







IronOCR is an advanced OCR (Optical Character Recognition) library for C# and .NET
IronOCR provides Tesseract OCR on Mac, Windows, Linux, Azure and Docker for:
- .Net Framework 4.0 +
- .Net Standard 2.0 +
- .Net Core 2.0 +
- .Net 5
- Mono for MacOS and Linux
- Xamarin for MacOS
IronOCR reads Text, Barcodes & QR from all major image and PDF formats using the latest Tesseract 5 engine. This library adds OCR functionality to Desktop, Console and Web applications in minutes.
IronOCR's Unique Features
- Pure .Net OCR API
- All OCR tasks run locally (no SAAS)
- 125 languages
- Barcode & QR Code reading
- Corrects low quality, noisy and distorted scans
- Performance tuned above and beyond any other known build of Tesseract OCR.
- Reads PDFs and multi-page TIFFs
- Can save any OCR Scan to a searchable PDF document or XHTML
Data Output Options Include
Output Plain Text, Barcode Data and an OCR Result class containing paragraphs, lines, words, and characters.
International Language Support
125 Languages supported including Arabic, Chinese, English, Finnish, French, German, Hebrew, Italian, Japanese, Korean, Portuguese, Russian, Spanish... Custom language packs can also be created.
Licensing & Support available
For code examples, documentation & more visit C# OCR Library [125 Languages Supported] | Iron OCR Email: developers@ironsoftware.com
Get Started Code Example
string Result = new IronOcr.IronTesseract().Read("scan.pdf").Text;
Why C# developers choose IronOCR over Vanilla Tesseract:
- Achieve 99.8%+ OCR accuracy without using external web services.
- Includes for Tesseract 5 , 4 and 3 Engines out of the box.
- Blazing Speed and MultiThreading
- MVC, WebApp, Desktop, Console & Server Application compatible
- No Exes or C++ code to work with
- Full PDF OCR support
- To perform OCR an almost any Image file or PDF
- Full .Net Core, Standard and FrameWork support
- Deploy on Windows, Mac, Linux, Azure, Docker, Lambda, AWS
- Read barcodes and QR codes
- Export OCR as to XHTML
- Export OCR to searchable PDF documents
- Multithreading support
- 125 international languages all managed via Nuget or OcrData files
- Extract Images, Coordinates, Statistics and Fonts. Not just text.
- Can be used to redistribute Tesseract OCR inside commercial & proprietary applications.
- Supports:

IronOCR shines when working with real world images and imperfect documents such as photographs, or scans of low resolution which may have digital noise or imperfections. Other free OCR libraries for the .NET platform such other .Net Tesseract APIs and web services do not perform so well on these real world use cases.
OCR with Tesseract 5 - Start Coding in C#
These code examples below shows how easy it is to read text from an image using C# or VB .NET.
Configurable Hello World
using IronOcr;
var Ocr = new IronTesseract();
using (var Input = new OcrInput()){
Input.AddImage("images/sample.jpeg")
//... you can add any number of images
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}
C# PDF OCR
The same approach can similarly be used to extract text from any PDF document.
var Ocr = new IronTesseract();
using (var input = new OcrInput())
{
input.AddPdf("example.pdf","password");
// We can also select specific PDF page numnbers to OCR
var Result = Ocr.Read(input);
Console.WriteLine(Result.Text);
Console.WriteLine($"{Result.Pages.Count()} Pages");
// 1 page for every page of the PDF
}
C# OCR Working Code Examples
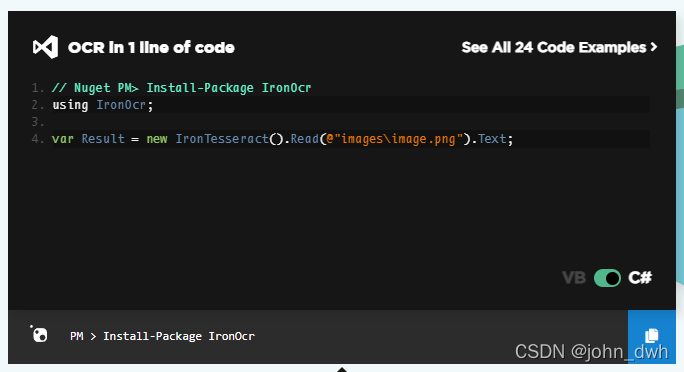
- OCR in 1 line of code
- PDF OCR Text Extraction
- OCR with Barcode & QR Reading
- 125 International OCR Languages
- Fixing Low Quality Scans & Images
- Fast OCR Configuration
- OCR Image Optimization Filters
- OcrResult Class
- Create Searchable PDFs by OCR
- Tesseract 5 for .NET
- Tesseract 4 for .NET
- Tesseract 3 Legacy for .NET
- Tesseract Detailed Configuration
- OcrInput Class
- OCR a Region of an Image
- TIFF to Searchable PDF Converter
- Image Resolution Optimization (DPI)
- MultiThreaded Tesseract OCR
- OCR for MultiPage TIFF Files
- Make any PDF have Searchable, Copyable Text
- Using Custom Tesseract Language Files
- Multiple Languages for 1 Document
- Exporting Images of OCR Elements

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









