






Linux进程控制
进程创建
我们对上节课的知识
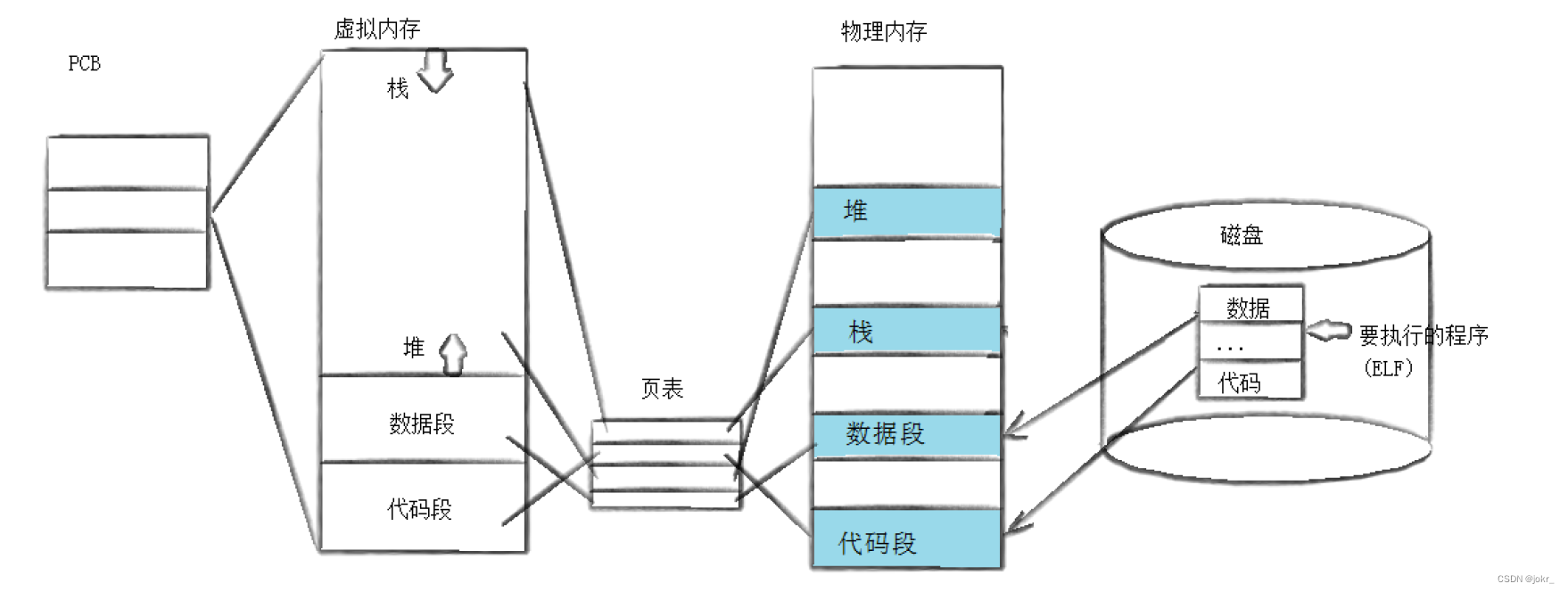
进程的地址空间: 我们平时在语言层上面访问到的地址都是虚拟地址,进程在访问虚拟地址时经过页表转化到物理地址,看不到物理地址。
当父子进程访问一个共享变量时,会发生写时拷贝问题, 拷贝过程中,物理地址发生变化,虚拟地址不变化,故在语言层变量来看,同一个虚拟地址访问到了不同的物理地址即访问的变量值不同。
为什么存在虚拟地址空间 时代发展的产物,刚开始没有,后来出于进程安全,模块分离角度看,必须存在虚拟地址空间。
将进程调度和内存解耦进行管理,让我们对应的进程访问地址时,内存时,以同一的视角访问,另外虚拟内存加页表,对我们的进程对应的内存操作,进行软硬件操控,对不合理的请求直接而截止,页表可以对我们的指定内存区域进行限设定。
fork函数再识
我们再上一节已经了解了fork()函数的相关信息: 它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
返回值:
- 父进程若创建成功,则返回子进程的PID,若失败,则返回-1.
- 子进程返回0.
那为什么父进程创建成功返回的是子进程的PID呢?
首先是为了与父进程做区分,其次父进程通过得到子进程的PID,可以对子进程进行控制和管理。比如后续讲到的发送信号等等操作。
那么在进程调用了fork()后,Linux内核都做了那些事情呢?
-
分配PID:内核为新的进程分配一个唯一的进程标识符(PID)。在多任务操作系统中,每个进程都有一个唯一的PID。
-
复制进程上下文:内核将父进程的进程控制块(PCB)复制到子进程中。PCB包含了进程的状态信息,如寄存器状态、进程的优先级、进程的状态、程序计数器、内存限制、文件描述符、信号处理状态等。
具体有:创建子进程的进程控制块task_struct,创建子进程的进程地址空间mm_struct,建子进程对应的页表等。 -
复制地址空间:内核将父进程的地址空间复制给子进程。这通常通过写时复制(Copy-On-Write, COW)技术来实现,以提高效率和节省内存。在COW机制下,父进程和子进程共享相同的物理内存页,直到其中一个进程尝试写入,这时才真正复制内存页。
-
设置返回值:内核设置fork()的返回值。在父进程中,fork()返回新创建的子进程的PID;在子进程中,fork()返回0。
-
调度子进程:内核将子进程添加到调度队列中,这样当调度器下次运行时,子进程就有机会被执行。
-
复制信号处理:子进程继承了父进程的信号处理设置。这意味着,除了不能继承的特定信号外,子进程将具有与父进程相同的信号处理程序。
在fork()之后,用户空间就会多出来一个子进程,如下图:
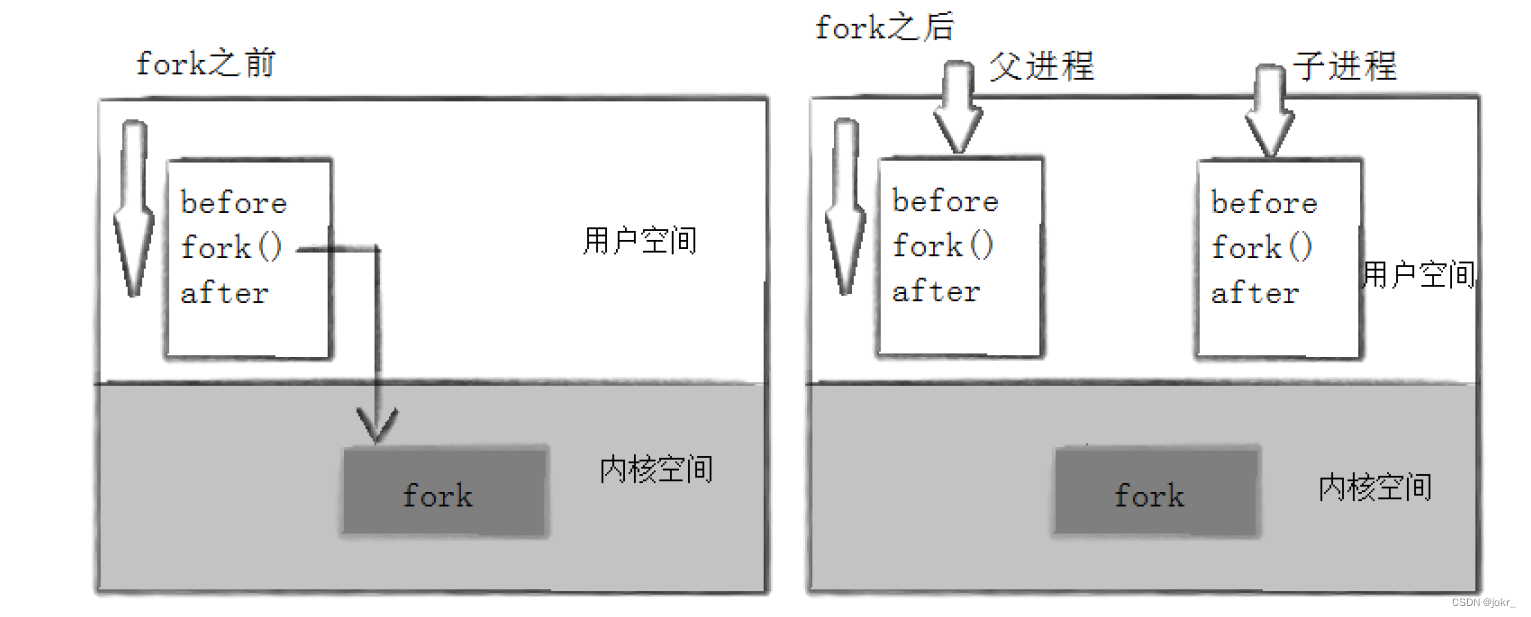
fork函数返回值
猜猜下面这个代码的运行结果是什么样的呢?
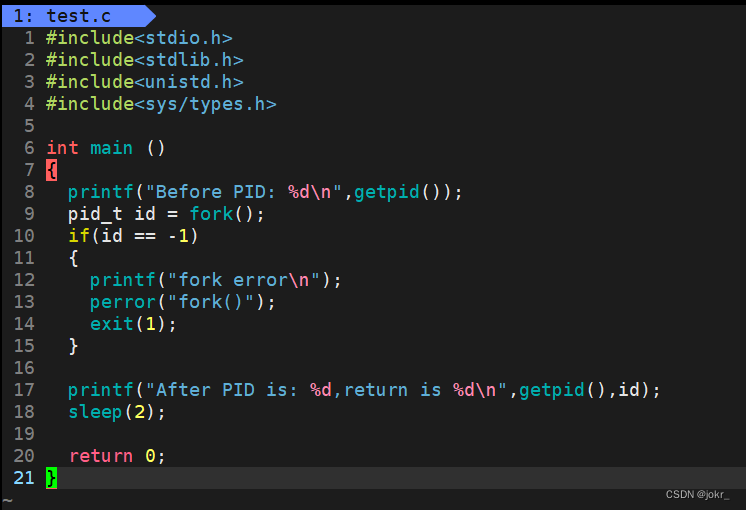
结果如下:

为什么这里的Before只打印了一遍,可是After打印了两编呢?
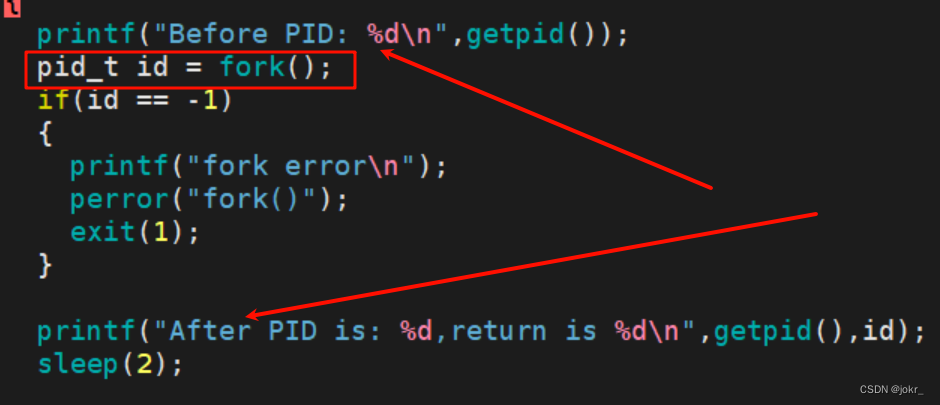
我们可以观察到,两次After的PID是不一样的,,但是第一个After的return值与第二个After的PID相同,所以我们根据上面的知识可以猜测到:第一个After是父进程,第二个是子进程。
并且观察这个图,可以知道Before在fork之前,而After在fork()之后,所以才导致了Before只有打印一遍,而After打印了两遍。
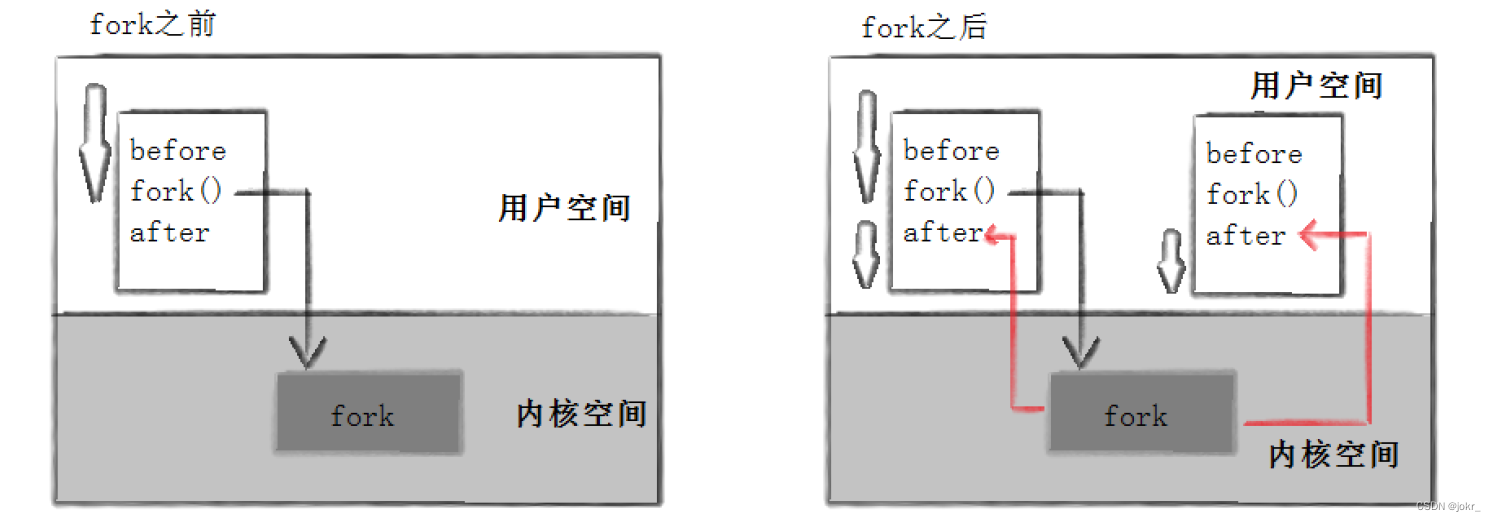
注意: fork之后,谁先执行完全由调度器决定。
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
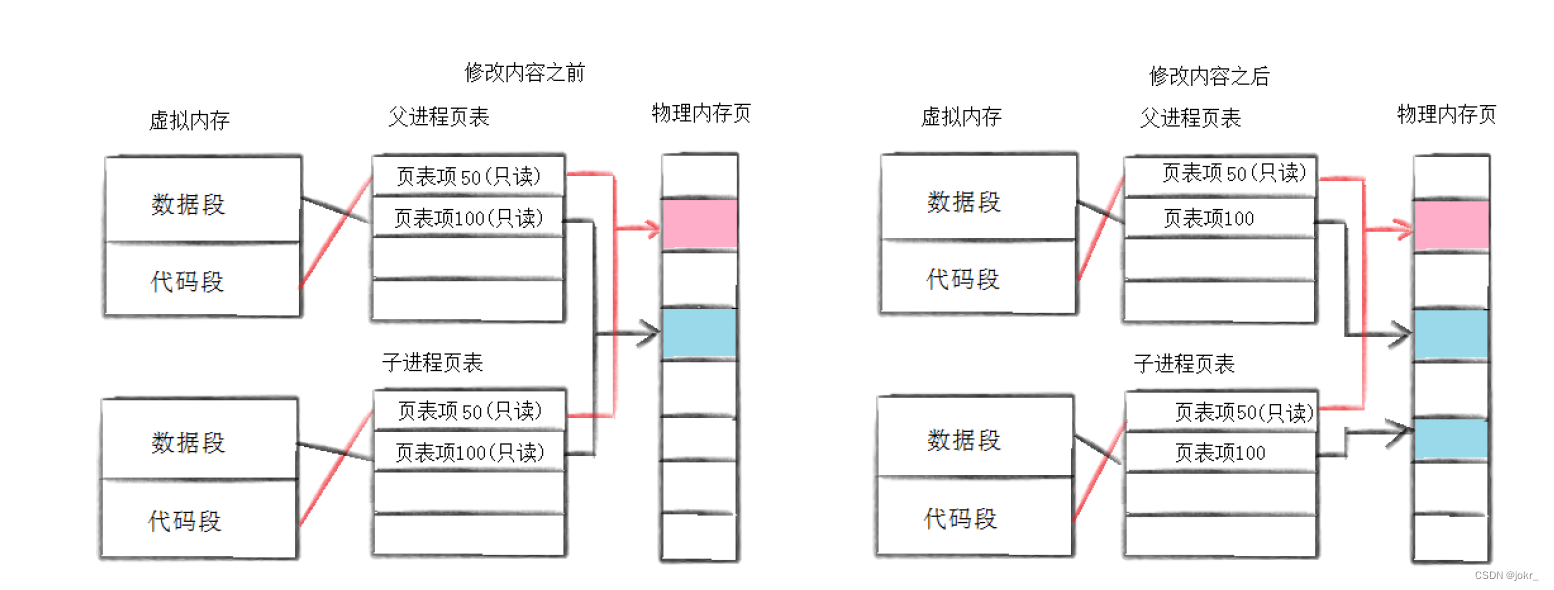
fork常规用法
- 进程创建: fork的最直接用途是创建新的进程。它会创建一个与父进程几乎完全相同的子进程,包括代码、堆、栈和数据段的复制。不过,子进程会获得一个全新的进程标识符(PID)。
- 并发执行:通过fork可以实现程序的并发执行。父进程可以使用fork创建多个子进程,每个子进程可以独立地执行不同的任务或者同一任务的不同部分。
- 父子进程通信:fork后,父子进程可以通过管道、信号、共享内存、消息队列等多种机制进行通信。
- 实现守护进程:fork可以用来创建守护进程(Daemon)。一般做法是父进程先fork一个子进程然后退出,子进程继续fork第二个子进程后自己也退出,这时第二个子进程没有终端关联,可以作为守护进程运行。
- 执行新程序:fork通常与exec系列函数结合使用,fork负责复制进程,而exec用于在子进程中加载新的程序。这种方式允许程序在运行时动态地执行其他程序。
- 资源共享和复制:在fork之后,父子进程会共享某些资源,如文件描述符。但是,它们的地址空间是独立的。对于内存的修改,现代操作系统通常采用写时复制(Copy-On-Write, COW)技术,以优化性能和内存使用。
- 测试和调试:开发者有时使用fork来创建一个进程的副本,以便在一个安全的、与原进程隔离的环境中测试代码或进行调试。
fork调用失败的原因
-
内存不足: 如果系统没有足够的空闲内存来为子进程的运行环境(包括代码、数据、堆和栈等)分配空间,fork调用将失败。这是最常见的原因之一。
-
进程数量达到上限: 操作系统对可以创建的进程数量有限制。如果系统中的进程数已经达到了这个上限,新的fork调用将失败。每个用户和整个系统都可能有各自的进程数限制。
进程终止
进程退出场景
一个进程的终止,是要做什么呢
- 释放曾经的代码和数据所占据的空间
- 释放内核数据结构
那一个代码进程退出的结果都有几种可能呢?
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
进程退出
我们都知道,一个main()函数,最终都要return 0,但是为什么我们要return的数字是 0 呢? 而且这个return 有什么意义呢?
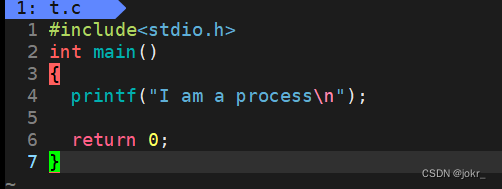
这段代码的运行如下图:

这里我们了解一下ecco $?
echo $?用来显示最后一条命令的退出状态。退出状态,或称退出码(Exit Status/Exit Code),是一个整数值,用于表示一个命令、脚本或程序执行完毕后的最终结果。

那我吧上面的代码的return值改为100呢?
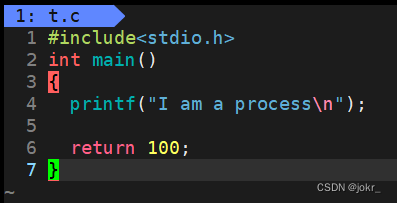

那么用echo $? 打印出来的也就是100了
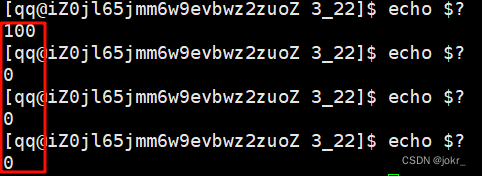
为什么后面几个 echo $?都是0呢?
因为:内建命令,打印的都是bash内部的变量数据,我们刚刚所运行的进程都是bash的子进程,而且执行 echo $?的时候bash会创建一个进程,而默认的退出码是 0,所以后续打印出来的都是 0。
注意:从逻辑上讲,每次执行
echo $?命令看作是启动了一个“进程”,但实际上,内建命令如echo的执行并不一定会创建一个新的进程。它们是由当前的shell进程直接处理的。这种处理方式是优化性能的一种手段,避免了频繁地创建和销毁进程所带来的开销。
那么为什么要存在这个退出码呢?
退出码(或称为退出状态、返回码)是程序完成执行后返回给操作系统的一个小的整数值。这个机制是操作系统用来接收一个程序完成工作后状态的一种方式,它为程序间的交互、错误处理和脚本控制提供了基础。
我们规定,退出码的 0 代表代码执行成功,而 !0 则代表代码执行失败。
但这又是为什么呢?
这里面有一些历史原因。
但是从逻辑上讲 0 表示成功, 但是一个程序的失败的原因可能不止一种,所以我们可以使用 !0 值来表示失败的原因,比如 1 2 3 4 5… 每一个数字表示一种失败的原因。
这里c语言提供了一个函数strerror() 来将每一个 !0 对应的错误转化为string ,并打印出来:
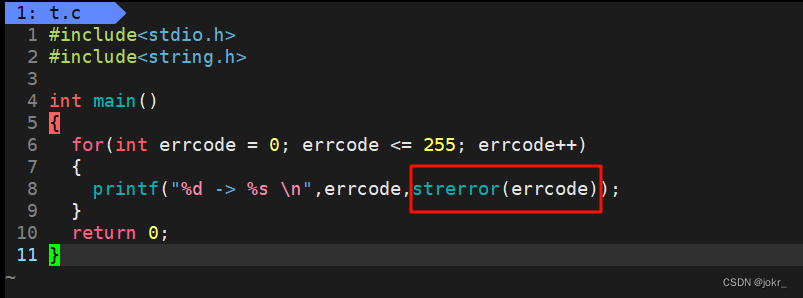
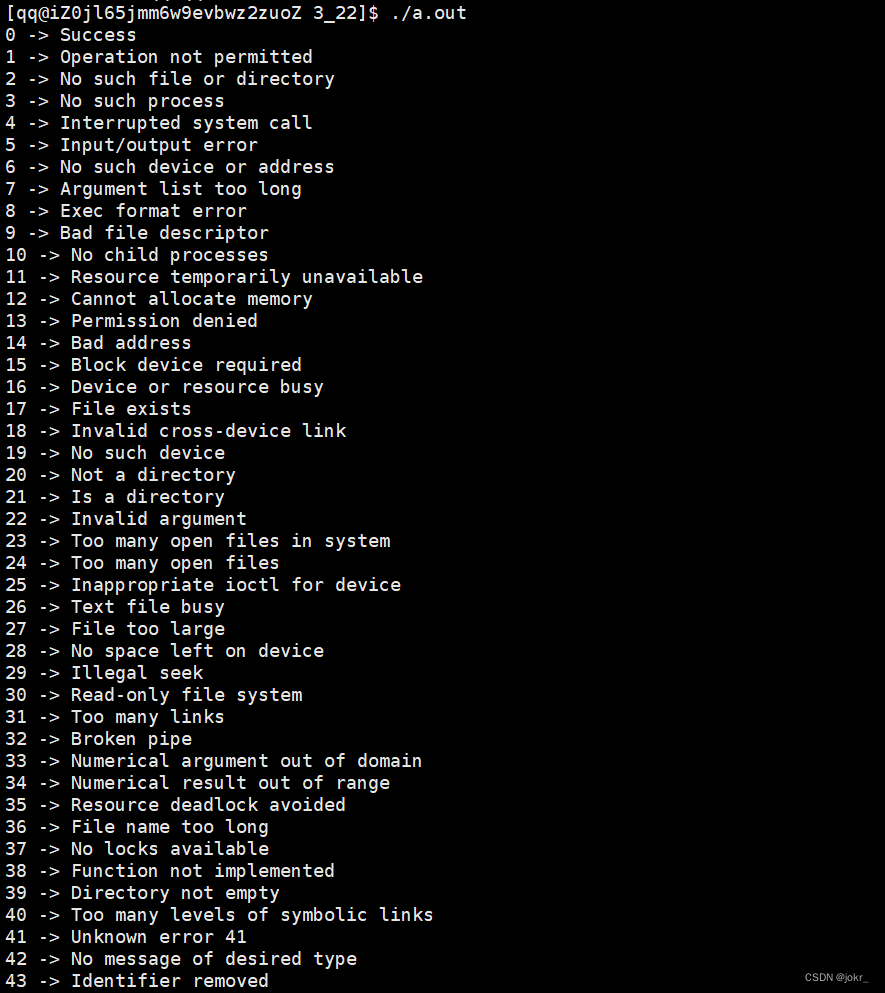
退出码可以使用默认的,也可以自定义!
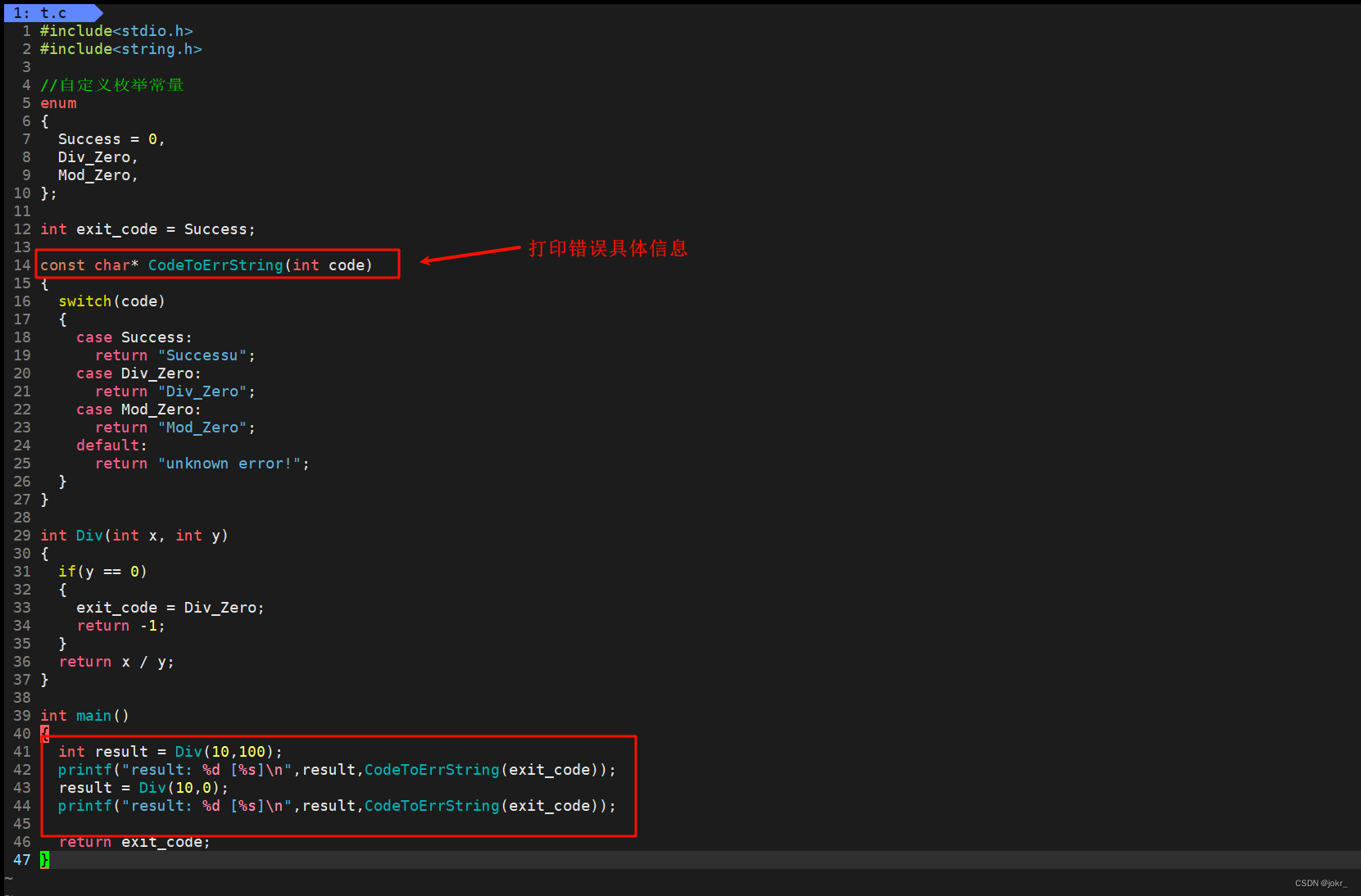
上面这个程序,自定义了出错码,即当除数为0时,返回-1,并且报错Div_Zero。
一个代码如果能够正常跑完,不论结果是否正确,具体情况我们可以根据退出码来来判断。
但是如果当我们的代码出现异常的时候,程序会直接崩溃,我们看不到退出码,此时这个退出码就没有了意义。
我们举个例子当我们在做数组的越界访问,或者访问一个野指针的时候就会出现奔溃,底层就是操作系统捕获到了你的非法请求,OS杀死了这个进程。
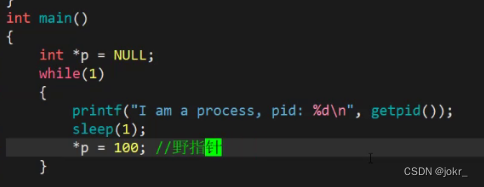
当我们访问野指针,那这个程序肯定就会崩溃:

这是因为OS给我们的进程发送了信号,截止了这个进程。
我们也可以通过给某i一个信号输入SIGSEGV 信号,提前终止这个进程。

所以,以后我们可以根据进程退出的时候的退出信号是多少,就可以判断进程为什么异常了!!!

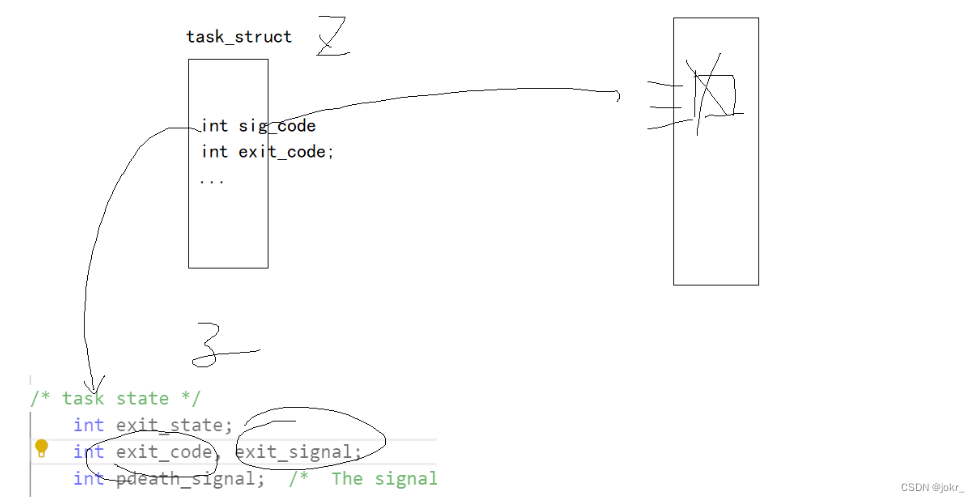
最后,当一个子进程退出的时候,进入僵尸状态(Z),此时的sig_code 和exit_code 里面保留了需父进程读取的信息,所以这就是为什么一个子进程退出时不立即释放自己pcb的原因。
- sig_code(Signal Code):如果子进程由于接收到信号而退出,sig_code保存了信号的编号,用于指示导致子进程终止的具体原因。父进程可以通过检查sig_code来了解子进程是因为什么原因退出的,进而采取相应的处理措施。
- exit_code(Exit Code):如果子进程正常退出(即未接收到信号),exit_code保存了子进程的退出状态。通常,子进程会调用exit()或返回一个整数值来指示其退出状态。父进程可以通过检查exit_code来了解子进程的退出状态,并根据需要进行处理。
exit函数
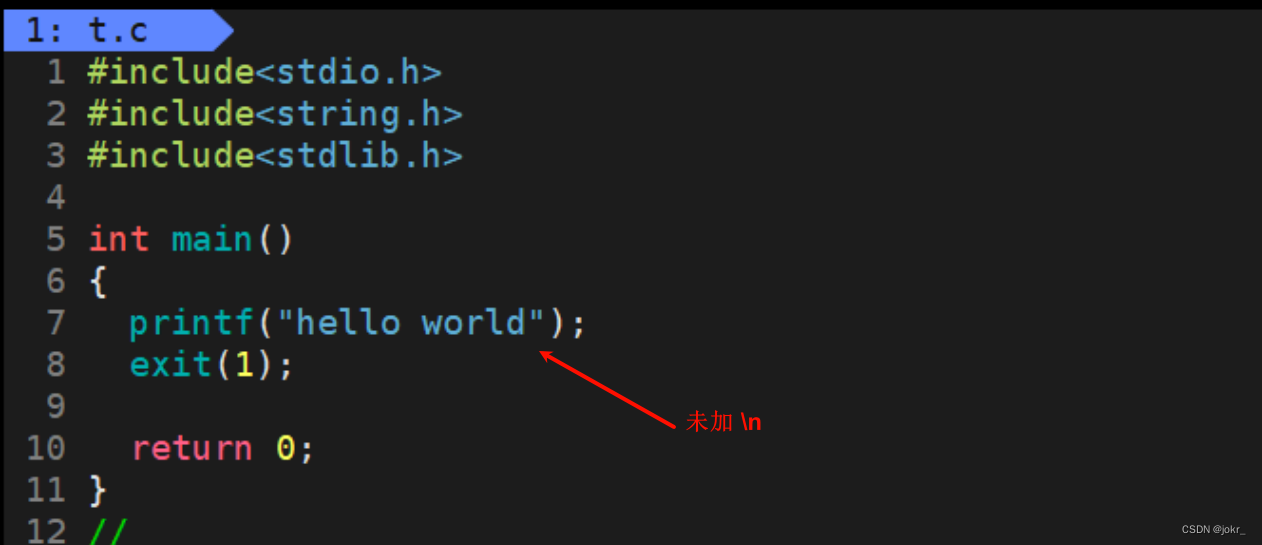
使用exit函数退出进程也是我们常用的方法,exit函数可以在代码中的任何地方退出进程,并且exit函数在退出进程前会做一系列工作:
- 执行用户通过atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入。
- 调用_exit函数终止进程。
例如,以下代码中exit终止进程前会将缓冲区当中的数据输出。
结果:
这里打印出了"hello world"。
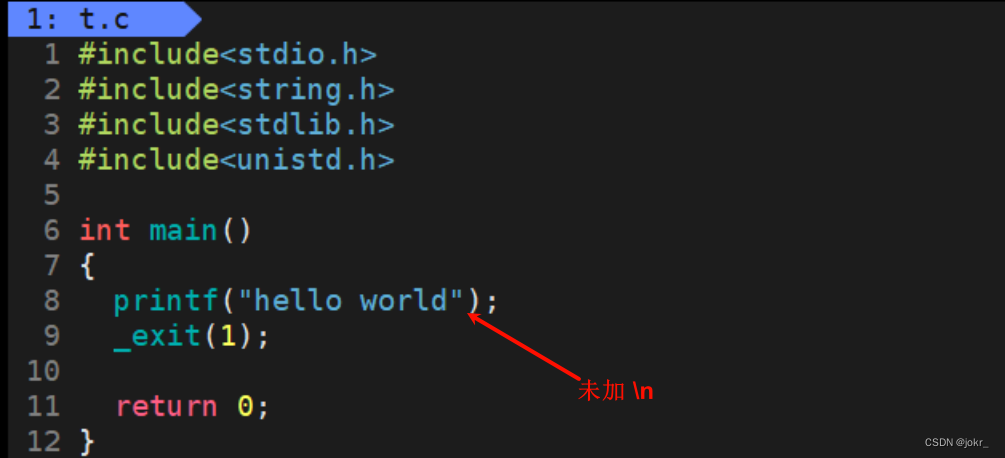
_exit函数
使用_exit函数退出进程的方法我们并不经常使用,_exit函数也可以在代码中的任何地方退出进程,但是_exit函数会直接终止进程,并不会在退出进程前会做任何收尾工作。
例如,以下代码中使用_exit终止进程,则缓冲区当中的数据将不会被输出。
结果:

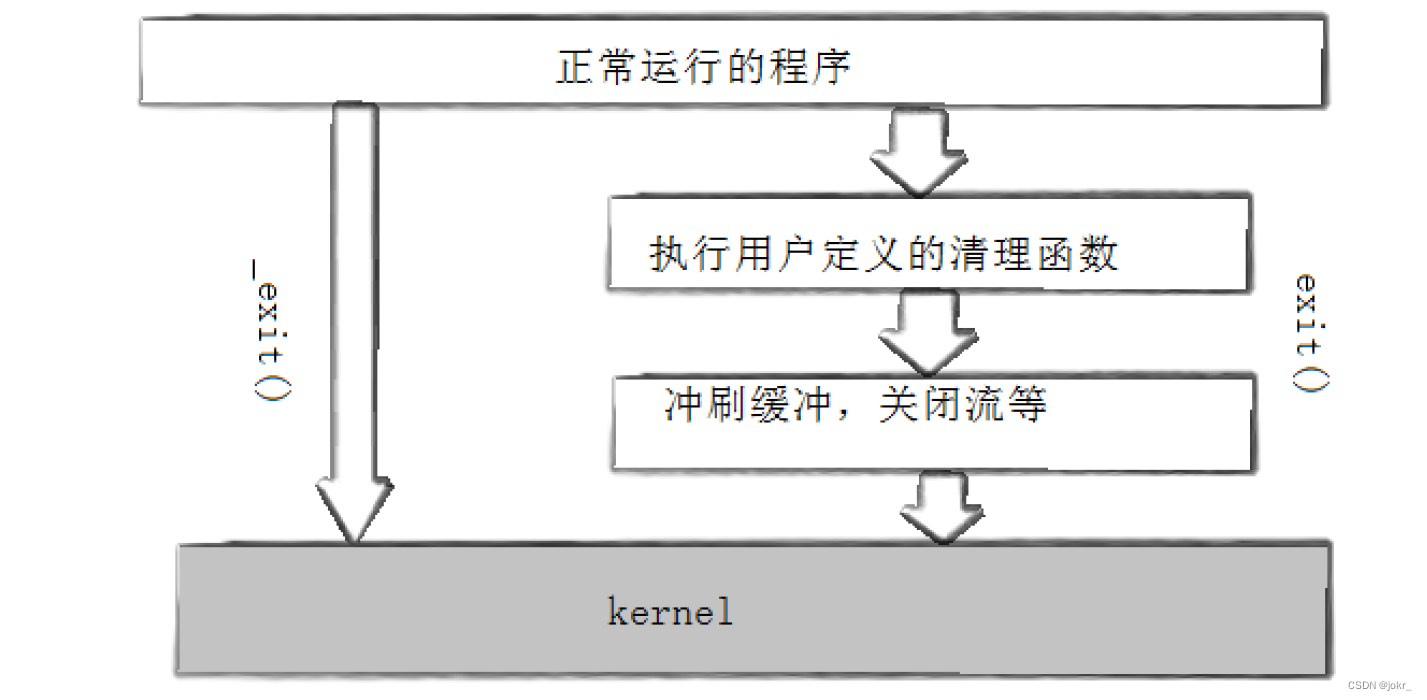
return、exit和_exit之间的区别与联系
只有在main函数当中的return才能起到退出进程的作用,子函数当中return不能退出进程,而exit函数和_exit函数在代码中的任何地方使用都可以起到退出进程的作用。
使用exit函数退出进程前,exit函数会执行用户定义的清理函数、冲刷缓冲,关闭流等操作,然后再终止进程,而_exit函数会直接终止进程,不会做任何收尾工作。
执行return num等同于执行exit(num),因为调用main函数运行结束后,会将main函数的返回值当做exit的参数来调用exit函数。
使用exit函数退出进程前,exit函数会先执行用户定义的清理函数、冲刷缓冲,关闭流等操作,然后再调用_exit函数终止进程。
进程等待
进程等待的必要性
- 子进程退出,父进程如果不读取子进程的退出信息,子进程就会变成僵尸进程,进而造成内存泄漏。
- 进程一旦变成僵尸进程,那么就算是kill -9命令也无法将其杀死,因为谁也无法杀死一个已经死去的进程。
- 对于一个进程来说,最关心自己的就是其父进程,因为父进程需要知道自己派给子进程的任务完成的如何。
- 父进程需要通过进程等待的方式,回收子进程资源,获取子进程的退出信息
获取子进程status
下面我们来了解两个函数:wait 和 waitpid 。
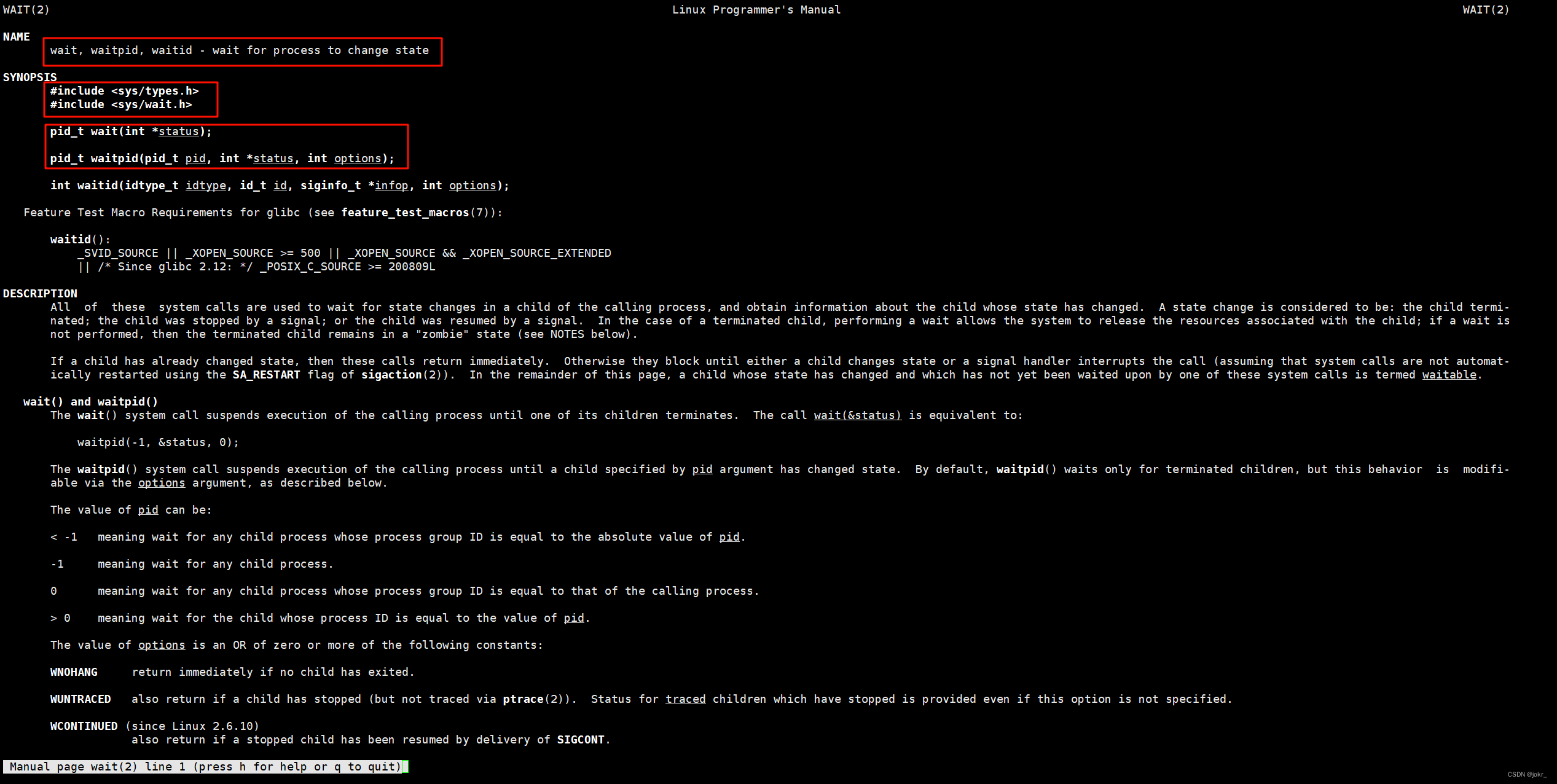
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
这两个函数都有一个参数叫作 status ,该参数是一个输出型参数,由操作系统进行填充。
如果对status参数传入NULL,表示不关心子进程的退出状态信息。否则,操作系统会通过该参数,将子进程的退出信息反馈给父进程。
status是一个整型变量,但status不能简单的当作整型来看待,status的不同比特位所代表的信息不同,具体细节如下(只研究status低16比特位):

在status的低16比特位当中,高8位表示进程的退出状态,即退出码。进程若是被信号所杀,则低7位表示终止信号,而第8位比特位是core dump标志。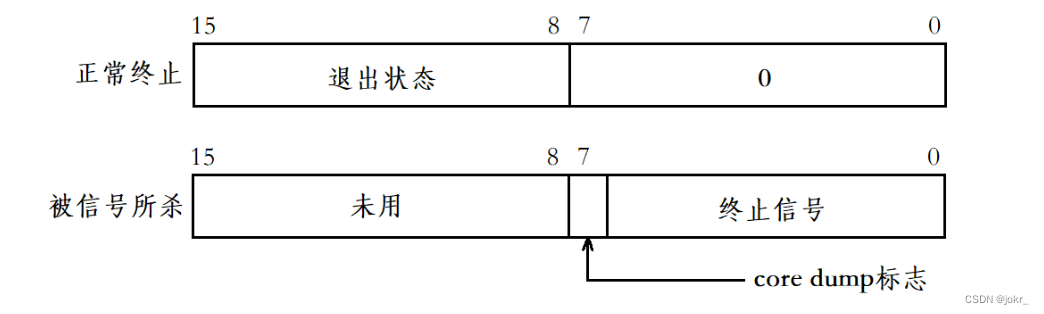
我们通过一系列位操作,就可以根据status得到进程的退出码和退出信号
exitCode = (status >> 8) & 0xFF; //退出码
exitSignal = status & 0x7F; //退出信号
对于此,系统当中提供了两个宏来获取退出码和退出信号。
- WIFEXITED(status):用于查看进程是否是正常退出,本质是检查是否收到信号。
- WEXITSTATUS(status):用于获取进程的退出码。
exitNormal = WIFEXITED(status); //是否正常退出
exitCode = WEXITSTATUS(status); //获取退出码
当一个进程非正常退出时,说明该进程是被信号所杀,那么该进程的退出码也就没有意义了。
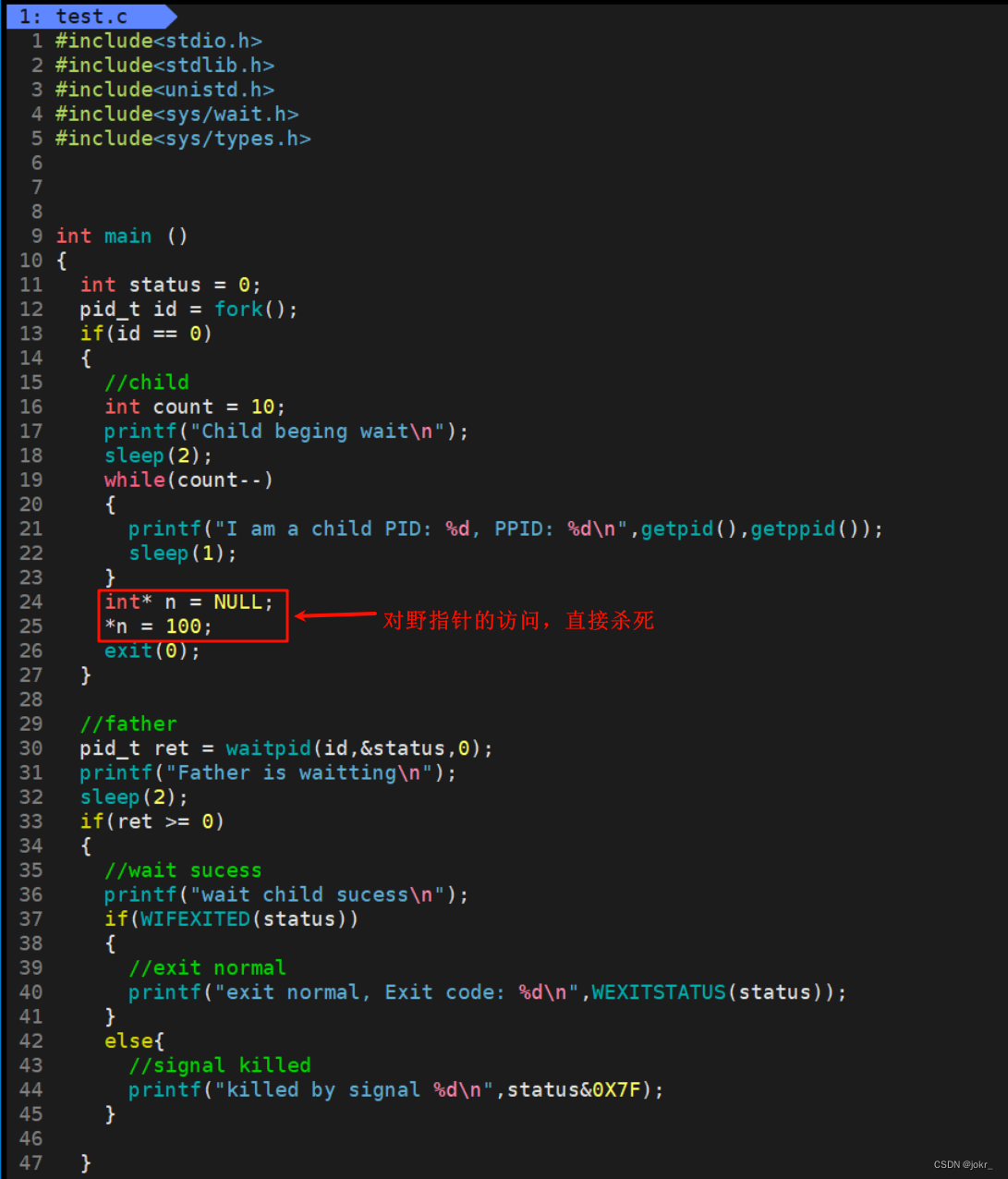
进程等待的方法
wait方法
创建子进程后,父进程可使用wait函数一直等待子进程,直到子进程退出后读取子进程的退出信息:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if(id == 0){
//child
int count = 10;
while(count--){
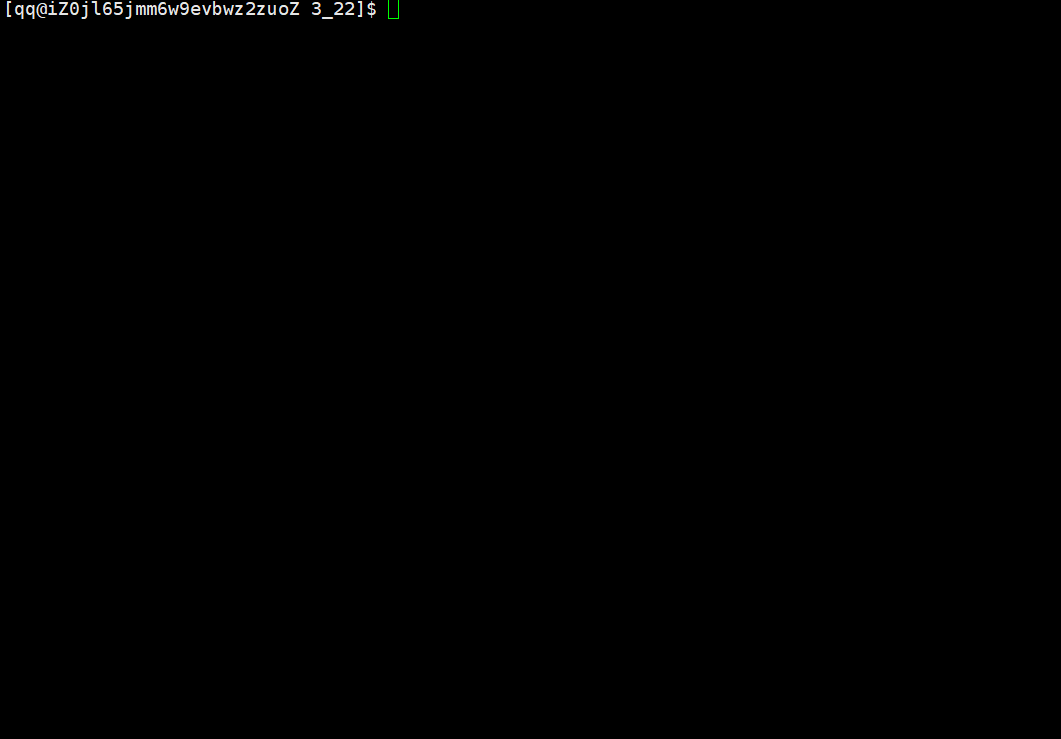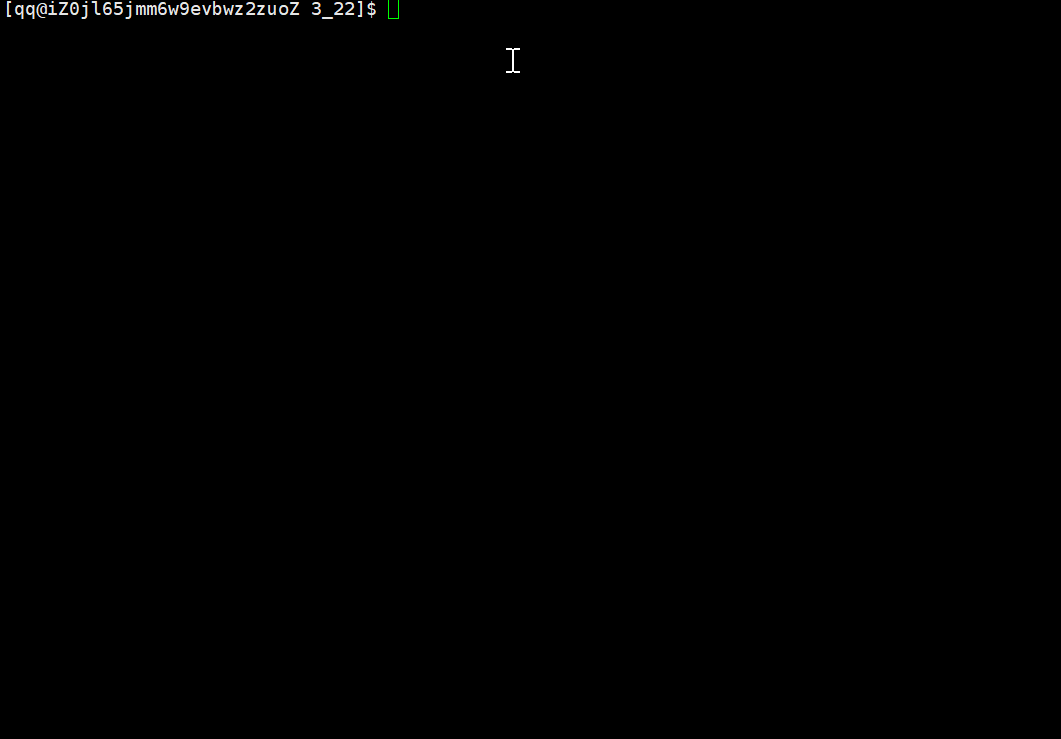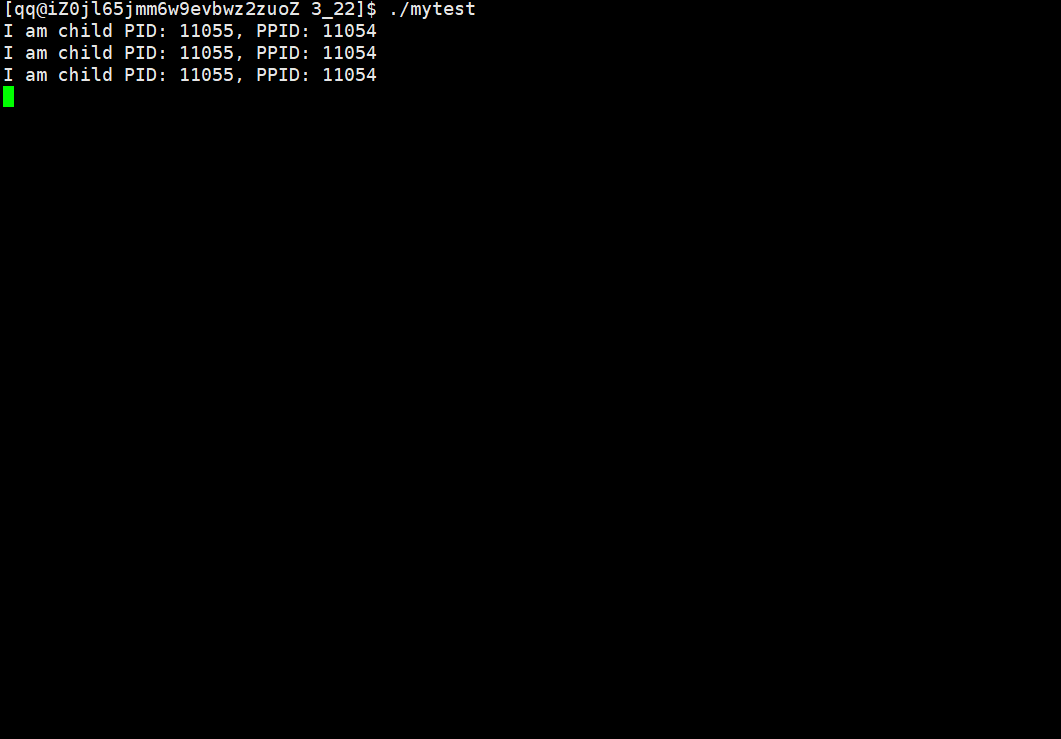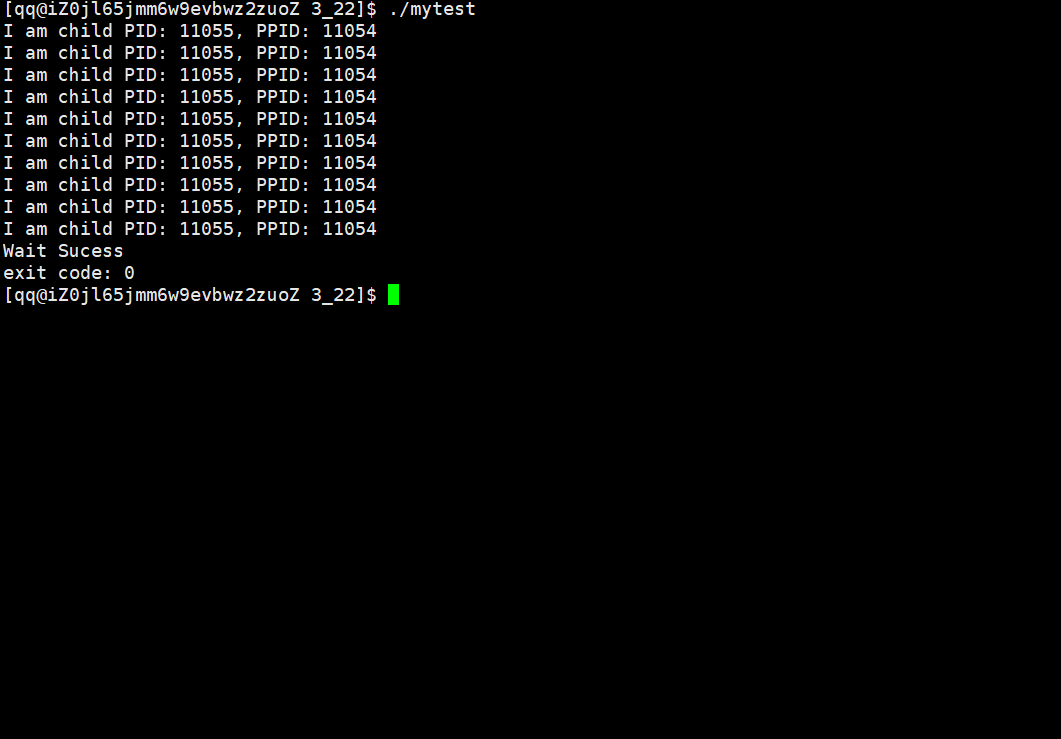
printf("I am child...PID:%d, PPID:%d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
//father
int status = 0;
pid_t ret = wait(&status);
if(ret > 0){
//wait success
printf("wait child success...\n");
if(WIFEXITED(status)){
//exit normal
printf("exit code:%d\n", WEXITSTATUS(status));
}
}
sleep(3);
return 0;
}
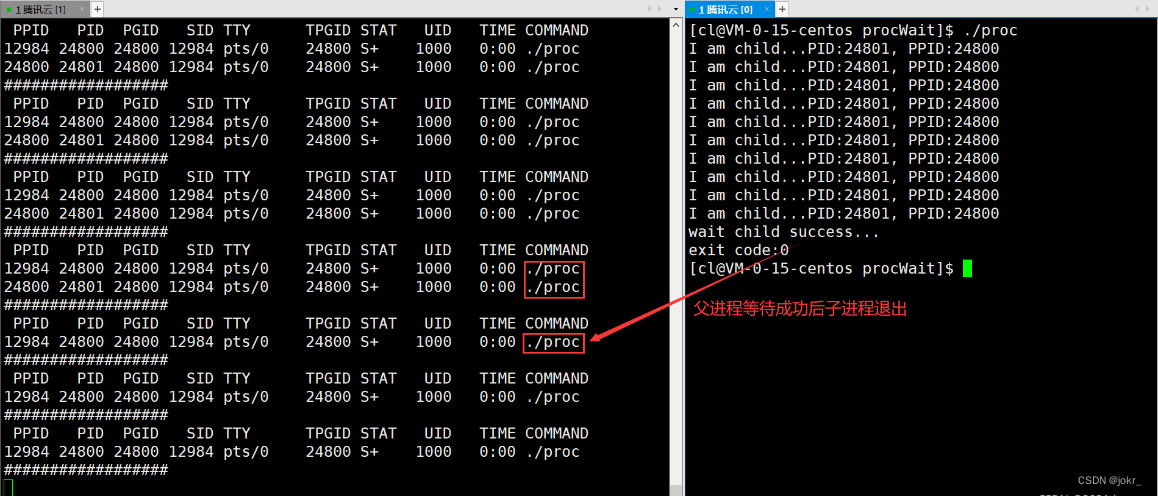
这时我们可以看到,当子进程退出后,父进程读取了子进程的退出信息,子进程也就不会变成僵尸进程了。

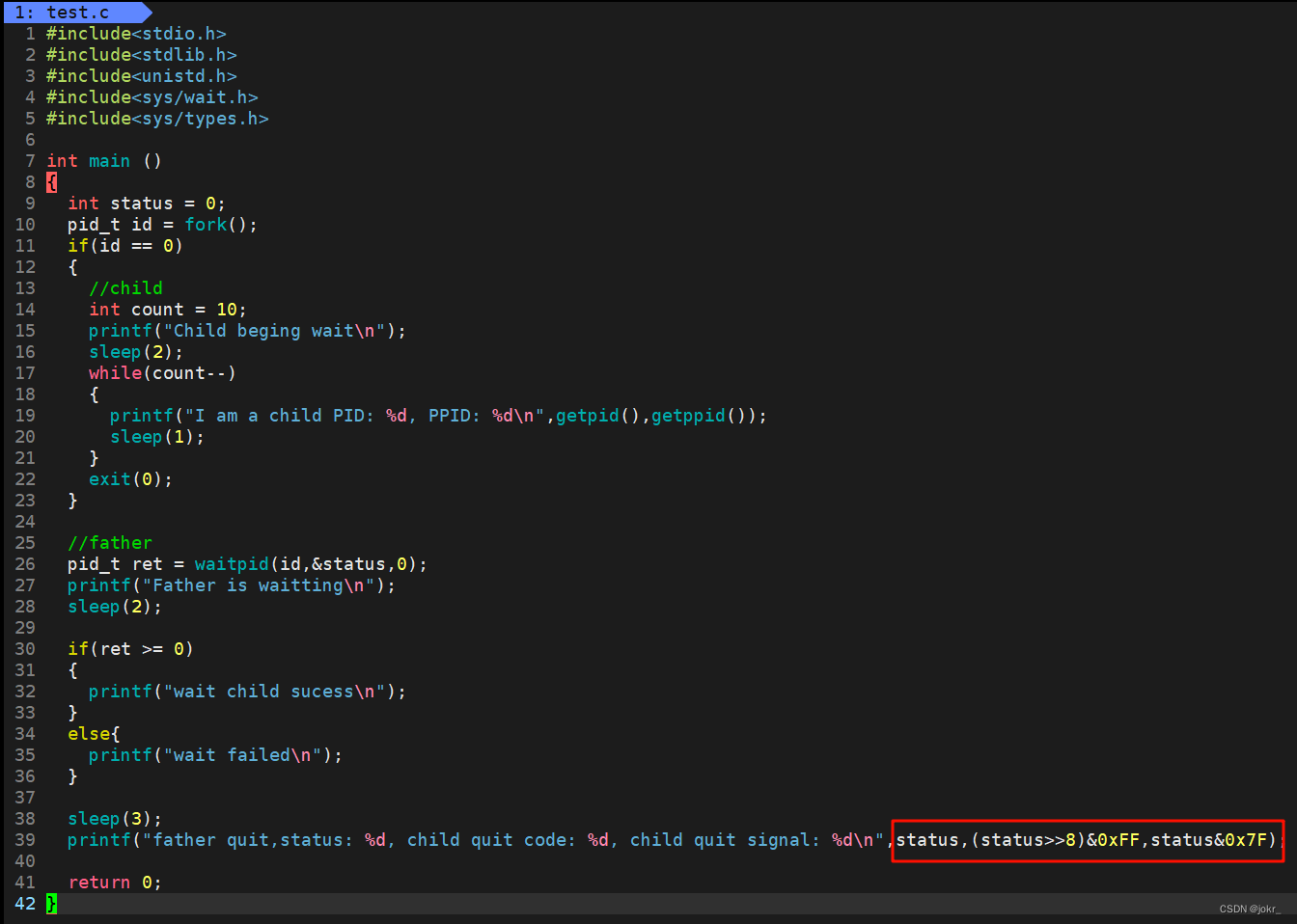
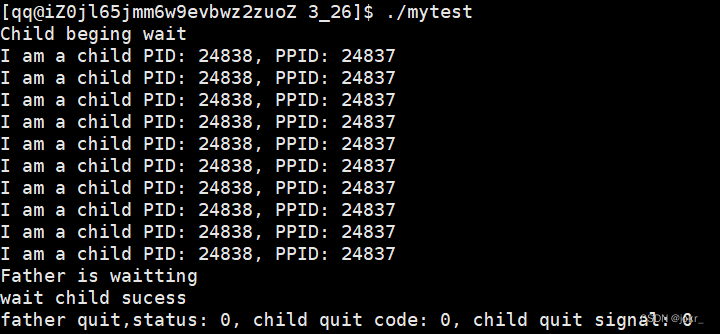
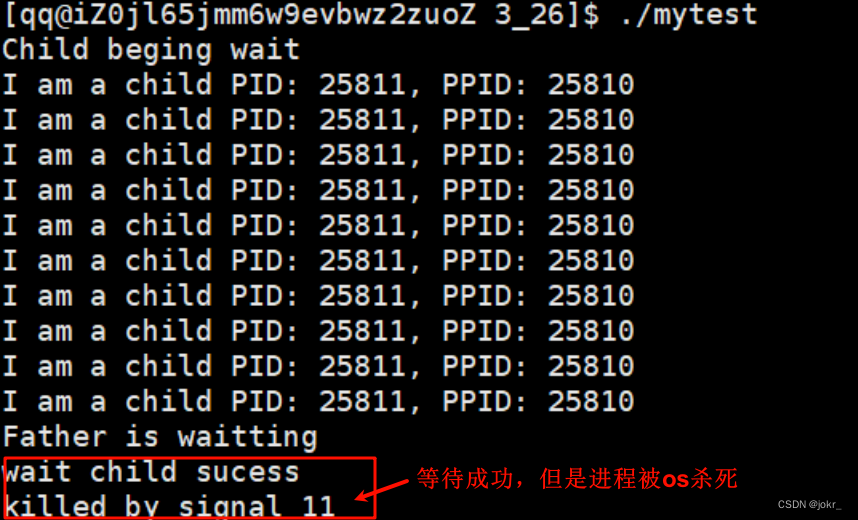
waitpid方法
相关参数:
1、pid:待等待子进程的pid,若设置为-1,则等待任意子进程。
2、status:输出型参数,获取子进程的退出状态,不关心可设置为NULL。
3、options:当设置为WNOHANG时,若等待的子进程没有结束,则waitpid函数直接返回0,不予以等待。若正常结束,则返回该子进程的pid。
创建子进程后,父进程可使用waitpid函数一直等待子进程(此时将waitpid的第三个参数设置为0),直到子进程退出后读取子进程的退出信息。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if (id == 0){
//child
int count = 10;
while (count--){
printf("I am child...PID:%d, PPID:%d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if (ret >= 0){
//wait success
printf("wait child success...\n");
if (WIFEXITED(status)){
//exit normal
printf("exit code:%d\n", WEXITSTATUS(status));
}
else{
//signal killed
printf("killed by siganl %d\n", status & 0x7F);
}
}
sleep(3);
return 0;
}
在父进程运行过程中,我们可以尝试使用kill -9命令将子进程杀死,这时父进程也能等待子进程成功。

阻塞等待和非阻塞等待
操控者: 操作系统
阻塞的本质: 父进程从运行队列放入到了等待队列,也就是把父进程的PCB由R状态变成S状态,这段时间不可被CPU调度器调度
等待结束的本质: 父进程从等待队列放入到了运行队列,也就是把父进程的PCB由S状态变成R状态,可以由CPU调度器调度
- 阻塞等待: 父进程一直等待子进程退出,期间不干任何事情
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include<sys/types.h>
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
// 如果fork失败
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) {
// 子进程
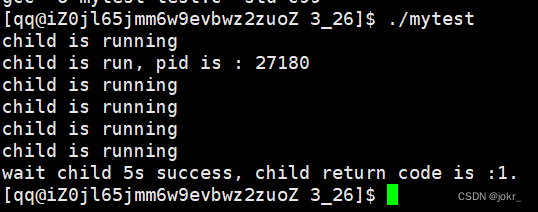
printf("Child is running, pid is: %d\n", getpid());
sleep(5); // 让子进程睡眠5秒钟
exit(257); // 子进程退出,返回257作为退出码
} else {
// 父进程
int status = 0;
pid_t ret = waitpid(-1, &status, 0); // 父进程阻塞式等待任一子进程退出
printf("This is test for wait\n");
if (WIFEXITED(status) && ret == pid) {
// 如果子进程正常退出,并且waitpid返回的PID与子进程的PID相匹配
printf("Wait child 5s success, child return code is: %d.\n", WEXITSTATUS(status));
} else {
// 子进程非正常退出或等待失败
printf("Wait child failed, return.\n");
return 1;
}
}
return 0;
}

- 非阻塞等待: 父进程不断检测子进程的退出状态,期间会干其他事情(基于阻塞的轮询等待)
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
pid_t pid;
pid = fork();
if(pid < 0){
printf("%s fork error\n",__FUNCTION__);
return 1;
}else if( pid == 0 ){ //child
printf("child is run, pid is : %d\n",getpid());
sleep(5);
exit(1);
} else{
int status = 0;
pid_t ret = 0;
do
{
ret = waitpid(-1, &status, WNOHANG);//非阻塞式等待
if( ret == 0 ){
printf("child is running\n");
}
sleep(1);
}while(ret == 0);
if( WIFEXITED(status) && ret == pid ){
printf("wait child 5s success, child return code is :%d.\n",WEXITSTATUS(status));
}else{
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
进程程序替换
替换原理
- 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支)
- 子进程往往要调用一种exec函数以执行另一个程序。
- 当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。
- 调用exec并不创建新进程,调用exec()函数不会改变进程的ID,即在进程的生命周期内,其PID保持不变。
替换函数
替换函数有六种以exec开头的函数,它们统称为exec函数:
#include <unistd.h>
extern char **environ;
1. int execl(const char *path, const char *arg, ..., NULL);// 可变参数列表,可以放入多个参数
2. int execv(const char *path, char *const argv[]);
3. int execlp(const char *file, const char *arg, ..., NULL);
4. int execvp(const char *file, char *const argv[]);
5. int execle(const char *path, const char *arg, ..., char *const envp[]);
6. int execve(const char *path, char *const argv[], char *const envp[]);
函数解释
公共返回值
对于所有exec系列函数,它们的返回值有共通之处:
返回值:如果exec函数执行成功,它不会返回到原来的程序,也就意味着不会有返回值。如果有返回值,表示出现错误,函数返回-1,并且会设置errno以指示错误的原因。
-
execl
· 函数原型:int execl(const char *path, const char *arg, ..., NULL);
· 参数:
path:要执行的程序的路径。
arg:程序启动时传递给main函数的参数列表,第一个参数通常是程序的名称,之后是程序运行时需要的参数,最后必须以NULL结束,作为参数列表的结束标志。 -
execv
· 函数原型:int execv(const char *path, char *const argv[]);
· 参数:
path:要执行的程序的路径。
argv:是一个字符串数组,用于传递给新程序的参数,其中argv[0]通常是程序的名称,argv数组的最后一个元素必须是NULL,以标记参数的结束。 -
execlp
· 函数原型:int execlp(const char *file, const char *arg, ..., NULL);
· 参数:
file:要执行的程序的名称,execlp会在PATH环境变量指定的目录下搜索这个程序。
arg:同execl。 -
execvp
· 函数原型:int execvp(const char *file, char *const argv[]);
· 参数:
file:要执行的程序的名称,execvp会在PATH环境变量指定的目录下搜索这个程序。
argv:同execv。 -
execle
· 函数原型:int execle(const char *path, const char *arg, ..., char *const envp[]);
· 参数:
path:要执行的程序的路径。
arg:同execl。
envp:一个以NULL结尾的字符串数组,用于为新程序指定环境变量。这允许调用者改变新程序的环境变量。 -
execve
· 函数原型:int execve(const char *path, char *const argv[], char *const envp[]);
· 参数:
path:要执行的程序的路径。
argv:同execv。
envp:同execle。
命名理解
这六个exec系列函数的函数名都以exec开头,其后缀的含义如下:
- l(list): 表示参数采用列表的形式,一一列出。
- v(vector): 表示参数采用数组的形式。
- p(path): 表示能自动搜索环境变量PATH,进行程序查找。
- e(env): 表示可以传入自己设置的环境变量。
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 否 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 否 | 否,需要自己组装环境变量 |
| execv | 数组 | 否 | 是 |
| execvp | 数组 | 是 | 是 |
| execve | 数组 | 否 | 否,需要自己组织环境变量 |
实际上:execve函数是exec系列函数中唯一的一个直接作为系统调用实现的函数。这意味着,当你调用execve时,你直接与操作系统内核交互,请求替换当前进程的映像(即代码和数据)为指定程序的映像。其他的exec函数,比如execl, execp, execlp, execv, 和 execvp,在底层都是通过调用execve来实现的。它们存在的目的主要是为了提供更加方便的接口,以满足不同场景下对参数传递方式的需求。
为什么只有execve是系统调用?
- 直接内核操作:系统调用是操作系统提供给用户程序的接口,允许用户程序请求操作系统执行特定的功能或服务。因为execve需要进行复杂的操作,如清理当前进程空间、加载新程序到进程空间、设置新的堆、栈、寄存器等,这些都需要操作系统的内核模式权限来完成。
- 统一实现:通过仅将execve实现为系统调用,操作系统可以确保所有的exec函数族成员都有统一的底层行为。这样,无论调用哪个exec函数,最终都是通过同一个系统调用execve来实现程序的替换,确保了操作的一致性和效率。
- 简化API:execve提供了一个基础但全面的接口,需要通过三个参数直接指定程序路径、环境变量和命令行参数。其他的exec函数通过封装execve,允许以不同形式提供这些信息,使得API更易于不同场景下的使用,但最终这些函数都会转化为execve函数的调用参数。
做一个简易的shell
shell也就是命令行解释器,其运行原理就是:当有命令需要执行时,shell创建子进程,让子进程执行命令,而shell只需等待子进程退出即可。
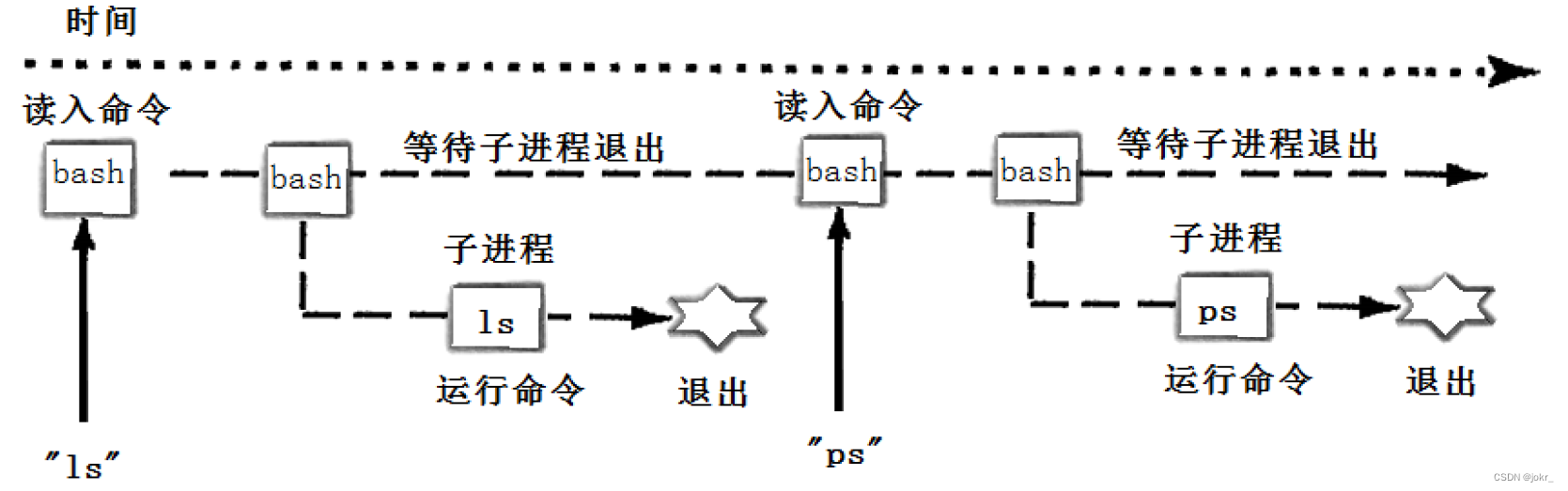
其实shell需要执行的逻辑非常简单,其只需循环执行以下步骤:
- 获取命令行。
- 解析命令行。
- 创建子进程。
- 替换子进程。
- 等待子进程退出。
其中,创建子进程使用fork函数,替换子进程使用exec系列函数,等待子进程使用wait或者waitpid函数。
于是我们可以很容易实现一个简易的shell,代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#define SIZE 512
#define ZERO '\0'
#define SEP " "
#define NUM 32
#define SkipPath(p) do{ p += (strlen(p)-1); while(*p != '/') p--; }while(0)
// 为了方便,我就直接定义了
char cwd[SIZE*2];
char *gArgv[NUM];
int lastcode = 0;
void Die()
{
exit(1);
}
const char *GetHome()
{
const char *home = getenv("HOME");
if(home == NULL) return "/";
return home;
}
const char *GetUserName()
{
const char *name = getenv("USER");
if(name == NULL) return "None";
return name;
}
const char *GetHostName()
{
const char *hostname = getenv("HOSTNAME");
if(hostname == NULL) return "None";
return hostname;
}
// 临时
const char *GetCwd()
{
const char *cwd = getenv("PWD");
if(cwd == NULL) return "None";
return cwd;
}
// commandline : output
void MakeCommandLineAndPrint()
{
char line[SIZE];
const char *username = GetUserName();
const char *hostname = GetHostName();
const char *cwd = GetCwd();
SkipPath(cwd);
snprintf(line, sizeof(line), "[%s@%s %s]> ", username, hostname, strlen(cwd) == 1 ? "/" : cwd+1);
printf("%s", line);
fflush(stdout);
}
int GetUserCommand(char command[], size_t n)
{
char *s = fgets(command, n, stdin);
if(s == NULL) return -1;
command[strlen(command)-1] = ZERO;
return strlen(command);
}
void SplitCommand(char command[], size_t n)
{
(void)n;
// "ls -a -l -n" -> "ls" "-a" "-l" "-n"
gArgv[0] = strtok(command, SEP);
int index = 1;
while((gArgv[index++] = strtok(NULL, SEP))); // done, 故意写成=,表示先赋值,在判断. 分割之后,strtok会返回NULL,刚好让gArgv最后一个元素是NULL, 并且while判断结束
}
void ExecuteCommand()
{
pid_t id = fork();
if(id < 0) Die();
else if(id == 0)
{
// child
execvp(gArgv[0], gArgv);
exit(errno);
}
else
{
// fahter
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0)
{
lastcode = WEXITSTATUS(status);
if(lastcode != 0) printf("%s:%s:%d\n", gArgv[0], strerror(lastcode), lastcode);
}
}
}
void Cd()
{
const char *path = gArgv[1];
if(path == NULL) path = GetHome();
// path 一定存在
chdir(path);
// 刷新环境变量
char temp[SIZE*2];
getcwd(temp, sizeof(temp));
snprintf(cwd, sizeof(cwd), "PWD=%s", temp);
putenv(cwd); // OK
}
int CheckBuildin()
{
int yes = 0;
const char *enter_cmd = gArgv[0];
if(strcmp(enter_cmd, "cd") == 0)
{
yes = 1;
Cd();
}
else if(strcmp(enter_cmd, "echo") == 0 && strcmp(gArgv[1], "$?") == 0)
{
yes = 1;
printf("%d\n", lastcode);
lastcode = 0;
}
return yes;
}
int main()
{
int quit = 0;
while(!quit)
{
// 1. 我们需要自己输出一个命令行
MakeCommandLineAndPrint();
// 2. 获取用户命令字符串
char usercommand[SIZE];
int n = GetUserCommand(usercommand, sizeof(usercommand));
if(n <= 0) return 1;
// 3. 命令行字符串分割.
SplitCommand(usercommand, sizeof(usercommand));
// 4. 检测命令是否是内建命令
n = CheckBuildin();
if(n) continue;
// 5. 执行命令
ExecuteCommand();
}
return 0;
}
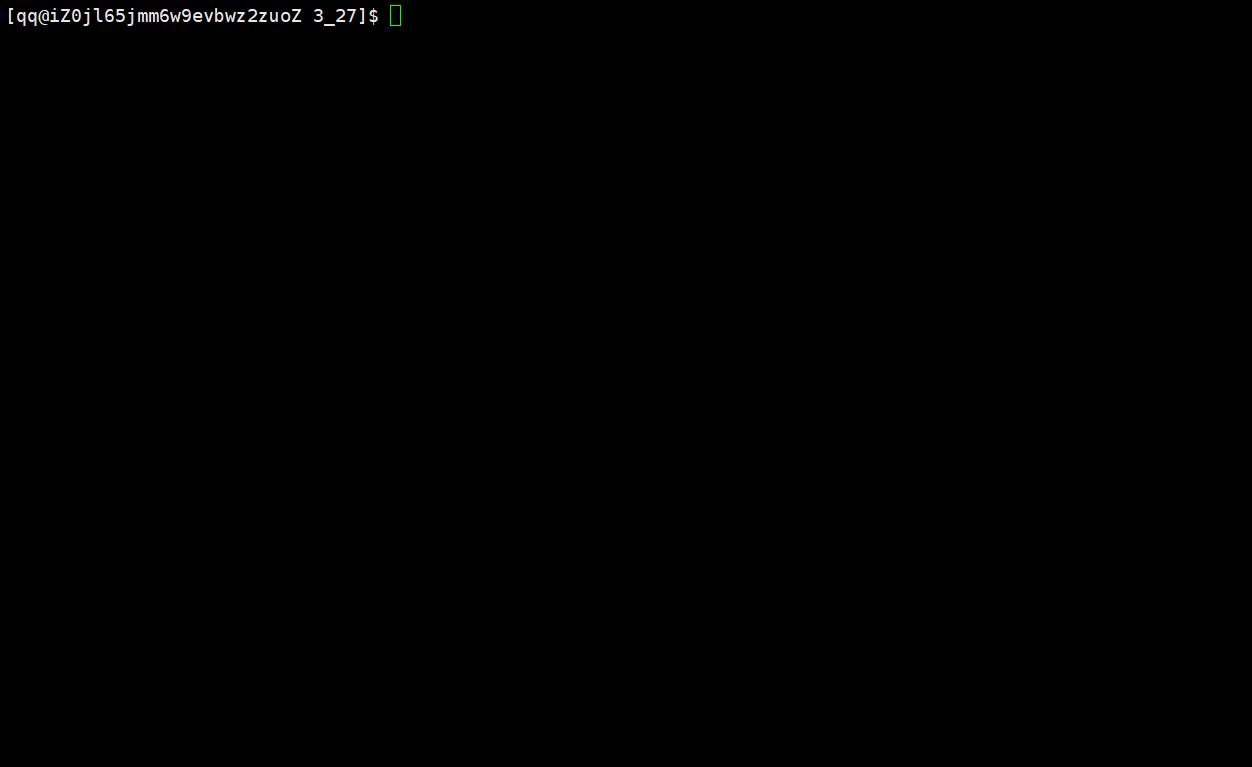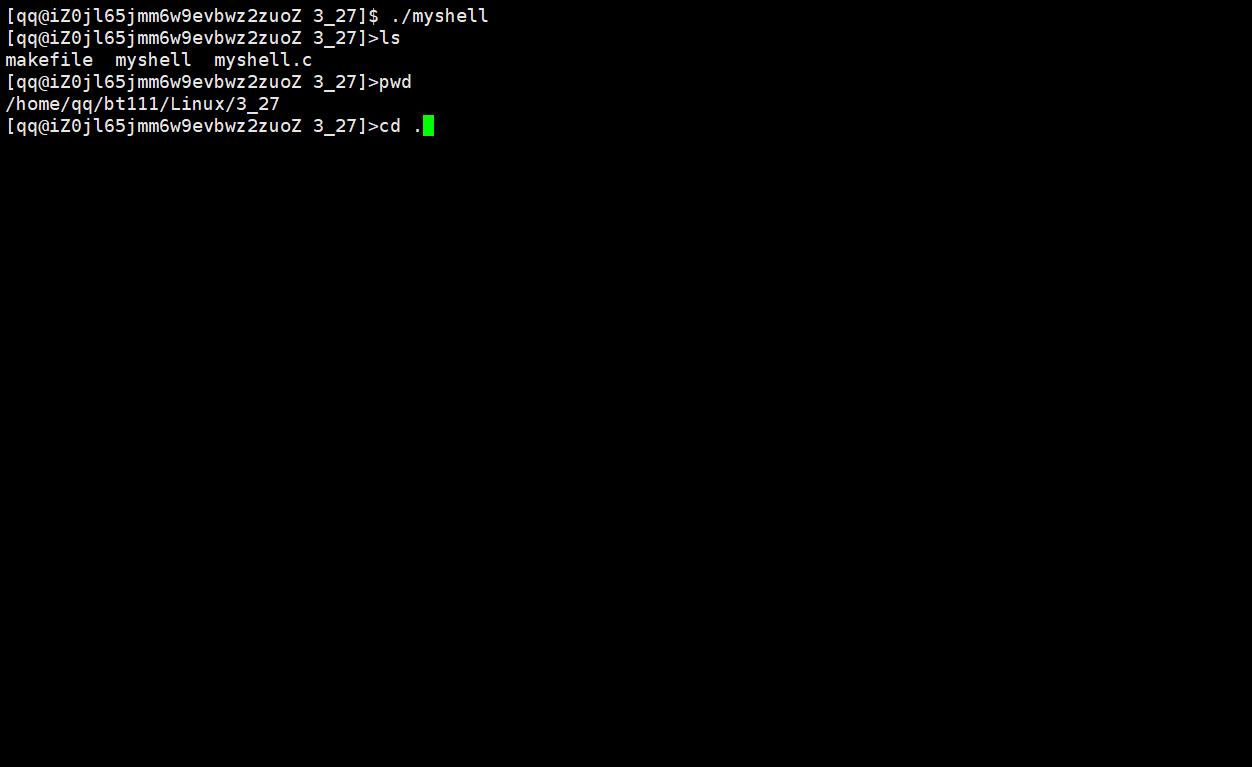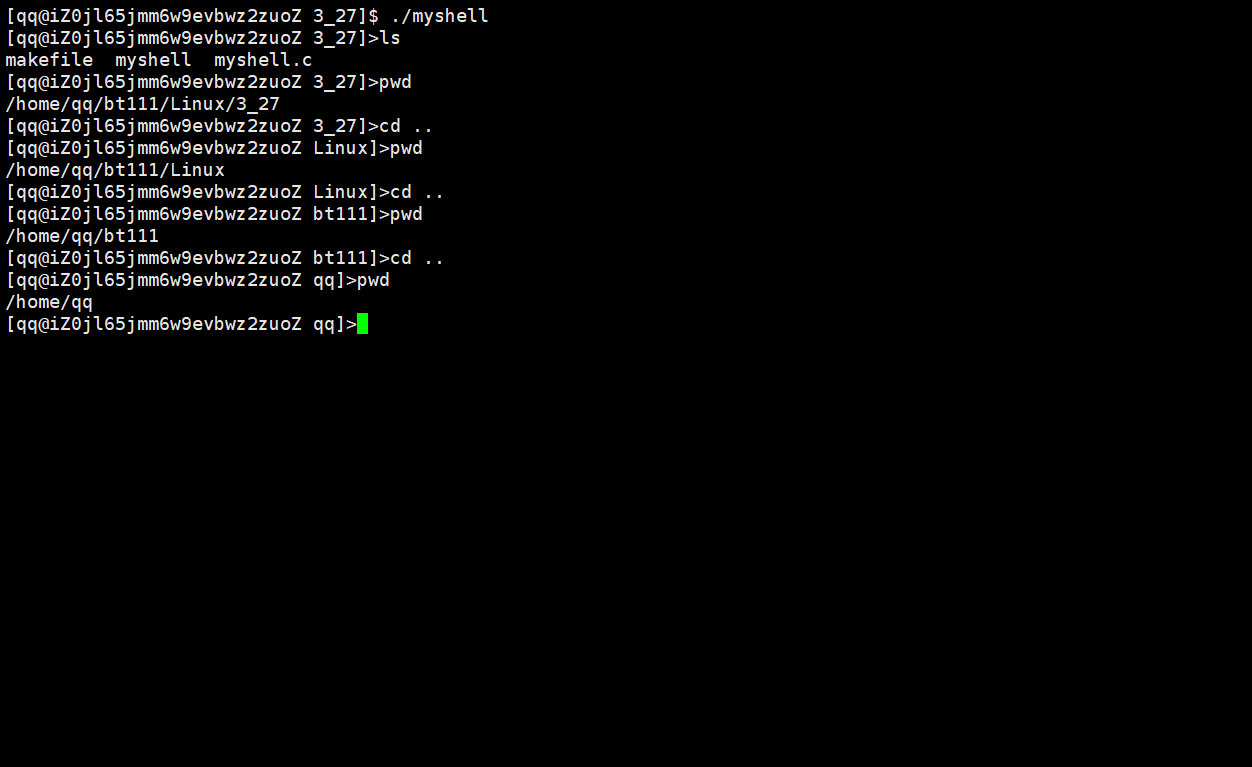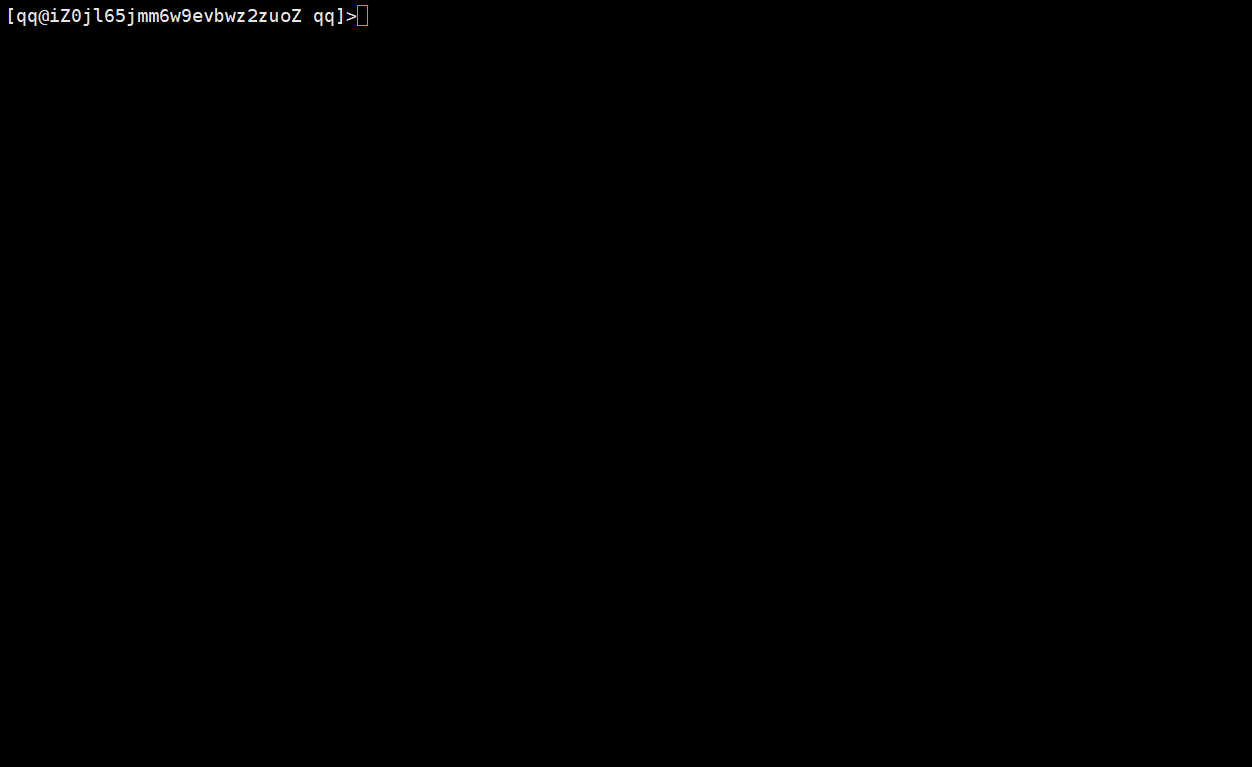
说明:
当执行./myshell命令后,便是我们自己实现的shell在进行命令行解释,我们自己实现的shell在子进程退出后都打印了子进程的退出码,我们可以根据这一点来区分我们当前使用的是Linux操作系统的shell还是我们自己实现的shell。















 1988
1988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









