







目录
前言:本节主要讲的是进程具体的调用方法及原理,如何调用对应的系统接口进行进程创建、等待和退出的方法
一、进程创建
先看一下创建进程的系统函数
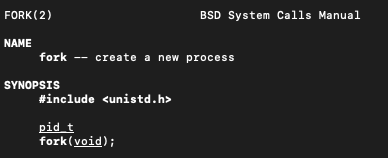
当返回 == 0,就是子进程
当返回值 > 0,就是父进程,返回的是各子进程的id
当返回 -1 , 创建失败
1. 为什么会有两个返回值?
我们创建一个进程 pid_t id = fork();
都说子进程会拷贝父进程的地址空间代码数据、页表,那么是如果有if条件判断是如何区分跑的哪一个?
这里的fork函数,父进程创建子进程,赋值给id变量,这时候就已经发生了写时拷贝,这时子进程拷贝了父进程的内容,都相互独立,而fork会return各自的id,互不影响
就好像我们用的Terminal一样,自身是一个父进程,有把握的事情自己做,没有把握的事情容易fail的,交给子进程去做,这样就不会影响用户使用此Terminal
2. 写时拷贝
我们都知道在没有修改内容之前,父子进程的页表都会指向同一块物理内存

注意写时拷贝由操作系统完成
而发生了修改之后,操作系统写时拷贝为子进程新创建一个物理内存进程存储
那么问题来了为什么要有写时拷贝?
一般的思路是,父进程创建的时候,直接把数据各自拷贝一份不就完事了嘛
如果在没有发生数据修改的时候,做了一次拷贝就浪费内存和系统资源,fork时会创建各自的数据结构,如果再进程拷贝效率会很低,所以只有在发生修改时再做拷贝
二、进程退出
1. exit vs _exit
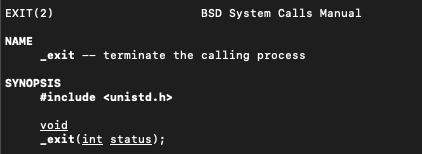
_exit(&status) 调用后就直接退出了,不会有其他动作
相反 exit(XX)调用后,会执行用户定义的清理函数,冲刷缓冲,关闭流等
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
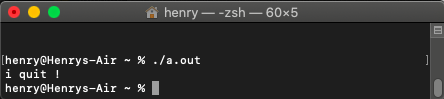
int main(){
printf("i quit !"); //注意不能加\n这里会有刷新缓冲区作用
exit(0);
return 0;
}
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
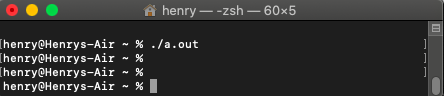
int main(){
printf("i quit !"); //注意不能加\n这里会有刷新缓冲区作用
_exit(0);
return 0;
}
2. return
return xxx的方式等同于执行exit(xxx),因为调用main的运行时函数会将main的返回值当做exit的参数
站在OS的角度,如何理解进程终止?
- 释放曾经管理所维护的数据结构对象
- 释放代码和数据所占用的空间(这里不是数据清空而是把内存设置为无效)
- 取消该进程曾经的连接关系
*释放:不是真的把数据结构对象销毁,而是设置为不可用,然后保持起来,如果不用的对象多了就会有一个“数据结构的池子”
三、进程等待
1. 为什么要进程等待呢?
- 回收僵尸进程,解决内存泄漏问题,如果没有父进程的等待子进程会保留部分数据结构在内存中占用资源
- 需要获取进程的运行结束状态
- 父进程要尽量晚于子进程退出,可以规范化进行资源回收
2. wait和waitpid


如上面所述wait 正常结束会返回child process的ID,否则失败会返回-1
这里面的stat_loc会返回子进程结束的退出状态
pid_t
waitpid(pid_t pid, int *stat_loc, int options);
这里当正常返回时waitpid返回收集到的子进程的进程ID,stat_loc和wait一样也是用于获取child process的退出状态
这里stat_loc也是status,有两种已经封装好的函数
- WIFEXITED(status),若正常终止子进程返回的状态,则为真(查看进程是否正常退出)
- WEXITSTATUS(status),若WIFEXITED非零,提取子进程的退出码,terminated signal)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









