







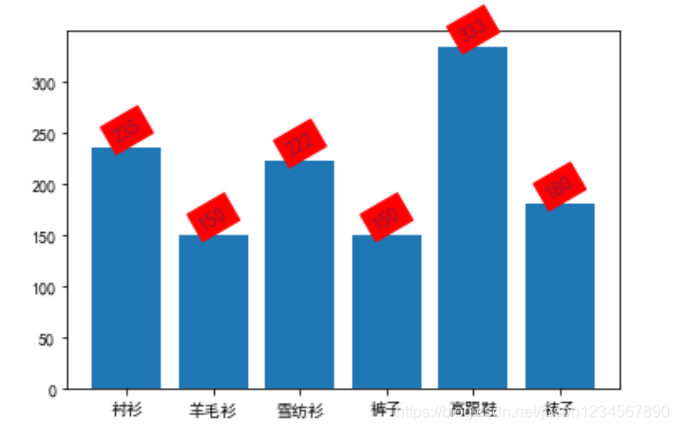
范例:
x = ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子']
y = [235,150,222,150,333,180]
# 数字标签
for a,b in zip(x,y):
plt.text(a, b+2,
b,
ha='center',
va= 'bottom',
fontsize=12,
color=(0.1, 0.2, 0.5),
backgroundcolor='red',
rotation=30,
alpha=0.5
)
plt.bar(x,y)
plt.show()
显示:
函数解释:
matplotlib.pyplot.text(x, y, s, fontdict=None, withdash=False, **kwargs)
常用参数说明:
x,y:显示内容的坐标位置
s:显示内容
fontdict:一个定义s格式的dict
fontsize:字体大小
color:str or tuple, 设置字体颜色 ,单个字符候选项{‘b’, ‘g’, ‘r’, ‘c’, ‘m’, ‘y’, ‘k’, ‘w’},也可以’black’,'red’等,tuple时用[0,1]之间的浮点型数据,RGB或者RGBA, 如: (0.1, 0.2, 0.5)、(0.1, 0.2, 0.5, 0.3)等
backgroundcolor:字体背景颜色
horizontalalignment(ha):设置垂直对齐方式,可选参数:left,right,center
verticalalignment(va):设置水平对齐方式 ,可选参数 : ‘center’ , ‘top’ , ‘bottom’ ,‘baseline’
rotation(旋转角度):可选参数为:vertical,horizontal 也可以为数字
alpha:透明度,参数值0至1之间
官方说明:
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.text.html


















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











