有相同的名字。点号使我们能够区分它们。
最重要的是,我们没有专门调用init方法,只是在创建一个类的新实例的时候,把参数包括在圆括号内跟在类名后面,从而传递给init方法。这是这种方法的重要之处。
6、私有变量:无法从外部访问实例变量.name和实例变量.__score如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线,在Python中,实例的变量名如果以开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量.__name和实例变量.__score。在Python中,变量名类似__xxx的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用name、score这样的变量名。
有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
7、slots变量
Python允许在定义class的时候,定义一个特殊的slots变量,来限制该class实例能添加的属性,使用slots要注意,slots定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:
8、为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError(‘score must be an integer!’)
if value < 0 or value > 100:
raise ValueError(‘score must between 0 ~ 100!’)
self._score = value
9、额外继承:类名称+MixIn。
10、任何类,只需要定义一个call()方法,就可以直接对实例进行调用。
class Student(object):
def init(self, name):
self.name = name
def call(self):
print(‘My name is %s.’ % self.name)
调用方式如下:
s = Student(‘Michael’)
s() # self参数不要传入
My name is Michael.
11、动态调用
写一个getattr()方法,动态返回一个属性。修改如下:
class Student(object):
def init(self):
self.name = ‘Michael’
def getattr(self, attr):
if attr==’score’:
return 99
当调用不存在的属性时,比如score,Python解释器会试图调用getattr(self, ‘score’)来尝试获得属性,这样,我们就有机会返回score的值:
s = Student()
s.name
‘Michael’
s.score
99
注意,只有在没有找到属性的情况下,才调用getattr,已有的属性,比如name,不会在getattr中查找。
此外,注意到任意调用如s.abc都会返回None,这是因为我们定义的getattr默认返回就是None。要让class只响应特定的几个属性,我们就要按照约定,抛出AttributeError的错误:
class Student(object):
def getattr(self, attr):
if attr==’age’:
return lambda: 25
raise AttributeError(‘\’Student\’ object has no attribute \’%s\” % attr)
这实际上可以把一个类的所有属性和方法调用全部动态化处理了,不需要任何特殊手段。这种完全动态调用的特性有什么实际作用呢?作用就是,可以针对完全动态的情况作调用。
举个例子:
现在很多网站都搞REST API,比如新浪微博、豆瓣啥的,调用API的URL类似:
http://api.server/user/friends
http://api.server/user/timeline/list
如果要写SDK,给每个URL对应的API都写一个方法,那得累死,而且,API一旦改动,SDK也要改。利用完全动态的getattr,我们可以写出一个链式调用:
class Chain(object):
def init(self, path=”):
self._path = path
def getattr(self, path):
return Chain(‘%s/%s’ % (self._path, path))
def str(self):
return self._path
repr = str
试试:
Chain().status.user.timeline.list
‘/status/user/timeline/list’
这样,无论API怎么变,SDK都可以根据URL实现完全动态的调用,而且,不随API的增加而改变!还有些REST API会把参数放到URL中,比如GitHub的API:
GET /users/:user/repos
调用时,需要把:user替换为实际用户名。如果我们能写出这样的链式调用:
Chain().users(‘michael’).repos
就可以非常方便地调用API了。有兴趣的童鞋可以试试写出来。
11、装饰器:就是为了在函数上附加功能,其参数可以是函数。@unique
from enum import Enum, unique
12、枚举类:
from enum import Enum
13、type()可以定义一个class
Hello = type(‘Hello’, (object,), dict(hello=fn)) # 创建Hello class
要创建一个class对象,type()函数依次传入3个参数:
class的名称;
继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
14、try…except…finally…——自动调试报错
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
如果没有错误发生,可以在except语句块后面加一个else,当没有错误发生时,会自动执行else语句。
Python的错误其实也是class,所有的错误类型都继承自BaseException,所以在使用except时需要注意的是,它不但捕获该类型的错误,还把其子类也“一网打尽”。比如:
try:
foo()
except ValueError as e:
print(‘ValueError’)
except UnicodeError as e:
print(‘UnicodeError’)
第二个except永远也捕获不到UnicodeError,因为UnicodeError是ValueError的子类,如果有,也被第一个except给捕获了。
Python所有的错误都是从BaseException类派生的,常见的错误类型和继承关系看这里:
https://docs.python.org/3/library/exceptions.html#exception-hierarchy
使用try…except捕获错误还有一个巨大的好处,就是可以跨越多层调用,比如函数main()调用foo(),foo()调用bar(),结果bar()出错了,这时,只要main()捕获到了,就可以处理:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar(‘0’)
except Exception as e:
print(‘Error:’, e)
finally:
print(‘finally…’)
15、Python内置的logging模块可以非常容易地记录错误信息:通过配置,logging还可以把错误记录到日志文件里,方便事后排查。http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143191375461417a222c54b7e4d65b258f491c093a515000
不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。这样一来,就大大减少了写try…except…finally的麻烦。
16、断言(assert)凡是用print()来辅助查看的地方,都可以用断言(assert)来替代:
assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError:
启动Python解释器时可以用-O参数来关闭assert:关闭后,你可以把所有的assert语句当成pass来看。
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
17、程序调试的终极武器:
写程序最痛苦的事情莫过于调试,程序往往会以你意想不到的流程来运行,你期待执行的语句其实根本没有执行,这时候,就需要调试了。
虽然用IDE调试起来比较方便,但是最后你会发现,logging才是终极武器。
logging
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
import logging
s = ‘0’
n = int(s)
logging.info(‘n = %d’ % n)
print(10 / n)
logging.info()就可以输出一段文本。运行,发现除了ZeroDivisionError,没有任何信息。怎么回事?
别急,在import logging之后添加一行配置再试试:
import logging
logging.basicConfig(level=logging.INFO)
看到输出了:
$ python3 err.py
INFO:root:n = 0
Traceback (most recent call last):
File “err.py”, line 8, in
print(10 / n)
ZeroDivisionError: division by zero
这就是logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
18、打开关闭文件
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
19、目录及文件-os
作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中,这一点要注意一下。查看、创建和删除目录可以这么调用:
查看当前目录的绝对路径:
os.path.abspath(‘.’)
‘/Users/michael’
在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
os.path.join(‘/Users/michael’, ‘testdir’)
‘/Users/michael/testdir’
然后创建一个目录:
os.mkdir(‘/Users/michael/testdir’)
删掉一个目录:
os.rmdir(‘/Users/michael/testdir’)
把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。在Linux/Unix/Mac下,os.path.join()返回这样的字符串:
part-1/part-2
而Windows下会返回这样的字符串:
part-1\part-2
同样的道理,要拆分路径时,也不要直接去拆字符串,而要通过os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
os.path.split(‘/Users/michael/testdir/file.txt’)
(‘/Users/michael/testdir’, ‘file.txt’)
os.path.splitext()可以直接让你得到文件扩展名,很多时候非常方便:os.path.splitext(‘/path/to/file.txt’)
(‘/path/to/file’, ‘.txt’)
这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
文件操作使用下面的函数。假定当前目录下有一个test.txt文件:
对文件重命名:
os.rename(‘test.txt’, ‘test.py’)
删掉文件:
os.remove(‘test.py’)
但是复制文件的函数居然在os模块中不存在!原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。
幸运的是shutil模块提供了copyfile()的函数,你还可以在shutil模块中找到很多实用函数,它们可以看做是os模块的补充。
最后看看如何利用Python的特性来过滤文件。比如我们要列出当前目录下的所有目录,只需要一行代码:
[x for x in os.listdir(‘.’) if os.path.isdir(x)]
[‘.lein’, ‘.local’, ‘.m2’, ‘.npm’, ‘.ssh’, ‘.Trash’, ‘.vim’, ‘Applications’, ‘Desktop’, …]
要列出所有的.py文件,也只需一行代码:[x for x in os.listdir(‘.’) if os.path.isfile(x) and os.path.splitext(x)[1]==’.py’]
[‘apis.py’, ‘config.py’, ‘models.py’, ‘pymonitor.py’, ‘test_db.py’, ‘urls.py’, ‘wsgiapp.py’]
20、时间点:datetime
https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
如果要存储datetime,最佳方法是将其转换为timestamp再存储,因为timestamp的值与时区完全无关。
from datetime import datetime
dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
print(dt)
2015-04-19 12:20:00
dt.timestamp() # 把datetime转换为timestamp
1429417200.0
t = 1429417200.0
print(datetime.fromtimestamp(t))
2015-04-19 12:20:00
把字符串变为时间格式
cday = datetime.strptime(‘2015-6-1 18:19:59’, ‘%Y-%m-%d %H:%M:%S’)
print(cday)
2015-06-01 18:19:59
datetime转换为str
如果已经有了datetime对象,要把它格式化为字符串显示给用户,就需要转换为str,转换方法是通过strftime()实现的,同样需要一个日期和时间的格式化字符串:
print(now.strftime(‘%a, %b %d %H:%M’))
Mon, May 05 16:28
datetime加减
对日期和时间进行加减实际上就是把datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
from datetime import datetime, timedelta
now = datetime.now()
now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)
21、collections中常用函数from collections import Counter
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
Point = namedtuple(‘Point’, [‘x’, ‘y’])
p = Point(1, 2)
p.x
1
p.y
2
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
from collections import defaultdict
dd = defaultdict(lambda: ‘N/A’)
dd[‘key1’] = ‘abc’
dd[‘key1’] # key1存在
‘abc’
dd[‘key2’] # key2不存在,返回默认值
‘N/A’
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
from collections import Counter
c = Counter()
for ch in ‘programming’:
… c[ch] = c[ch] + 1
…
c
Counter({‘g’: 2, ‘m’: 2, ‘r’: 2, ‘a’: 1, ‘i’: 1, ‘o’: 1, ‘n’: 1, ‘p’: 1})
Counter实际上也是dict的一个子类,上面的结果可以看出,字符’g’、’m’、’r’各出现了两次,其他字符各出现了一次。
22、struct
struct的pack函数把任意数据类型变成bytes:
import struct
struct.pack(‘>I’, 10240099)
b’\x00\x9c@c’
‘>I’的意思是:
表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
unpack把bytes变成相应的数据类型:
struct.unpack(‘>IH’, b’\xf0\xf0\xf0\xf0\x80\x80’)
(4042322160, 32896)
根据>IH的说明,后面的bytes依次变为I:4字节无符号整数和H:2字节无符号整数。
23、摘要算法MD5+SHA1
import hashlib
md5 = hashlib.md5()
md5.update(‘how to use md5 in python hashlib?’.encode(‘utf-8’))
print(md5.hexdigest())
计算结果如下:
d26a53750bc40b38b65a520292f69306
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
import hashlib
sha1 = hashlib.sha1()
sha1.update(‘how to use sha1 in ‘.encode(‘utf-8’))
sha1.update(‘python hashlib?’.encode(‘utf-8’))
print(sha1.hexdigest())
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
‘e10adc3949ba59abbe56e057f20f883e’: ‘123456’
‘21218cca77804d2ba1922c33e0151105’: ‘888888’
‘5f4dcc3b5aa765d61d8327deb882cf99’: ‘password’
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
def calc_md5(password):
return get_md5(password + ‘the-Salt’)
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
24、无限迭代itertools:itertools模块提供的全部是处理迭代功能的函数,它们的返回值不是list,而是Iterator,只有用for循环迭代的时候才真正计算。
import itertools
natuals = itertools.count(1)
for n in natuals:
… print(n)
因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()会把传入的一个序列无限重复下去:>>> cs = itertools.cycle(‘ABC’)
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
ns = itertools.repeat(‘A’, 3)
for n in ns:
… print(n)
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
natuals = itertools.count(1)
ns = itertools.takewhile(lambda x: x <= 10, natuals)
list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
chain()
chain()可以把一组迭代对象串联起来,形成一个更大的迭代器:
groupby()
groupby()把迭代器中相邻的重复元素挑出来放在一起:
for key, group in itertools.groupby(‘AAABBBCCAAA’):
实际上挑选规则是通过函数完成的,只要作用于函数的两个元素返回的值相等,这两个元素就被认为是在一组的,而函数返回值作为组的key。如果我们要忽略大小写分组,就可以让元素’A’和’a’都返回相同的key:for key, group in itertools.groupby(‘AaaBBbcCAAa’, lambda c: c.upper()):
… print(key, list(group))















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









