






原文链接:http://blog.csdn.net/joey_su/article/details/17510935
作者:Joey Su
更新日期:2013.12.23
第一章
隐马尔科夫模型工具箱的基础
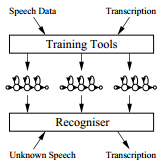
HTK是一个用于建立隐马尔科夫模型的工具箱。隐马尔科夫模型可以被用于建立任何时间序列的模型且HTK的核心是通用的,但是,HTK主要为建立基于隐马尔科夫模型的语音处理工具而设计的,尤其是语音识别,因此,HTK里的许多基础架构支持专注于这项任务。正如上图所示,涉及两个主要处理阶段。第一,HTK训练工具被用于估计一组使用训练发音和它们相关录音样本的隐马尔科夫模型的参数;第二,未知发音通过使用HTK识别工具转录。
这本书的主体主要是关注这两个过程的技术细节。但是,在开始详细介绍之前需要掌握一些隐马尔科夫模型的基本规则,这也对工具箱有个概述和对了解HTK怎样训练和识别有帮助。
这本书的第一部分试图提供这样的信息。在这一章中,将介绍隐马尔科夫模型的基本概念以及他们在语音识别的应用;然后在接下来的章节中提出HTK的简要概述以及针对旧版本的使用者的说明,说明部分强调了在2.0及后期版本的主要区别;最后,在书中的教程部分,第三章描述怎样使用HTK建立一个基于隐马尔科夫模型的语音识别系统,通过描述一个简单小词汇连续语音识别系统来呈现。
这本书的第二部分重现了浏览过的主题并逐个详细讨论,这部分将与第三部分、本书最后提供使用手册的部分相结合进行阅读。其中包含了每个工具的描述、众多被用于配置HTK参数的集合以及当出现问题时的错误信息清单。
最后,请注意这本书只将HTK作为一个工具箱进行研究,它不提供使用将HTK库作为一个编程环境的信息。
1.1 隐马尔科夫模型的常用规则
语音识别系统通常假设语音信号是实现将一些信息编码为一个或多个符号的序列(见Fig. 1.1)。为了实现识别一个说话语音的潜在符号序列的反向操作,连续的语音波形首先被转换成一系列等间隔的离散参数向量。这一系列参数向量假设在被一个向量(通常为10毫秒左右)覆盖的持续时间的基础上组成一个语音波形的正确表现形式,语音波形可被看作是平稳的。尽管不是严格准确,但它是一个可靠的近似值。共同使用的典型的参数表示是平滑的频谱或者线性预测系数,或者许多其他来自这些系数的表现形式。
识别器的作用是在语音向量序列和所求潜在符号序列间产生映射。两个问题让它变得很困难。第一,符号到语音的映射不是一对一的因为不同的潜在符号可以产生类似的语音声音。此外,语音波形的大幅度变化取决于说话者的可变性、心情、环境等。第二,符号间的边界不能明确是来自语音波形。因此,不可能将语音波形看成连续静态类型的序列。
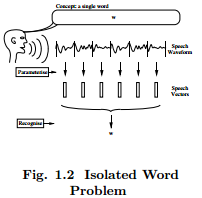
第二个不清楚字词边界问题可以通过限制孤立词识别的任务来避免。正如Fig. 1.2所示,表明语音波形对应的一个从固定词汇表中选择的潜在符号(比如:词)。尽管事实是这个简单的问题有些人为性,它仍然有广泛的实际应用范围。此外,在解决更复杂连续语音项目之前,它是一个介绍基于隐马尔科夫模型的良好基础。因此,首先要解决的是使用隐马尔科夫模型进行孤立词识别。
1.2 孤立词识别
用一系列的声音向量或观察序列O表示每个语音词汇,定义为
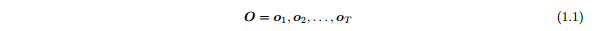
其中,Οt为在t时刻被观察的语音向量。孤立词识别的问题可以被当作是计算
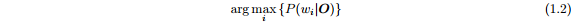
其中,ωi是第i个词汇,其概率不能被精确计算但使用贝叶斯定理可得

因此,对于一个给定的先验概率P(ωi),最可能的语音词汇只取决于似然性P(Ο|ωi)。给定观察序列Ο的维数,来自语音词汇例子的联合条件概率P(Ο1,Ο2,…|ωi)的精确估值是不可行的。然而,如果假定一个单词发音的参数模型例如隐马尔科夫模型,那么来自数据的估值是可能正确的,因为估算分类条件观测密度
P(Ο|ωi)的问题可以被很多更简单的估算马尔科夫模型参数的问题代替。















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









