







<a target=_blank href="https://zh.wikipedia.org/zh-cn/冒泡排序" target="_blank">wiki对冒泡排序的介绍:</a>
<a target=_blank href="https://zh.wikipedia.org/zh-cn/冒泡排序" target="_blank">wiki对冒泡排序的介绍:</a> 冒泡排序对 个项目需要O(
个项目需要O(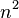 )的比较次数,且可以原地排序。尽管这个算法是最简单了解和实作的排序算法之一,但它对于少数元素之外的数列排序是很没有效率的。
)的比较次数,且可以原地排序。尽管这个算法是最简单了解和实作的排序算法之一,但它对于少数元素之外的数列排序是很没有效率的。
冒泡排序是与插入排序拥有相等的运行时间,但是两种法在需要的交换次数却很大地不同。在最好的情况,冒泡排序需要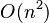 次交换,而插入排序只要最多
次交换,而插入排序只要最多 交换。冒泡排序的实现(类似下面)通常会对已经排序好的数列拙劣地运行(),而插入排序在这个例子只需要个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。冒泡排序如果能在内部循环第一次运行时,使用一个旗标来表示有无需要交换的可能,也可以把最好的复杂度降低到。在这个情况,已经排序好的数列就无交换的需要。若在每次走访数列时,把走访顺序反过来,也可以稍微地改进效率。有时候称为鸡尾酒排序,因为算法会从数列的一端到另一端之间穿梭往返。
交换。冒泡排序的实现(类似下面)通常会对已经排序好的数列拙劣地运行(),而插入排序在这个例子只需要个运算。因此很多现代的算法教科书避免使用冒泡排序,而用插入排序取代之。冒泡排序如果能在内部循环第一次运行时,使用一个旗标来表示有无需要交换的可能,也可以把最好的复杂度降低到。在这个情况,已经排序好的数列就无交换的需要。若在每次走访数列时,把走访顺序反过来,也可以稍微地改进效率。有时候称为鸡尾酒排序,因为算法会从数列的一端到另一端之间穿梭往返。
冒泡排序算法的运作如下:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡算法实现:
#include <stdio.h>
/*为了装(*),写了一个交换宏定义函数,功能是为了实现两个元素交换*/
#define SWAP(a, b) {\
int temp;\
temp = a;\
a = b;\
b = temp;\
}
void Bubble_Sort()
/*冒泡排序主题*/
void Bubble_Sort(int *array, int length)
{
int i = 0;
for( ;i < length - 1; i++) //设定最初的下沉元素位置
{
int j = i + 1;
for(; j < length ; j++) // 寻找下沉的元素的位置
{
if( array[i] > array[j]) // 如果满足if语句,则找到下沉的元素
SWAP(array[i], array[j]) // 交换元素,完成元素下沉
}
}
return ;
}
void Print(const int *array, int length)
{
int i;
for(i = 0; i < length; i++)
{
printf("%d ",array[i]);
if( !(i % 8) && i) //为了装(*),每8个元素进行换行,并且保证首行不换行
printf("\n");
}
printf("\n");
return ;
}
int main()
{
int a[] = {5,4,3,2,1,0,9,2,1,-1,9}; //测试用例
Bubble_Sort(a, 11);
Print(a, 11);
return 0;
} 个人学的冒泡大概就这样了!有很多不同的写法,不过基本都是换汤不换药,对于效率都差不多,时间复杂度都是,也算是开始写blog的开始。















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









