









Python 简单爬虫的样例(获取拉钩网Python的职位)
本文使用到以下两个包
- requests
- beautifulsoup4
requests
一个HTTP客户端,非常方便的发起HTTP/1.1的请求。以PEP 20为中心开发的Python库包。
PEP 20:
- Beautiful is better than ugly.
- Explicit is better than implicit.
- Simple is better than complex.
- Complex is better than complicated.
- Readability counts.
requests的一个小例子, 例如获取链接: https://www.baidu.com/
import requests
text = requests.get('https://www.baidu.com/').content.decode('utf-8')
print(text)得到的结果如下:
<!DOCTYPE html><!--STATUS OK-->
<html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>是不超级简单。
requests 详细的用法见链接: http://docs.python-requests.org/en/master/
beautifulsoup4
一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 它会帮你节省数小时甚至数天的工作时间.
我觉得还是用例子说话比较好一点(文笔不够,敬请见谅),使用上面获取的text 做解析:
from bs4 import BeautifulSoup
soup = BeautifulSoup(text, "html.parser")
# 输入页面的title
print(soup.title.string)
# 输出: 百度一下,你就知道
# 列出所有a标签
for a in soup.find_all('a'):
print(a)
"""输出结果:
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a>
<a class="lb" href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login">登录</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品</a>
<a href="http://home.baidu.com">关于百度</a>
<a href="http://ir.baidu.com">About Baidu</a>
<a href="http://www.baidu.com/duty/">使用百度前必读</a>
<a class="cp-feedback" href="http://jianyi.baidu.com/">意见反馈</a>
"""就举这点例子了。
更多详细的用法见链接: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
接入题目正文,获取拉钩网Python的职位。
接入正题
分析页面结构
使用浏览器(本文使用chrome浏览器)打开链接: https://www.lagou.com/zhaopin/Python/ ,这就是招Python的职位(默认全国的),使用F12 打开浏览器调试模式,如下图:
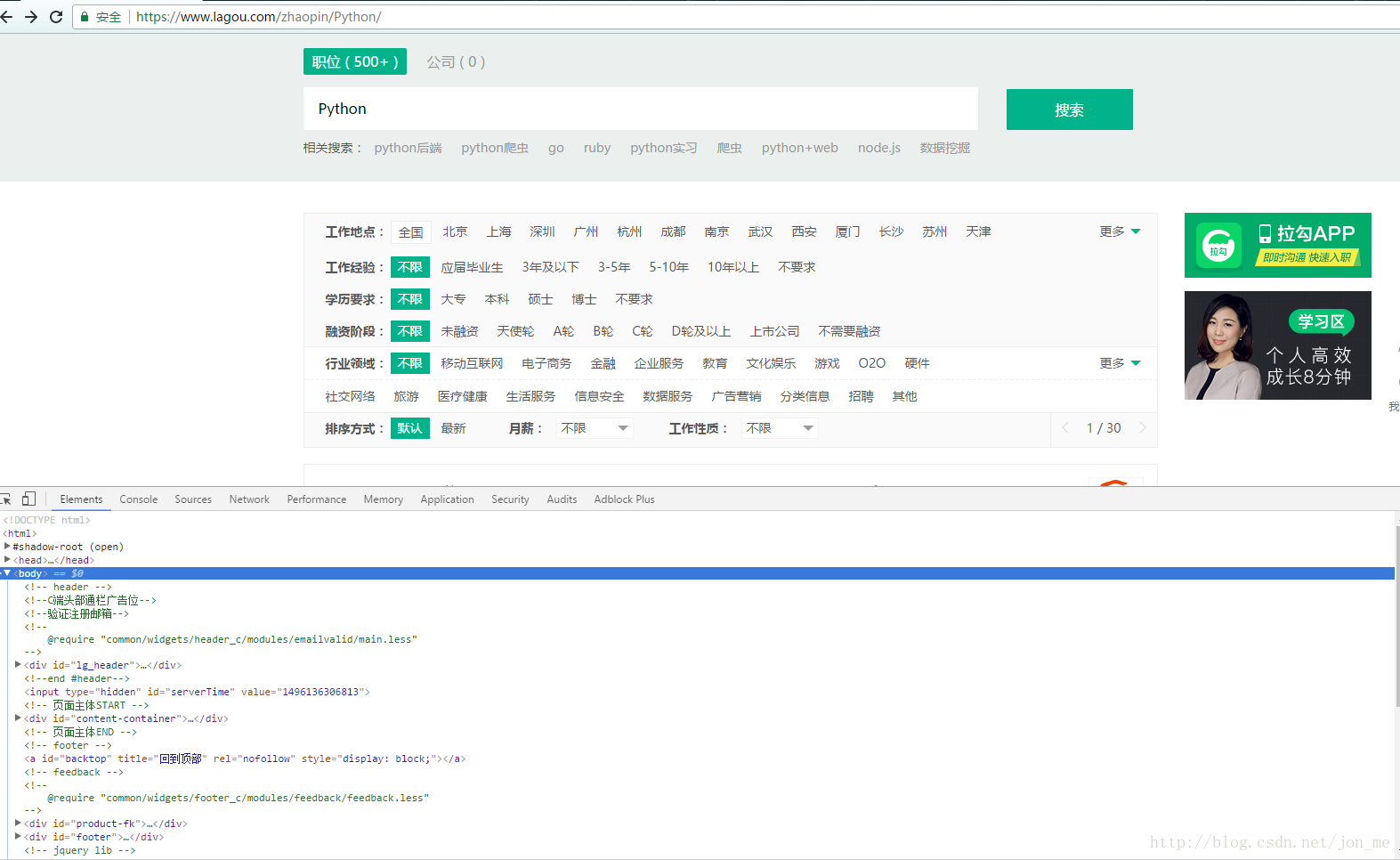
为了得到职位信息我们应该要以下的信息:
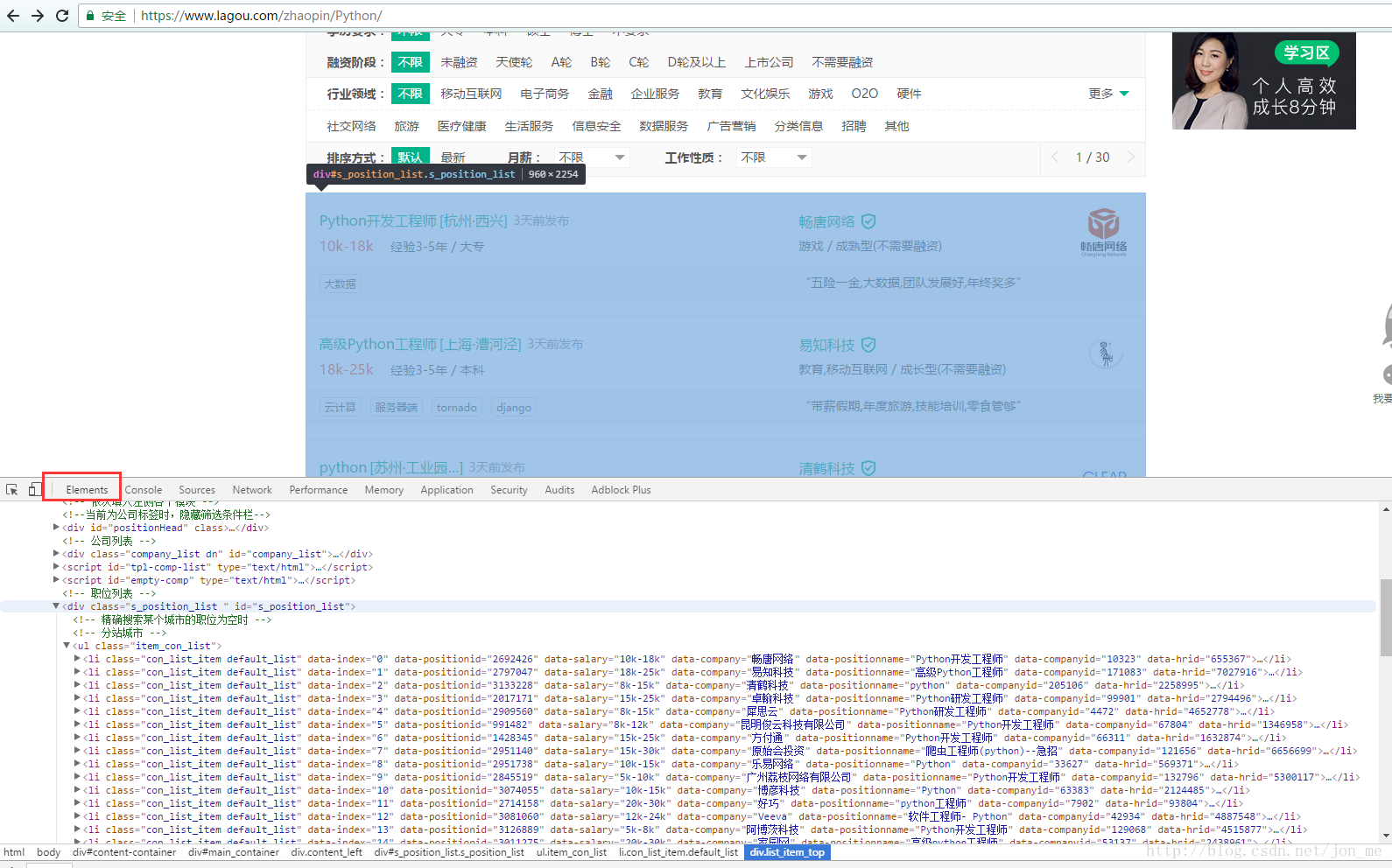
信息部分找到了,现在需要去解析这段标记。比如这样做:
soups = soups.find(id='s_position_list').ul.find_all('li')然后需要具体的那些信息字段,例如需要data-company, data-companyid, data-hrid, data-positionid, data-positionname, data-salary 这几个属性值。可以这样做:
soup_list = []
for idx, soup in enumerate(soups):
soup_list.append({'company': soup['data-company'],
'company_id': soup['data-companyid'],
'hrid': soup['data-hrid'],
'positionname': soup['data-positionname'],
'salary': soup['data-salary']})到这里能获取需要信息了,但是了这个网站有很恶心的地方,就是对http请求有检查,可以这样做(仅仅是最简单那种):
# 定义http请求头部
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'DNT': '1',
'Host': 'www.lagou.com',
'Pragma': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'Cookie': 'user_trace_token=20170529170535-f9c2c61d-444d-11e7-9468-5254005c3644; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fpassport.lagou.com%2Flogin%2Flogin.html%3Fmsg%3Dvalidation%26uStatus%3D2%26clientIp%3D223.20.35.98; LGUID=20170529170535-f9c2ca34-444d-11e7-9468-5254005c3644; JSESSIONID=ABAAABAAADEAAFI755D3A01C2C01F7BBAD36A9C10003482; _gat=1; index_location_city=%E5%8C%97%E4%BA%AC; TG-TRACK-CODE=index_navigation; SEARCH_ID=f6eb83ea6f014ca5b22bad098089c4fa; _gid=GA1.2.1479464309.1496050214; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496048733; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496050214; _ga=GA1.2.1251572620.1496048733; LGSID=20170529170535-f9c2c89c-444d-11e7-9468-5254005c3644; LGRID=20170529173016-6c7f3d70-4451-11e7-b9f1-525400f775ce',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
}
url = 'https://www.lagou.com/zhaopin/Python/1'
soups = BeautifulSoup(requetst.get(url, headers=headers).content, 'html.parser')对,就是这样,已经搞定了一个页面,然而一般情况发现这里仅仅是一个URL,然而这里有多个,其实多点几个页面,就能发现当url 为 https://www.lagou.com/zhaopin/Python/2 时就是第二个页面,还有一个非常关键的地方就是,30页到头了。所以需要对https://www.lagou.com//zhaopin/Python/1 到 https://www.lagou.com//zhaopin/Python/30 做一个遍历,既能收货这个这个职位的信息了(这是偷懒的一种,准确的是去页面解析下一页,但是本文没有去实现,不过也很简单)。
注意的地方:
该网站的cookie是可变化的,所以复制上面代码可能请求有问题,需要更改cookie值,还有就是对请求ip就限制。
本文有一个稍微仅供参考的代码地址:https://github.com/myisjon/web_crawler/blob/master/basic_crawler/lagou.py















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









