







一、单目模型
前言:本大标题下1~4部分讲述的都是单目针孔相机
SLAM的数学本质可以抽象为运动方程(x)和观测方程(z)(书上的第二部分)


其中的未知量为xk(在k时刻的状态,也就是位姿)和yj(地图上的路标点)。SLAM就是通过这两个方程,综合已知信息求解出机器人各时刻的姿态,即定位;以及把地图上所有的路标点都求出来,即建图。为了实现定位建图,就要把这两个方程建立出来。(我们想要的就是构建出一个地图,知道它的xy坐标!我们后面叫它像素坐标!!)
理解了吗?简单来说我们就是通过“小萝卜”对外界的感知(yi)以自己目前的位姿(xk)和传感器内部参数(uk)这些数据为基础,进行SLAM(即时定位与地图构建),通过前面的已知我们可以进行定位,那么现在,我们就需要求出它的地图上的坐标(构建地图)!!这也是我们SLAM的本质和这两个方程的用处!(希望你看懂了...)
观测方程与传感器有关,传感器分为多种,包括雷达、相机等等。在V-SLAM中主要是相机,
1.相机系,真实成像

在相机中透镜有一个光心,在他这个成像平面(后面那个面)平行的面上建立x和y,在景物方向上建立z轴(光轴方向),我们把z轴方向上的深度叫做景深。
真实成像的例子:小孔成像模型。假设P(X,Y,Z),通过光心就会投影到相机感光面上P'(-X,-Y,-Z)。

如上图所示,通过光心、相机系和成像投影面组成的这两个三角形是相似关系。所以写出相似关系:
2.简单写法(等比正向缩小)

在上面的模型中,加入一个现实世界中的一个点P通过相机的光心(即主点)投影到图像平面上,形成像素点P'。由于光线是从外部世界穿过光心到达传感器的,所以实际的成像是倒立的。
然而,在处理图像数据时,为了简化计算和理解,研究人员和工程师经常使用一种称为“逆向投影”的方法。在这种方法中,我们假设光线是从相机向外发射并击中外部世界中的点P,从而在图像平面上形成点P'。这种假设导致了一个正立的图像(如右图所示),这在视觉上更直观,也便于后续的处理步骤,如特征提取、匹配和三维重建。(简单来说就是我们把原来倒立在-f的图给他摆正在f处了)
逆向投影的概念允许我们将二维图像点直接对应到三维空间中的射线,这些射线从相机光心出发并指向外部世界。这种方法在SLAM系统中尤其有用,因为它简化了从图像到三维空间的映射(P与P'位于一个象限,没有负号了),并且使得算法设计更加直观。
那么现在上式中的X',Y'分别为:
3.像素系与成像平面

如上图,我们可以知道P'的坐标,但是有一个问题,就是P'的单位是相机系下的,以米为单位,而投影面上以像素为单位,是一个整数。对于一个相片(像素),我们不会把中心点设为原点进行建系,而是把左上角设为原点,将横竖两边设为uv两轴,如上图中的绿色线所示。与x,y的关系如下:
α就是缩放倍数,Cx是平移,经过平移和缩放就可以把相机系下面的点转换成像素坐标系(二维!)下的。
解出:
随后我们可以提出1/Z,并转化成矩阵的形式

使用内参矩阵进行坐标变换的原因在于,相机捕捉到的图像并不是直接反映三维空间中的点,而是经过了透镜的折射和传感器的采样(注意哦,这个并不是噪声!这个可以修正的,这是相机出厂后的自带参数)。内参矩阵能够将这些内部参数的影响考虑进去,使得我们可以准确地将三维空间中的点映射到图像上,或者从图像上的点反推出其在三维空间中的位置。 其实简单来说,就是类似于一个坐标系的转换,从相机系转换到像素系。
我们经常把内参矩阵写成下面的形式:

提问:为何相机内参中的焦距分为fx和fy?相机镜头的焦距不是统一的f吗?

上图中f除以的数(px、py)便是我们上面推导的缩放因子(图中叫做比例因子)。
思考:
①如果我们没在相机系下,在世界坐标系下该怎么办?
这时我们需要利用欧式变换来进行一个坐标系的转化,其中Pw是世界坐标系下的点坐标,而Rcw就是之前我们所学过的,从世界坐标系向相机系中转换的旋转矩阵(so3)。
②相机系下的归一化平面,也就是我们之前的系数1/Z直接放进Pc里面(因为我们后续可以把x/Z看作一个整体,分出来单独除以Z计算量太麻烦了)
也就是说,当我们以后求解从相机系到像素坐标系下时,不再先用kPc,也就是先对k进行坐标系的转换;而是先对Pc进行投影到归一化平面(Z=1),把归一化平面再投影到像素坐标系平面。
综上所述,我们通常这样处理投影:

下式就是针孔相机的投影模型:
这个整体其实就是我们最开始说的观测方程h,这个观测方程中的yj是某一个地图点,它是真实世界中的点,也就是世界坐标系中的Pw,xk是相机在世界坐标系中的位姿,也就是对应这Tcw,最后的是噪声,不重要。
截图再次放在下面
4.畸变
相机成像不同于小孔成像,会有一些畸变的产生。
①透镜(径向畸变):
相机镜头会导致图像的畸变,主要是变得凹凸,可以修正。

修正:(其中的r不是修正的参数,而是距离中心点的距离;k是修正系数,关于r的多项式乘以x进行修正,以表示从中间向外辐射的畸变不同)

②成像平面与镜头不平行(切向畸变)
切向畸变是由镜头制造过程中的不对称性引起的,透镜与成像平面不平行,如果透镜的制造或安装过程中存在误差,导致透镜与成像平面不完全平行(如下图),就会产生切向畸变。

修正:

其中,p1,p2为修正系数,xy都是修正前的坐标点。r还是距离,也就是x²+y²开根号。(别忘记相机系的原点在左上角而不是中心喔)
对于畸变的处理,我们选择在归一化平面上(k)处理畸变。
我们假设上面的Pc'的坐标写为:
而上式中的x0和y0就是我们将要带入修正方程的x与y。求解出来的新的x与y就看成新的点。将这个点再次左乘k,得到最后经过处理畸变的Puv。

书上对该过程的总结如下:

5.其他单目相机:
①鱼眼相机:
【中英字幕】Intel英特尔RealSense双目鱼眼镜头追踪摄像头T265开箱和测试 Tracking Camera![]() https://www.bilibili.com/video/av626644155/?vd_source=033a75d9cfb0b0df5347cafb8b033109 鱼眼镜头的特点是焦距非常短,通常小于16毫米,这使得它们能够提供比标准广角镜头更广阔的视野。
https://www.bilibili.com/video/av626644155/?vd_source=033a75d9cfb0b0df5347cafb8b033109 鱼眼镜头的特点是焦距非常短,通常小于16毫米,这使得它们能够提供比标准广角镜头更广阔的视野。

②卷帘相机与全局相机
卷帘相机采用的是逐行扫描逐行曝光的方式。当上一行的所有像素同时曝光后,下一行的所有像素再同时曝光,直至所有行曝光完成。这种曝光方式涉及到两个控制信号:reset信号和read信号。reset信号负责将一行像素清零,而read信号负责读取一行像素数据。

缺点
- 果冻效应:由于每一行光电转换的时间不同,快速移动的物体可能会产生形变、撕裂等问题,这种现象被称为果冻效应。
- 部分曝光:当物体移动较快时,可能会出现部分曝光的现象,即图像的一部分比其他部分更亮或更暗。
- 斜坡图形:在某些情况下,卷帘快门可能会导致图像出现斜坡图形,即图像的一部分相对于另一部分发生位移。
- 晃动:如果相机在曝光过程中移动,可能会导致图像出现晃动现象,尤其是在使用较低的快门速度时。
果冻效应的示例如下(手机录像就会出现此现象):
全局相机的工作原理在于“全局曝光”,即整幅场景在同一时间曝光。当曝光开始时,相机的传感器会立即启动,使得所有像素点同时开始收集光线,实现同步曝光。当曝光结束时,传感器会立即停止收集光线,此时传感器上的所有像素点都已经完成了曝光,并记录下了图像信息。
优势
- 快速捕捉高速运动场景:由于所有像素点同时曝光,全局快门相机能够更快速地捕捉高速运动的场景,减少因曝光时间差异而导致的图像模糊现象。
- 避免图像失真和色彩偏移:由于所有像素点同时曝光,全局快门相机还能够避免因逐行扫描而产生的图像失真和色彩偏移等问题,从而保证了图像的清晰度和准确性。
总结来说,卷帘相机和全局相机的主要区别在于曝光方式的不同。卷帘相机采用逐行扫描逐行曝光的方式,而全局相机则是所有像素点同时曝光。卷帘相机的缺点主要体现在处理快速移动物体时可能出现的果冻效应和其他相关问题,而全局相机则在这方面具有明显的优势。
参考博客:
③全景相机
全景相机是一种能够捕获360度全方位视野的相机。它通常由多个鱼眼镜头组成,这些镜头能够捕捉到相机周围的所有景象。全景相机的目的是为了提供一种沉浸式的视觉体验,使观众能够感受到仿佛置身于拍摄现场的感觉
【二麦】一个视频弄懂全景视频处理流程,以GoPro MAX为例_哔哩哔哩_bilibili这期视频,我会使用GoPro MAX以及GoPro App与大家详细分享全景视频的编辑思路和编辑流程。更多影像和科技相关的优质视频,请持续关注二麦科技。, 视频播放量 35370、弹幕量 138、点赞数 1771、投硬币枚数 604、收藏人数 828、转发人数 223, 视频作者 二麦科技, 作者简介 商务合作:ermaikeji丨教程/器材/生活,相关视频:【二麦】一个视频帮你去除油腻感,【第119期】一个视频弄懂视频的帧速率,【二麦】如何拍出纯黑纯白和渐变风格的视频背景,【二麦】一个视频弄懂如何用手机拍微距视频,【二麦】这三个视频技巧苹果发布会都在用,【教程】拍出高级的延时大片需要什么|超细节讲解,【二麦】这三个技巧,让你的视频更有创意,【二麦】简单高效实用!如何像李子柒那样拍好固定机位视频,干货!10分钟告别流水账式视频【二麦】,爆火的全景视频怎么拍?![]() https://www.bilibili.com/video/BV1KE411g7bs/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109
https://www.bilibili.com/video/BV1KE411g7bs/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109
二、双目针孔模型

如上图所示的Pc要投影到归一化平面上,P的坐标也就是x/z,y/z,1。我们可以发现它的深度数据丢失掉了。那怎么解决这个问题呢?如果不投影到归一化平面是不是就可以了呢?
其实也不可以,我们上面所说,其实1/Z是一直存在的(从小孔相机成像原理的相似得来的),是因为1/Z在外面不美观从而构造了一个归一化平面。所以与投影到哪个面无关。无论投影到哪个面,Z的数据都会丢失。这就是单目相机的缺点:深度丢失。

双目就可以克服这一点。双目相机的工作原理类似于人类的双眼。 每个人眼看到的景象都有细微的差异,这种差异被称为视差。大脑通过处理两只眼睛传来的不同图像,能够感知物体的深度信息,即物体距离我们的远近。
双目相机模仿了这一过程。它由两个并排的摄像头组成,这两个摄像头分别捕捉同一场景的两个略有不同的视角。然后,通过算法分析这两个视角的差异(视差),计算出场景中每个点的深度信息。这样,即使在原本可能丢失深度信息的情况下,双目相机也能够通过视差来重建场景的三维结构。
从上图右所示,P点到x的距离就是我们想要求的z的深度。已知信息如下,我们知道“相机”光心到相平面的距离,也就是焦距f;还有两个相机光心之间的距离“基线”b(两眼、两个相机之间的距离)。根据相似:
上式中的b-uL-(-uR)如何理解?如下图:我们把两个系重叠在一起

要求Z的话就做如下推导:

根据我们的常识,如果一个物体离我们很远,那么左右眼看到的形态其实差不多,也就是说视差很小。如果看一个很近的物体,那么视差就会变大。对于b(基线),两个摄像头之间的距离对于成像来说是越大越好的(基线大时视差大,很近的时候有一定的风吹草动对两个都有影响,距离稍大一些就会只影响一个),因为现实世界是有噪声的,对于感光元件CMos来说,受到外部光源影响过后会有一些匹配不准和白点噪声的情况,这个时候如果基线很小,误差就会很大。
基线越小,两个摄像头拍摄到的图像之间的视差就越小。视差是同一物体在不同视角下的位置差异。较小的视差意味着系统需要更高的精度来测量微小的位置变化,从而确定深度信息。如果视差太小,即使是很小的测量误差也会导致深度估计中的较大误差。由于现实世界的光线条件和传感器本身的限制,CMOS感光元件可能会受到噪声的影响,比如白点噪声。如果基线较小,那么这些噪声可能会影响视差测量,导致更大的相对误差。例如,在一个小的视差范围内,一个固定的噪声量可能导致较大的视差估计误差,而较大的基线可以提供更大的视差范围,使得同样的噪声对视差的影响减小。
问题:
虽然模型看起来很简单,但是对于计算机的要求很麻烦。因为很难判断两个眼的像素是如何对应的,两张图片各不相同,颜色也五花八门,很难对应,这就需要一些特征匹配之类的算法进行解决。如果我们出现了误差,最后的结果相差会很大:

如果我们想对环境做一个稠密的三维重建,那么我们就需要对相机中每一个像素点进行如上图的操作(匹配,算视差,带入Z的表达式)。比如我们导航中经常用到640*380的相机,也就是大概要算三十万次(一帧)。
三、RGB-D

RGB-D相机是一种结合了RGB(红绿蓝)颜色信息和D(Depth,深度)信息的摄像头。这种相机不仅能够捕捉场景的颜色信息,还能同时获取场景中每个像素点的深度信息,即物体距离相机的距离。
与双目得出深度的方式不同,双目是根据像素匹配计算出来的,而RGB-D是根据红外结构光接收器物理得到的。
1.结构光法:
结构光法通过向被测物体投射一个已知的光图案(通常是条纹或斑点),然后通过分析这些图案在物体表面的变形来计算物体的三维形状和深度信息。(比如离得近的物体线之间的间隔就会近一些)这种方法依赖于物体表面的光图案变化与物体形状之间的关系。
2.飞行时间法:
飞行时间法通过发射连续的光脉冲(通常是红外光)(面阵激光)到被测物体上,然后接收从物体反射回来的光脉冲。通过测量光脉冲的飞行时间(即从发射到返回的时间差),可以计算出物体与相机之间的距离。
RGB-D的优缺点如下:
优点:
1.直接测量深度,无需像但双目那样计算每个像素的深度,算力要求不高
2.RGB-Depth,彩色点云,场景稠密三维重建很友好。
缺点:
1.容易受到日光影响,因为日光也会有红外成分。
2.不同相机之间的RGB-D会互相干扰,比如A相机误接受到B的红外。有一些解决方法比如设置偏振片只接受固定相位的波等等。
3.没办法监测到透射物体
4.成本功耗比较大
四、相机的标定
1.为什么要标定?
我们建立的观测方程既与内参有关又和外参有关,SLAM要解决的问题就是找到x和y,正如我们上面的1.3所示(截图如下)

为了将一个三维世界坐标系中的点 Pw 投影到二维图像坐标系中,我们需要经过两个主要步骤:
-
世界坐标系到相机坐标系的转换:首先,我们将 Pw 通过外参矩阵 Tcw 变换到相机坐标系中,得到 Pc。这里 Tcw 包含了相机相对于世界坐标系的位置和姿态(旋转和平移)。
-
相机坐标系到像素坐标系的转换:接着,我们将 Pc 通过相机的内参矩阵变换并投影到图像平面上,得到像素坐标系中的点。
整个过程中,我们建立了观测方程来描述上述的投影过程。这个观测方程不仅依赖于外参矩阵 Tcw,还依赖于内参矩阵(包含相机的焦距、主点位置等)。
我们的目标是估计某个特定点在图像上的像素坐标(xk,yj)。在估计外参矩阵 Tcw 时,默认内参矩阵是准确的。如果内参矩阵存在误差,那么这种误差会影响外参矩阵 Tcw 的估计。因此,如果内参不准确,外参的估计也会受到影响。比如,一个近视眼戴着眼镜必须戴着眼镜才能估计出自己的位置。
机器人在标定的过程中,不仅仅是标定了自己的内参矩阵,还标定了相机和雷达或IMU之间的关系。
2.常用的标定方法
①OpenCV
②Matlab
③Kalibr(ROS):
支持多相机(涉及到图像拼接的问题,必须知道相对位姿,如基线b)标定;也支持相机与IMU的标定(VIO),也就是带有IMU的视觉里程计;多IMU与IMU内参的标定(IMU也需要标定,除了需要用到Kalibr以外还需要用到IMU_utils)

知识回顾:
什么是 IMU?
IMU(Inertial Measurement Unit,惯性测量单元)是一种传感器,用于测量物体的加速度、角速度和有时还包括磁场强度。常见的IMU包括三轴加速度计、三轴陀螺仪等。
- 加速度计:测量物体在三个轴(通常是x、y、z)上的线性加速度。
- 陀螺仪:测量物体绕这三个轴的角速度。
什么是视觉里程计(VO)?
视觉里程计(Visual Odometry, VO)是通过分析相机图像序列来估计相机(或搭载相机的平台)的位姿变化的技术。VO 主要依赖于图像特征点的跟踪和匹配,以估计相机在连续帧之间的相对运动。
什么是带有 IMU 的视觉里程计(VIO)?
带有 IMU 的视觉里程计(Visual-Inertial Odometry, VIO)结合了视觉信息和 IMU 数据,以更准确地估计相机的位姿变化。VIO 利用了视觉信息的稳定性和 IMU 高频数据的优势,以提高位姿估计的精度和鲁棒性。
VIO 的优点:
- 高频数据:IMU 提供高频数据,可以补充视觉数据的不足,特别是在视觉特征稀少或光照条件不佳的情况下。
- 融合互补信息:视觉信息提供了关于环境结构的丰富信息,而 IMU 数据提供了关于运动的即时信息,两者的结合可以提高位姿估计的精度。
- 鲁棒性增强:在视觉特征丢失或不连续的情况下,IMU 数据可以提供连续的运动估计,从而保持系统的稳定性。
相机与 IMU 的标定
在 VIO 系统中,为了正确地融合视觉和 IMU 数据,需要进行相机与 IMU 的联合标定。标定的主要目的是确定相机与 IMU 之间的相对位置和姿态(即外参),以及各自的内部参数(即内参)。
标定过程通常包括:
- 数据采集:同步采集相机图像和 IMU 数据。
- 特征检测与跟踪:在图像中检测并跟踪特征点。
- IMU 数据预处理:对IMU数据进行积分处理,获得粗略的位姿估计。
- 联合优化:通过优化算法(如非线性最小二乘法)来估计相机与IMU之间的外参。
- 内参标定:如果尚未标定相机和IMU的内参,则需要先单独标定它们。
——————————分割线——————————
3.Kalibr支持的相机模型:
①小孔相机——内参:fx,fy,cx,cy(内参矩阵的四个值)
②全景相机
③鱼眼相机
......

标定后会输出一个.yaml文件
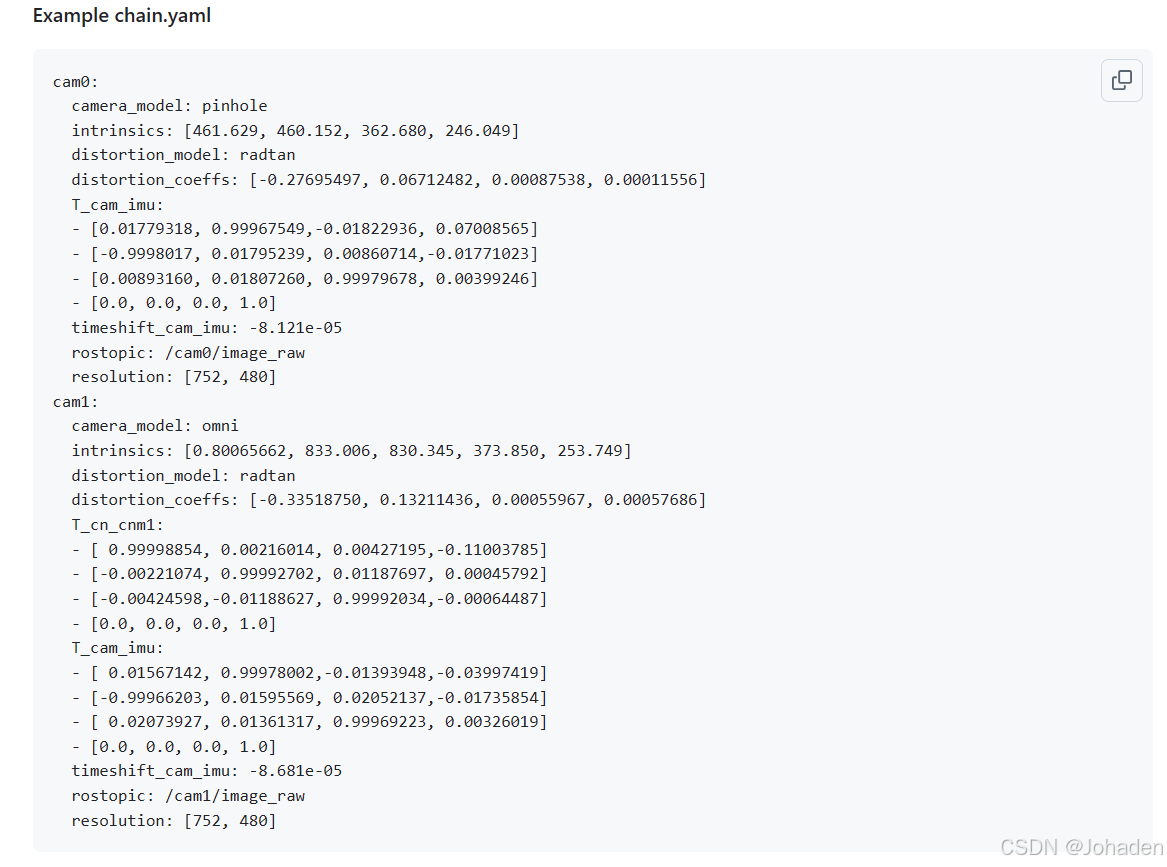
如上图,cam0和cam1就是标定的两个相机,会告诉我们相机的模型,内参矩阵(intrinsics),畸变模型(distortion_model),畸变参数,相机与IMU的相对位姿(T_cam_imu),画幅像素大小(resolution)。
内参矩阵
内参矩阵是一个3x3的矩阵,通常表示为 K,它包含了相机内部的几何参数。这些参数描述了相机传感器的属性,主要包括以下几个方面:
-
焦距(Focal Length):焦距 fx 和 fy 表示沿着图像的x轴和y轴方向上的焦距(就是我们第一部分推导的那个fx,fy),单位通常为像素。焦距反映了相机镜头将远距离物体投影到图像平面上的能力。
-
主点(Principal Point):主点 (cx,cy)是图像平面上的中心点,即光轴与图像平面的交点。在理想情况下,主点位于图像的中心,但在实际应用中可能会有所偏差。
-
像素大小(Pixel Size):尽管内参矩阵本身并不直接包含像素大小的信息,但焦距通常是以像素为单位的,因此间接反映了像素大小的影响。
内参矩阵 K 通常表示为:

其中:
- fx 和 fy 是沿x轴和y轴方向的焦距;
- cx 和 cy 是主点的位置;
- s 是像素之间的偏斜因子,通常为0,表示像素是正方形且没有偏斜。
畸变系数
畸变系数描述了相机成像过程中由于镜头制造缺陷导致的图像畸变。常见的畸变类型包括径向畸变(Radial Distortion)和切向畸变(Tangential Distortion)。
1.径向畸变:径向畸变主要由镜头的制造缺陷引起,导致图像边缘的像素发生变形。径向畸变分为两种类型:
桶形畸变(Barrel Distortion):图像边缘向外膨胀,常见于广角镜头。
枕形畸变(Pincushion Distortion):图像边缘向内收缩,常见于长焦镜头。
2.切向畸变:切向畸变是由于镜头没有完全对准图像平面导致的,使得图像在某些方向上出现扭曲。
畸变系数通常表示为一个向量 D,包含若干个系数:
![]()
其中:
- k1,k2,k3是径向畸变系数;
- p1,p2是切向畸变系数。
五、做SLAM常用的相机
1.RealSense(最常用)

比如:

下面型号的这个相机,它的RGB没有D,它的深度是由双目推算出来的。中间这个红外是在特殊场景下发出红外点进行辅助定位的,比如白墙等。
2.ZED(双目)

3.kinect:结构光的可以直接测深度

4.工业相机(便宜)
①ov7670
②uvc免驱
③csi相机(树莓派)
六、实践部分——opencv
OpenCV(开源计算机视觉库)是一个用于计算机视觉和图像处理的跨平台库。它是由Intel发起并由多个贡献者共同开发的开源项目。OpenCV提供了一系列的算法和工具,可以用来进行各种图像分析和处理任务,比如特征检测、物体识别、结构化稀疏学习、立体匹配、光学字符识别等。
1.opencv安装
未安装会显示如下红色波浪线

那么软件的安装有几种方式呢?
①apt

这个方法安装的并不会安装到最新版本(尤其是老版本的Ubuntu!),因为官方仓库需要经过测试以确保与系统的兼容性。这可能导致安全漏洞或缺少新功能。安全性得不到保证,并且依赖性得不到保证,当不同软件包需要不同版本的同一依赖库时,可能会发生冲突。包管理器需要解决这些依赖关系,有时这会导致无法安装所需的软件版本。并且使用时可能会遇到很多问题。
②snap install
比apt强一些,没有依赖关系,并且保持自动更新。虽然占用大量磁盘空间,但是不会出现一些问题。(我之前给删除了,虽然现在重装系统又安回来了,但是一般用docker不用它,可以尝试一下,还是蛮简便的)
③dpkg -i xxx.deb
安装一些外部应用,有软件的官网提供。比如我的vscode就是用这种方式安装的。
④source(程序员最常用的)(我后续用的就是这个)
cmake
make
make install2.库的安装
老师推荐装ros,因为其中自带一个老版本的opencv。
如果你的Ubuntu是20及以下的,可以使用一键安装(小鱼的一键安装,直接搜即可),但是由于我的版本是新版本(23.10),不支持一键安装(强烈建议无论新老版本都试试,因为这个作者也在不断更新程序!非常便捷!!)
网址如下(注意你要安装什么版本,我下面是IRON版本):

但是我试了一下午,发现由于我安装的版本(23.10)已经非常倒霉的停止运营了......所以安装ros比较困难,我搞了六个小时,失败...最后决定重装Ubuntu系统了....(现在是9月7的17:00,希望我能快点追回来...)
PS:人怎么可以这么倒霉,只恨自己当时是随便下的一个版本!!!!!!(一定要装LTS版本)

(0908的12点)搞了十个小时,我终于回来了,现在版本是众多博主推荐的20.04LTS,当时一键安装报了个错误,已经向博主反馈,所以我准备手动安装Opencv库。
一键安装报错如下,如果你也和我一样或者报错的话,那就先安装opencv吧!!自己单独安装ros又难又费时间!!!还容易安装错误!!opencv很好安!!还是等博主修复bug或者需要的时候再安装吧...

——————————9.08日晚上————————————
博主效率神速,已经修复了...

随后我就又把ROS也安装上了...大家如果可以运行一键安装也可以选择不看下面OpenCV的安装...,大家如果一键没安装成功或者想拓展一下的可以看看... 我的选择是Noetic桌面版。
——————————————分割线————————————
续:opencv安装方法
①下载zip文件夹
Releases - OpenCV![]() https://opencv.org/releases/
https://opencv.org/releases/
②设置共享文件夹
在vmware中设置共享文件夹,如下。

打开虚拟机后,点击文件夹——点击other location(最下面)——computer——mnt——fght下面就有你创建的共享文件夹。
诶!你会发现怎么什么都没有,我也遇到过这个问题,详细过程见下面的博客
VMware中共享文件夹没了怎么办?-CSDN博客文章浏览阅读29次。防止自己忘记,写一篇博客提醒自己https://blog.csdn.net/Johaden/article/details/142024269 之后你就会看见share了,然后把你导入的zip文件复制到你的第三方库文件夹中

③解压文件
首先输入下载解压软件
sudo apt-get install unzip然后解压文件
unzip opencv-4.9.0.zip④cmake
输入下面的命令
cmake -D CMAKE_BUILD_TYPE=Release -D OPENCV_GENERATE_PKGCONFIG=YES ..-D CMAKE_BUILD_TYPE=Release:这个选项指定了构建类型为“Release”。在CMake中,构建类型通常决定了编译器的优化级别和调试信息的包含与否。"Release"模式意味着代码将被优化以提供最佳性能,而不会包含调试信息。(之前的博客里貌似写过)-D OPENCV_GENERATE_PKGCONFIG=YES:这个选项特定于OpenCV库(一个开源的计算机视觉和机器学习库)。它指示CMake在构建过程中生成pkg-config文件。pkg-config是一个帮助编译器定位库文件和包含目录的工具,这对于依赖OpenCV的其他项目来说非常有用,因为它简化了链接和编译时的配置。..:这个参数指定了CMake应该查找顶层CMakeLists.txt文件的位置,这里是当前目录的父目录。

⑤make编译
make -j2线程可根据实际自由调整,太多线程电脑带不动容易崩溃,我两线程大概20分钟。


tiffiny10
⑥最后make install即可。


⑦环境配置
1.


PS:这个路径是怎么来的可以用下面的命令进行查询:
sudo find / -iname opencv4.pc
//-iname:这是一个选项,表示“忽略大小写匹配名称”。
//意思就是在/(根目录下)不区分大小写,查询opencv4.pc的位置
2.

3.
![]()
文末添加
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
4.

5.
![]()
6.验证(出现下面两张图就表示成功了)

![]()
成功啦!!!!!!(苦尽甘来...耗费时间最久的一部分!!)
2.库的调用(程序解析)
对于库的调用类似于上一节,就是修改一下include path就行,因为不仅有eigen,所以不必写到eigen3,写到include这一级还能顺便把opencv给调用了。

先看imageBasics,主CmakeLists文件不再讲解,因为很简单!!有一点可以稍稍了解一下

因为咱们安装的cmake大概率是远远大于2.8的,所以从理论上来说,我们是不用些include_directories()的(高翔老师好像写了,当然也对!),但是需要写一个链接。(大多数第三方库都需要链接,Eigen是个例外。(因为它只有头文件,而opencv这些库还有一些如预编译的代码库.so和源代码等) 链接OpenCV库是为了让编译器能够找到并使用OpenCV提供的函数和资源。
imageBasic的CMakeLists文件

这个配置文件主要就是在生成可执行文件和链接CV库。此时如果我们开始编译会报错,因为我没有装Pangolin,但是即使装了Pangolin,使用作者的源代码依旧可能会报错(不一定会报),报的一般都是fmt的错,只需要按如下方法改即可。 具体代码如下:

imageBasics.cpp
#include <iostream>
#include <chrono>
// 引入标准输入输出库和用于时间测量的chrono库
using namespace std;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
// 引入OpenCV核心模块和用户界面模块,用于图像处理和显示
int main(int argc, char **argv) //如下第一条知识点{
// 主函数开始,接受命令行参数argc(参数数量)和argv(参数数组)
// 读取argv[1]指定的图像
cv::Mat image;// //如下第二条知识点
image = cv::imread(argv[1]);//如下第三条知识点
// 创建一个cv::Mat类型的变量image,并尝试从命令行参数指定的第一个参数位置读取图像文件
if (image.data == nullptr) { //看存进去的指针是不是空,如果空则说明该数据的文件不存在
cerr << "文件" << argv[1] << "不存在." << endl;
return 0;
}
// 检查图像是否成功加载,如果没有,则打印错误信息并退出程序
cout << "图像宽为" << image.cols << ",高为" << image.rows << ",通道数为" << image.channels() << endl;
// 打印图像的基本信息:宽度、高度和颜色通道数
cv::imshow("image", image);//显示这张图,第一个“”内就是这个图的名字
cv::waitKey(0);
// 显示图像并在用户按下任意键之前暂停程序执行
if (image.type() != CV_8UC1 && image.type() != CV_8UC3) {
cout << "请输入一张彩色图或灰度图." << endl;
return 0;
}
// 检查图像的数据类型是否为单通道的灰度图(CV_8UC1)或者三通道的彩色图(CV_8UC3),否则打印错误信息并退出程序
// 遍历图像, 请注意以下遍历方式亦可使用于随机像素访问
// 使用 std::chrono 来给算法计时,C++11自带
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();//把当前时间(now)记录下来
// 开始计时,下面就开始遍历宽高和通道数了
for (size_t y = 0; y < image.rows; y++) {
unsigned char *row_ptr = image.ptr<unsigned char>(y);
// 获取图像第y行的指针
//unsigned short 类型通常表示无符号短整型,这在图像中很常见,因为值通常是非负的。
for (size_t x = 0; x < image.cols; x++) {
unsigned char *data_ptr = &row_ptr[x * image.channels()];
// 获取图像(x, y)处的像素指针
for (int c = 0; c != image.channels(); c++) {
unsigned char data = data_ptr[c];
// 获取像素的第c个通道的值
}
}
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast < chrono::duration < double >> (t2 - t1);
// 结束计时,并计算所用时间
cout << "遍历图像用时:" << time_used.count() << " 秒。" << endl;
// 打印遍历图像所需的时间
// 关于 cv::Mat 的拷贝
// 直接赋值并不会拷贝数据
cv::Mat image_another = image;
// 直接赋值只是创建了一个新的引用到同一个内存区域,改了一个会影响另一个。
image_another(cv::Rect(0, 0, 100, 100)).setTo(0);
// 将左上角100x100的块置零,这也会改变原图像
cv::imshow("image", image);
cv::waitKey(0);
// 显示修改后的图像,这告诉了我们改掉其中一个会影响另一个
// 使用clone函数来拷贝数据(真正的拷贝,不共享,深拷贝)
cv::Mat image_clone = image.clone();
// 使用clone函数创建了一个图像的深拷贝
image_clone(cv::Rect(0, 0, 100, 100)).setTo(255);
// 将克隆图像的左上角100x100的块置为白色(255)
cv::imshow("image", image);
cv::imshow("image_clone", image_clone);
cv::waitKey(0);
// 分别显示原始图像和克隆图像
cv::destroyAllWindows();
// 销毁所有打开的窗口
return 0;
// 主函数结束,返回0表示程序正常终止
}1.int main(int argc, char **argv) 是什么?
int main(int argc, char **argv)是 C 和 C++ 程序中 main 函数的标准定义形式之一,它接收两个参数:
①int argc:
全称是“argument count”,即参数计数。
这是一个整型变量,用来存储传递给程序的命令行参数的数量(包括程序本身的名称)。例如,如果你的程序名为 my_program 并且你在命令行中这样运行:./my_program arg1 arg2,那么 argc 的值将为 3,因为总共有三个参数被传入:程序名 my_program(主函数main)、参数 arg1 和参数 arg2。(这里面的arg1就是我们要做的操作,比如说获取文件名或者读取文件内容)
比如说获取文件名
const char *filename = argv[1]; argv 是一个指向字符串数组的指针。argv[0] 是程序的名称,argv[1] 是第一个命令行参数。在这里,我们假设用户提供的第一个参数是一个文件名,因此 argv[1](是个地址) 就是(指向了)我们要打开的文件名。就比如我们的代码随后使用ifstream来打开文件。
②char **argv:
全称可以理解为“argument values”,即参数值。
这是一个字符指针的指针数组,用来存储命令行参数的实际值。数组中的每个元素都是指向字符串的指针,这些字符串是传递给程序的命令行参数。继续上面的例子,argv[0] 会指向字符串 "my_program",argv[1] 会指向 "arg1",argv[2] 会指向 "arg2"。注意 argv 数组是以 NULL 结尾的,这意味着 argv[argc] 是 NULL。
比如上面那个例子中argv[1]就会指向要打开的文件名,并赋值给filename,所以我们就知道这个文件名是什么了。
2.由于图像本质上是由像素组成的二维数组,而cv::Mat 是一个多维数值数组容器,它可以存储各种类型的矩阵数据,包括但不限于图像。(存放图片属性)
当使用 cv::Mat 来存储图像时,我们可以将其视为一个包含图像数据的矩阵。图像的每个像素可以有多个通道(通常是红色、绿色、蓝色,即RGB;或者是亮度和色度信息),这些通道的数据会被连续存储在一起。例如,一个三通道的彩色图像,每个像素会占用3个字节(对于8位图像),按行存储。
3.image = cv::imread(argv[1]);我怎么知道中间应该输入什么?
image = cv::imread(argv[1]);//如下第三条知识点
// 创建一个cv::Mat类型的变量image,并尝试从命令行参数指定的第一个参数位置读取图像文件
上官网查阅。如下
OpenCV: OpenCV modules![]() https://docs.opencv.org/4.9.0/
https://docs.opencv.org/4.9.0/

括号内应输入一个引用的常量字符串(表示要读取的图像文件的路径。这个路径可以是绝对路径,也可以是相对于当前工作目录的相对路径。)就像我们上面说的,类似于指针,通过我们输入的路径找到参数,并赋值输出。

4.cols为行数(宽度),rows为列数(高度),channels为通道数(例如,对于一个 RGB 图像,channels() 将返回 3,对于一个灰度图像,将返回 1)
cout << "图像宽为" << image.cols << ",高为" << image.rows << ",通道数为" << image.channels() << endl;
// 打印图像的基本信息:宽度、高度和颜色通道数

数据类型示例
以下是一些常见的 cv::Mat 数据类型:
CV_8UC1:8位无符号整型,单通道。CV_8UC3:8位无符号整型,三通道。CV_8UC4:8位无符号整型,四通道。CV_16SC1:16位有符号整型,单通道。CV_32FC1:32位浮点型,单通道。
PS:这个8为无符号整型是什么意思?
(如果大家学过遥感的话很好理解)
-
位数:8位意味着这种类型的数据由8个二进制位组成。每个位可以是0或1,因此8位可以表示
=256 种不同的值。
-
范围:无符号整型表示非负数(因为无论是行、列或者深度都是非负数),因此8位无符号整型的取值范围是从0到255。
-
用途:在图像处理中,每个像素的颜色通常用8位来表示。例如,在8位灰度图像中,每个像素值表示该像素的亮度等级,其中0表示黑色,255表示白色。对于彩色图像,每个颜色通道(红、绿、蓝)也常常使用8位来表示,这样每个通道也有256种可能的强度值。
在图像处理中的应用:
- 灰度图像:每个像素值表示灰度级,范围从0(黑色)到255(白色)。
- 彩色图像:每个像素通常由三个8位通道组成(红色、绿色、蓝色),每个通道表示对应颜色的强度。因此,一个24位彩色图像(8位红 + 8位绿 + 8位蓝)可以表示 256×256×256=16777216 种不同的颜色。(这就很清晰了)
5.
for (size_t y = 0; y < image.rows; y++) {
// 用cv::Mat::ptr获得图像的行指针
unsigned char *row_ptr = image.ptr<unsigned char>(y); // row_ptr是第y行的头指针
//image.ptr<unsigned char>(y) 是一个成员函数,它返回指向图像第 y 行第一个元素的指针。
for (size_t x = 0; x < image.cols; x++) {
// 访问位于 x,y 处的像素
unsigned char *data_ptr = &row_ptr[x * image.channels()]; // data_ptr 指向待访问的像素数据
//这一步是为了获取指向图像 (x, y) 处像素的指针。由于每个像素可能有多个通道(如灰度图的1个通道,彩色图的3个通道),我们需要考虑到这一点。x * image.channels() 计算了在当前行中到第 x 列的偏移量,乘以通道数是因为每个像素占用了多个连续的字节。&row_ptr[x * image.channels()] 就是指向当前像素的指针。
//为什么要乘通道?(讲解在下面)
// 输出该像素的每个通道,如果是灰度图就只有一个通道
for (int c = 0; c != image.channels(); c++) {
unsigned char data = data_ptr[c]; // data为I(x,y)第c个通道的值
为什么要乘通道数?
在遍历图像的过程中,我们需要访问每个像素的具体值。对于灰度图像,每个像素只有一个通道;而对于彩色图像(如RGB图像),每个像素有三个通道(红、绿、蓝)。在遍历图像时,我们首先按行访问,然后按列访问。假设我们有一个 cv::Mat 对象 image,它的类型为 CV_8UC3(即8位无符号整型,三通道),那么每个像素占用3个字节。所以,每个x就需要不止一个字节来存放多通道图像。
undistortImage.cpp (去畸变)
#include <opencv2/opencv.hpp>
#include <string>
using namespace std;
string image_file = "/home/suki/slambook2/ch5/imageBasics/distorted.png"; // 请确保路径正确(作者的源路径找不到图片,最好是绝对路径),我们刚才是用argv输进去的,这个是直接输入定义进去了一个图片路径
int main(int argc, char **argv) {
// 本程序实现去畸变部分的代码。尽管我们可以调用OpenCV的去畸变,但自己实现一遍有助于理解。
// 畸变参数,这里把k3省略了,当然,系数越多肯定是越精准的。
double k1 = -0.28340811, k2 = 0.07395907, p1 = 0.00019359, p2 = 1.76187114e-05;
// 内参
double fx = 458.654, fy = 457.296, cx = 367.215, cy = 248.375;
cv::Mat image = cv::imread(image_file, 0); // 图像是灰度图,CV_8UC1
int rows = image.rows, cols = image.cols;
cv::Mat image_undistort = cv::Mat(rows, cols, CV_8UC1); // 去畸变以后的图
//创建一个新的 cv::Mat 对象 image_undistort,用于存储去畸变后的图像。
// 计算去畸变后图像的内容
for (int v = 0; v < rows; v++) {
for (int u = 0; u < cols; u++) {
// 按照公式,计算点(u,v)对应到畸变图像中的坐标(u_distorted, v_distorted)
double x = (u - cx) / fx, y = (v - cy) / fy;
double r = sqrt(x * x + y * y);
//下面两行就是去畸变的公式,opencv自身是有对应函数的,作者从底层计算了去畸变的过程。
double x_distorted = x * (1 + k1 * r * r + k2 * r * r * r * r) + 2 * p1 * x * y + p2 * (r * r + 2 * x * x);
double y_distorted = y * (1 + k1 * r * r + k2 * r * r * r * r) + p1 * (r * r + 2 * y * y) + 2 * p2 * x * y;
double u_distorted = fx * x_distorted + cx;
double v_distorted = fy * y_distorted + cy;
//在去完畸变后会溢出来一部分,因为相比原图可能会有放大的溢出变化,但是我只需要原始大小
// 赋值 (最近邻插值)
if (u_distorted >= 0 && v_distorted >= 0 && u_distorted < cols && v_distorted < rows) {
image_undistort.at<uchar>(v, u) = image.at<uchar>((int) v_distorted, (int) u_distorted);
} else {
image_undistort.at<uchar>(v, u) = 0;
}
}
}
// 画图去畸变后图像
cv::imshow("distorted", image);
cv::imshow("undistorted", image_undistort);
cv::waitKey();
return 0;
}这个畸变,我们上面之前是分着来的,可以联合两个方程组,通过5个畸变系数找到该点正确位置:

在很多情况下,k3 可能并不是必需的,特别是在一些简单的情况下,只用 k1 和 k2 就足以描述大多数常见的径向畸变了。因此,在实际应用中,不一定需要所有五个系数。
为什么cv::Mat image = cv::imread(image_file, 0); 第二个参数是0?


机翻版本:

注意,我们这里是枚举而不是宏定义,在宏定义里面CV_8UC1的值是1。这里只是因为我们加载的图像是灰度的。
畸变怎么去除的?
// 计算去畸变后图像的内容
for (int v = 0; v < rows; v++) {
for (int u = 0; u < cols; u++) {
// 按照公式,计算点(u,v)对应到畸变图像中的坐标(u_distorted, v_distorted)
double x = (u - cx) / fx, y = (v - cy) / fy;
double r = sqrt(x * x + y * y);
//下面两行就是去畸变的公式,opencv自身是有对应函数的,作者从底层计算了去畸变的过程。
double x_distorted = x * (1 + k1 * r * r + k2 * r * r * r * r) + 2 * p1 * x * y + p2 * (r * r + 2 * x * x);
double y_distorted = y * (1 + k1 * r * r + k2 * r * r * r * r) + p1 * (r * r + 2 * y * y) + 2 * p2 * x * y;
//再次乘内参矩阵得出Puv
double u_distorted = fx * x_distorted + cx;
double v_distorted = fy * y_distorted + cy;
// 赋值 (最近邻插值)
if (u_distorted >= 0 && v_distorted >= 0 && u_distorted < cols && v_distorted < rows) {
image_undistort.at<uchar>(v, u) = image.at<uchar>((int) v_distorted, (int) u_distorted);//uchar 是 unsigned char 的简写,表示8位无符号整型。
//at 方法会在访问之前检查索引是否在矩阵的有效范围内。如果索引越界,它会抛出异常,防止程序崩溃。
} else {
image_undistort.at<uchar>(v, u) = 0;
}
}
}
如上图,畸变应该在相机归一化后的三维平面下去的,但是我们现在只有一个Puv,我们需要先将Puv乘一个k的逆变成Pc',然后再进行去畸变后乘内参矩阵k。
之前我们说过,像素坐标系是一个二维的面,是通过上面的式子求出来的。现在代码中就是这个过程的反算。那么这个式子中的Z是什么东西?我们也不知道在相机系中的深度啊?
其实,我们无需深度,从Pc'到Pc''这个过程,其实与深度是无关的,所以我们完全可以把X/Z当作新的X,Y/Z当作新的Y。
stereoVision.cpp(双目怎么求视差和深度)
#include <opencv2/opencv.hpp>
#include <vector>
#include <string>
#include <Eigen/Core>
#include <pangolin/pangolin.h>
#include <unistd.h>
using namespace std;
using namespace Eigen;
// 文件路径
string left_file = "./left.png";
string right_file = "./right.png";
// 在pangolin中画图,已写好,无需调整
void showPointCloud(
const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud);
//不会改变的常量(类似数组,可以存向量矩阵等很多)
//std::vector 可以存储任何类型的对象,但是它一次只能存储单一类型的对象。
int main(int argc, char **argv) {
// 内参
double fx = 718.856, fy = 718.856, cx = 607.1928, cy = 185.2157;
// 基线
double b = 0.573;
// 读取图像
cv::Mat left = cv::imread(left_file, 0);//灰度读取,默认8比特数据组
//cv::Mat 是OpenCV中的一个矩阵类,用于表示图像或其他多维数组。
cv::Mat right = cv::imread(right_file, 0);
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(
0, 96, 9, 8 * 9 * 9, 32 * 9 * 9, 1, 63, 10, 100, 32); // 神奇的参数(讲解见下面3)
cv::Mat disparity_sgbm, disparity;
sgbm->compute(left, right, disparity_sgbm);//通过指针 sgbm 调用 compute 函数来计算视差图。
//compute 函数的主要作用是从一对立体图像(左图和右图)中计算出视差图。
disparity_sgbm.convertTo(disparity, CV_32F, 1.0 / 16.0f);//转换格式为32位浮点数,创建新的视差图。
//后面那个数字是一个缩放因子,用于将原始视差图中的数据转换为浮点数。通常情况下,视差图是以16倍的精度存储的,即每16个单位表示一个真实的视差值。通过除以16,可以将数据转换为实际的视差值。
// 生成点云
vector<Vector4d, Eigen::aligned_allocator<Vector4d>> pointcloud;
// 如果你的机器慢,请把后面的v++和u++改成v+=2, u+=2
// 恢复深度,把左图的每个像素深度恢复出来
for (int v = 0; v < left.rows; v++)
for (int u = 0; u < left.cols; u++) {
if (disparity.at<float>(v, u) <= 0.0 || disparity.at<float>(v, u) >= 96.0) continue;
// 判断当前像素的视差值是否有效。
// disparity.at<float>(v, u) 中.at() 函数可以根据索引返回矩阵中的元素,也就是视差图 disparity 在位置 (v, u) 上的元素值,类型为 float。
Vector4d point(0, 0, 0, left.at<uchar>(v, u) / 255.0); // 前三维为xyz,第四维为颜色
// 根据双目模型计算 point 的位置,注意这里的x和y其实是x/z
double x = (u - cx) / fx;
//cx 是相机中心在x轴上的位置。
//fx 是相机在x轴上的焦距。
double y = (v - cy) / fy;
double depth = fx * b / (disparity.at<float>(v, u));
point[0] = x * depth;//还原x(乘z)
point[1] = y * depth;
point[2] = depth;
//计算出的xyz是基于相机坐标系下的坐标,绝不是世界坐标系的,它是在归一化平面向像素系进行的深度恢复!
pointcloud.push_back(point);//将计算好的点添加到点云 pointcloud 中。
}
cv::imshow("disparity", disparity / 96.0);
//显示一个名为 "disparity" 的窗口,并在其中展示经过缩放处理的视差图(disparity map)。
//对 disparity 中的每个元素进行除以 96.0 的操作,类似于归一化
cv::waitKey(0);
// 画出点云
showPointCloud(pointcloud);
return 0;
}
//pangolin
void showPointCloud(const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud) {
if (pointcloud.empty()) {
cerr << "Point cloud is empty!" << endl;
return;
}
pangolin::CreateWindowAndBind("Point Cloud Viewer", 1024, 768);
glEnable(GL_DEPTH_TEST);
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
pangolin::OpenGlRenderState s_cam(
pangolin::ProjectionMatrix(1024, 768, 500, 500, 512, 389, 0.1, 1000),
pangolin::ModelViewLookAt(0, -0.1, -1.8, 0, 0, 0, 0.0, -1.0, 0.0)
);
pangolin::View &d_cam = pangolin::CreateDisplay()
.SetBounds(0.0, 1.0, pangolin::Attach::Pix(175), 1.0, -1024.0f / 768.0f)
.SetHandler(new pangolin::Handler3D(s_cam));
while (pangolin::ShouldQuit() == false) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
d_cam.Activate(s_cam);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glPointSize(2);
glBegin(GL_POINTS);
for (auto &p: pointcloud) {
glColor3f(p[3], p[3], p[3]);
glVertex3d(p[0], p[1], p[2]);
}
glEnd();
pangolin::FinishFrame();
usleep(5000); // sleep 5 ms
}
return;
}视差图效果如下:

其中这个颜色的深浅就代表了视差的远近。
点云图的效果如下:
这个图是由一些点组成的,而不是线。这些白色的是因为左右目会有一些视野盲区的缺失。这个我们发现它的范围很远,这时因为基线很大,50多厘米,所以才会导致可以识别到很远的地方,但实际上机器人的基线不会这么长。

1.
const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud; const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud 是一个函数参数声明,它指定了一个引用类型的常量参数,该参数是一个 vector 容器(本身可以自动拓展),容器内部存储的是 Vector4d 类型的对象。这里 & 表示这是一个引用参数,意味着函数接收的是 vector 对象的一个别名而非拷贝,而 const 关键字则表明这个 vector 对象在函数体内不能被修改。
Eigen::aligned_allocator<Vector4d> 是一个特定的分配器类型,它是Eigen库提供的,用于替代标准库中的 std::allocator。这个分配器的主要目的是为了优化内存对齐,这对于某些硬件(如SIMD指令集)来说是非常重要的,因为正确的内存对齐可以提高性能。没有对齐存放的话就有可能报错。

这里其实就是在画上面的点云图,每个点是由xyz坐标和灰度这四维数据构成的,所以这句话
2.在 OpenCV 中,默认情况下,当使用 cv::imread 读取图像时,无论是彩色图像还是灰度图像,读取后的图像数据通常都是以8位无符号整数(CV_8U)的形式存储的。也就是说每个像素值的范围是从0到255。
当使用 cv::imread 函数并指定以灰度模式读取图像(标志位为0或 IMREAD_GRAYSCALE)时,得到的 cv::Mat 对象会是一个单通道的8位灰度图像。这是因为大多数现代图像文件格式都支持8位灰度图像,即每个像素由一个8位的值表示,这个值决定了该像素的亮度级别。
在 OpenCV 中,判断一个图像是否是8位灰度图像的方法:
- 检查图像的通道数:可以通过
img.channels()方法获取图像的通道数,如果是1,则是一个单通道图像。 - 检查图像的数据类型:可以通过
img.type()方法获取图像的数据类型。对于8位灰度图像,返回值应该是CV_8UC1。
3.神奇的参数那句话是什么意思?(看一看了解即可,不用深知,后面第八讲会学)
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(
0, 96, 9, 8 * 9 * 9, 32 * 9 * 9, 1, 63, 10, 100, 32);这个就是实现了一个匹配算法(ch8的内容) ,它用于从一对立体图像中计算视差图。
cv::Ptr<cv::StereoSGBM>
cv::Ptr 是一个“智能”指针类,用于管理 cv::StereoSGBM 类型的对象。智能指针的作用是在不再需要对象时自动释放内存,防止内存泄漏。在OpenCV中,cv::Ptr 经常用作面向对象设计的一部分,以便于内存管理和资源回收。
cv::StereoSGBM
cv::StereoSGBM 是一个类,代表了一种用于计算立体视差图的方法。它基于半全局匹配(Semi-Global Block Matching)算法。这个算法通过在多个方向上应用全局约束来改进传统的块匹配算法,从而获得更好的视差图。(不完整,下面那个才是完整的,create是必须有的)
cv::StereoSGBM::create(...)
cv::StereoSGBM::create 是一个静态成员函数,用于创建 cv::StereoSGBM 类的对象。它返回一个 cv::Ptr<cv::StereoSGBM> 类型的智能指针,指向新创建的对象。这种设计的好处在于:
- 内存管理:
cv::Ptr会自动管理对象的生命周期,当不再需要该对象时,它会自动释放内存。 - 延迟初始化:对象的实际创建可能在第一次使用时才发生,而不是立即创建。
- 接口统一:无论底层对象是否需要特殊构造,
create函数提供了一个统一的方式来创建对象。
注意:
我上面分着写只是为了讲解方便所以把cv::StereoSGBM分开来讲,实际上那个create是必须的。如果没有 create,就需要直接使用构造函数来创建对象。然而,cv::StereoSGBM 类并没有提供一个可以直接调用的构造函数来初始化所有的参数。这意味着无法直接创建一个 cv::StereoSGBM 对象,所以我们必须使用 create 函数。
那神奇的参数又是什么?(了解,看看就行,后面第八节会讲)
-
0: 这个参数在旧版OpenCV中是一个占位符,表示视差的最大变化范围,但实际效果取决于
blockSize和其他参数。在新版OpenCV中,你可以直接指定视差范围。 -
96: 视差的最大变化范围,单位为16个像素。即最大视差为
96 * 16。 -
9: 匹配窗口的尺寸(
blockSize),必须是奇数。这个值决定了用于计算匹配成本的像素块大小。 -
8 * 9 * 9: 惩罚系数
P1,用于惩罚视差变化较小的情况。通常P1与blockSize相关,这里8 * 9 * 9是一个经验值。 -
32 * 9 * 9: 惩罚系数
P2,用于惩罚视差变化较大的情况。通常P2比P1大得多,这里32 * 9 * 9也是一个经验值。 -
1: 左右视差图之间的最大差异,用于左右一致性检查。
-
63: 预过滤的最大值截断,用于限制 SAD 匹配的成本,减少噪声影响。
-
10: 视差唯一性比率,用于确保匹配的唯一性。
-
100: 用于检测孤立像素的窗口大小。
-
32: 用于检测孤立像素的视差变化阈值。


机翻的“差异”就是我们的视差。
joinmap.cpp
对五张彩色图用结构光生成三维(有深度信息),需要考虑的是位姿(pose),也就是怎么把这五张图没有重叠的拼在一起。

#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <boost/format.hpp> // for formating strings。可以创建格式化的字符串,就是后面的更新fmt的部分。
#include <pangolin/pangolin.h>
#include <sophus/se3.hpp>
using namespace std;
typedef vector<Sophus::SE3d, Eigen::aligned_allocator<Sophus::SE3d>> TrajectoryType;
typedef Eigen::Matrix<double, 6, 1> Vector6d;//存彩色图,xzy,rgb
// 在pangolin中画图,已写好,无需调整
// 知道把六维度输进去可以化成图就行
void showPointCloud(
const vector<Vector6d, Eigen::aligned_allocator<Vector6d>> &pointcloud);
int main(int argc, char **argv) {
vector<cv::Mat> colorImgs, depthImgs; // 彩色图和深度图
TrajectoryType poses; // 相机位姿
ifstream fin("./pose.txt");//读取pose,没读取到就是0,进入下面的循环
if (!fin) {
cerr << "请在有pose.txt的目录下运行此程序" << endl;
return 1;
}
for (int i = 0; i < 5; i++) {
boost::format fmt("./%s/%d.%s"); //图像文件格式,%s 用于表示字符串,%d 用于表示整数。
//boost::format类是一个用于格式化输出的强大工具,它可以让你像使用printf一样方便地格式化字符串
colorImgs.push_back(cv::imread((fmt % "color" % (i + 1) % "png").str()));//颜色放入vector里。详情分析见下方第一点。
depthImgs.push_back(cv::imread((fmt % "depth" % (i + 1) % "pgm").str(), -1)); // 使用-1读取原始图像
//上面两行就是循环读取5个彩色和深度图像文件,并存储到对应的容器中。
//从pose.txt文件中读取每个图像对应的相机姿态,构建为Sophus::SE3d对象,并添加到poses向量中。
double data[7] = {0};
for (auto &d:data)
fin >> d; //fin就是上面的pose,把pose输进d里面。
Sophus::SE3d pose(Eigen::Quaterniond(data[6], data[3], data[4], data[5]),//姿态(旋转),Quaterniond表示四元数。SE3 是一个表示三维空间中刚体变换的李群(就是变换矩阵T)。
Eigen::Vector3d(data[0], data[1], data[2])); //位置(平移)
poses.push_back(pose); //把图和位置以及维度对应起来放进poses(vector)中。
}
// 计算点云并拼接(拼接是要转换回世界坐标系!!)
// 相机内参
double cx = 325.5;
double cy = 253.5;
double fx = 518.0;
double fy = 519.0;
double depthScale = 1000.0;//表示深度图像中每个像素值与实际物理距离之间的转换因子。
vector<Vector6d, Eigen::aligned_allocator<Vector6d>> pointcloud;//创建了点云vector向量(xyz和rgb)
pointcloud.reserve(1000000);//思考一下这句话作用是什么?为什么要用reserve,vector不是可以自己动态分配吗?(解答见下方第3点)
for (int i = 0; i < 5; i++) { //一层就是遍历五张图片,后面的两层都是遍历图中的每一个像素。
cout << "转换图像中: " << i + 1 << endl;
cv::Mat color = colorImgs[i];
cv::Mat depth = depthImgs[i];
Sophus::SE3d T = poses[i];
for (int v = 0; v < color.rows; v++)
for (int u = 0; u < color.cols; u++) {
unsigned int d = depth.ptr<unsigned short>(v)[u]; // 读取位于像素坐标 (v, u) 处的深度值
//depth.ptr<unsigned short>(v) 返回了深度图像中行 v 的指针,然后 [u] 访问该行中列 u 的深度值。
//unsigned short 类型通常表示无符号短整型,这在深度图像中很常见,因为深度值通常是非负的。
if (d == 0) continue; // 为0表示没有测量到,则跳过当前像素,不对其进行进一步处理
Eigen::Vector3d point; //存储3D空间中的一个点
point[2] = double(d) / depthScale; //z
point[0] = (u - cx) * point[2] / fx; //x
point[1] = (v - cy) * point[2] / fy; //y
Eigen::Vector3d pointWorld = T * point; //投影到世界系中,因为图片不同
//添加颜色
Vector6d p;
p.head<3>() = pointWorld;
p[5] = color.data[v * color.step + u * color.channels()]; // blue
p[4] = color.data[v * color.step + u * color.channels() + 1]; // green
p[3] = color.data[v * color.step + u * color.channels() + 2]; // red
pointcloud.push_back(p); //六维点云
}
}
//嵌套循环遍历每个彩色和深度图像的像素,计算每个非零深度值对应的3D世界坐标点,并将颜色信息附加到点云数据结构中。
cout << "点云共有" << pointcloud.size() << "个点." << endl;
showPointCloud(pointcloud);
return 0;
}
//可视化 pangolin
void showPointCloud(const vector<Vector6d, Eigen::aligned_allocator<Vector6d>> &pointcloud) {
if (pointcloud.empty()) {
cerr << "Point cloud is empty!" << endl;
return;
}
pangolin::CreateWindowAndBind("Point Cloud Viewer", 1024, 768);
glEnable(GL_DEPTH_TEST);
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
pangolin::OpenGlRenderState s_cam(
pangolin::ProjectionMatrix(1024, 768, 500, 500, 512, 389, 0.1, 1000),
pangolin::ModelViewLookAt(0, -0.1, -1.8, 0, 0, 0, 0.0, -1.0, 0.0)
);
pangolin::View &d_cam = pangolin::CreateDisplay()
.SetBounds(0.0, 1.0, pangolin::Attach::Pix(175), 1.0, -1024.0f / 768.0f)
.SetHandler(new pangolin::Handler3D(s_cam));
while (pangolin::ShouldQuit() == false) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
d_cam.Activate(s_cam);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glPointSize(2);
glBegin(GL_POINTS);
for (auto &p: pointcloud) {
glColor3d(p[3] / 255.0, p[4] / 255.0, p[5] / 255.0);
glVertex3d(p[0], p[1], p[2]);
}
glEnd();
pangolin::FinishFrame();
usleep(5000); // sleep 5 ms
}
return;
}注意在进行拼接的时候,由于照片是由很多个相机共同拍摄的,所以相机系无法统一。因此我们采用转化为世界系的方式来统一坐标系,以便拼接。所以我们就要先求出来相机坐标系下的坐标,也就是求出下面式子的X和 Y。其中αf就是fx,βf就是fy。然后乘一个变换矩阵T就可以转换为世界坐标系。
1.
colorImgs.push_back(cv::imread((fmt % "color" % (i + 1) % "png").str()));
//push_back就是读取的意思。这两行就是在依次读取颜色和深度文件。上面的代码就是再读取颜色信息。
cv::imread 函数是OpenCV库中的函数,用于从文件系统中加载并解码一个图像到内存中,返回一个cv::Mat对象。这里的参数就是上面生成的文件路径字符串。
如何分析(fmt % "color" % (i + 1) % "png").str();?
(fmt % "color" % (i + 1) % "png").str() 将会替换掉前面定义的fmt中的占位符,生成一个完整的文件路径字符串。例如,当i为0时,生成的文件名将是"./color/1.png"。
什么意思呢?比如说我们有这样一个格式化字符串:
boost::format fmt("我喜欢吃%s,特别是%d号的%s披萨。"); 这里的fmt就是一个模板,它有三个占位符%s和一个%d。如果我们想让它变成一个完整的句子,我们需要提供这些占位符的具体值。比如:
std::string food = "披萨";
int number = 4;
std::string type = "海鲜";
std::string sentence = (fmt % food % number % type).str(); 这里,我们用food(字符串"披萨")替换了第一个%s,用number(整数4)替换了%d,再用type(字符串"海鲜")替换了最后一个%s。最后,.str()方法将格式化后的字符串输出。
最终,sentence将变成:"我喜欢吃披萨,特别是4号的海鲜披萨。"所以,我们的代码最后效果就是:第一个%s被替换成字符串"color"。%d被替换成(i + 1)的值,例如如果i是0,则是1。最后一个%s被替换成字符串"png"。所以,如果i是0,最终生成的字符串将是"./color/1.png"。
效果如下:

2.Eigen::Quaterniond(data[6], data[3], data[4], data[5])中data后面的数字是什么?
Eigen::Quaterniond(data[6], data[3], data[4], data[5])
Eigen::Vector3d(data[0], data[1], data[2])data[0],data[1],data[2]:这三个值通常表示相机在世界坐标系中的位置(平移向量),对应于Eigen::Vector3d。data[3],data[4],data[5],data[6]:这四个值表示一个四元数,用于描述相机的姿态(旋转)。其中data[6]是实部。需要注意的是我们需要把实部放在前面!

3.pointcloud.reserve(1000000);的作用是什么?vector不是可以自动分配内存吗?那为什么还要用reverse预留呢?
作用是预先为 pointcloud 向量预留出足够的内存空间,使其能够容纳最多一百万个元素。
reserve的作用是在不改变容器当前大小的情况下,预先分配足够的内存空间来容纳指定数量的元素。在不使用 reserve 的情况下,当向量中的元素数量超过其当前容量时,std::vector 会自动重新分配内存,并将现有元素复制到新的内存地址上。这个过程涉及到内存分配、数据复制等一系列开销较大的操作,特别是在频繁添加元素时,可能会导致多次内存重新分配,从而降低程序的性能。
std::vector 是一个动态数组,它确实具备自动管理内存的能力。当往向量中添加元素时,如果当前的容量不足以容纳新的元素,向量会自动增长(通常是以当前容量的两倍或其他策略增长),并进行必要的内存重新分配和元素复制。这种自动增长机制确保了向量始终有足够的空间来存储元素。
然而,这种自动增长是有代价的,尤其是当向量需要存储大量数据时,频繁的内存重新分配会导致性能下降。因此,在已知将要存储的数据量大致范围的情况下,预先使用 reserve 方法预留内存是一个很好的优化措施。
PS:reserve和Eigen::aligned_allocator有什么区别?(什么是内存对齐?)
这两个都涉及内存管理,但是reserve 的目的是预先分配足够的内存空间,以减少在添加元素时的内存重新分配开销。而Eigen::aligned_allocator 的目的是确保内存对齐,以优化数据访问和计算性能。
那么问题又来了,什么是内存对齐?
内存对齐是指数据在内存中的地址应该满足一定的规则,即数据的起始地址应该是某个特定值的倍数。不同的处理器架构有不同的对齐要求,这些要求通常是为了优化数据访问的速度和效率。假设我们有一个整数(通常为4字节或8字节),处理器要求整数的地址应该是4字节或8字节的倍数。如果一个整数的地址是16(16是4的倍数,如果是8字节整数则应该是8的倍数),那么这个整数就是对齐的;如果地址是15,那么这个整数就没有对齐。
此外,reserve 通常用于一些对性能需求较大的场景,特别是在需要大量连续插入元素时。而Eigen::aligned_allocator 则更多用于需要高速内存访问的科学计算和数值处理任务。reserve 是针对整个向量的容量管理。Eigen::aligned_allocator 是针对单个对象的内存对齐管理。
课后拓展:
Kalibr实现相机标定_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1gA411w7EM/?spm_id_from=333.337.search-card.all.click张正友标定法_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1gA411w7EM/?spm_id_from=333.337.search-card.all.click张正友标定法_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1k3411T73d/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109 了解matlab和opencv如何标定相机,知道各种标定方法的精度和流程区别
https://www.bilibili.com/video/BV1k3411T73d/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109 了解matlab和opencv如何标定相机,知道各种标定方法的精度和流程区别
Matlab相机标定——使用Single Camera Calibrator App-CSDN博客文章浏览阅读1.9w次,点赞22次,收藏245次。1. 棋盘格图片采集Single Camera Calibrator App支持棋盘格、圆圈格和自定义检测器图案。有关这些图案的细节和包含可打印图案的PDF文件,请参见校准图案。(1)本文选择棋盘格图案,打开matlab,命令行输入:open checkerboardPattern.pdf棋盘式图案是最常用于相机校准的校准图案。这种模式的控制点是位于棋盘内的角。由于角落非常小,它们通常不受透视和镜头失真的影响。校准器应用程序还可以检测部分棋盘,这在校准带有广..._matlab相机标定https://blog.csdn.net/weixin_44709392/article/details/124486048
opencv标定详细用法_opencv相机标定参数中的squaresize表示什么-CSDN博客![]() https://blog.csdn.net/zhiyuan2021/article/details/125316633
https://blog.csdn.net/zhiyuan2021/article/details/125316633
此外:
可以学习一下C++/Cmake/ros,以及opencv库的基本使用(opencv比较常用!!)
还有docker
参考资料:
本博客参考于B站Up主全日制学生混的SLAM课程并结合网络资源进行了更为详细的注释。
由于本人水平有限,有错误或补充的还请各位在评论区交流指正。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









