







Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
前言:
论文链接:https://arxiv.org/pdf/2203.07845.pdf
github链接:https://github.com/Davidzhangyuanhan/Bamboo
demo网址:https://opengvlab.shlab.org.cn/bamboo/search
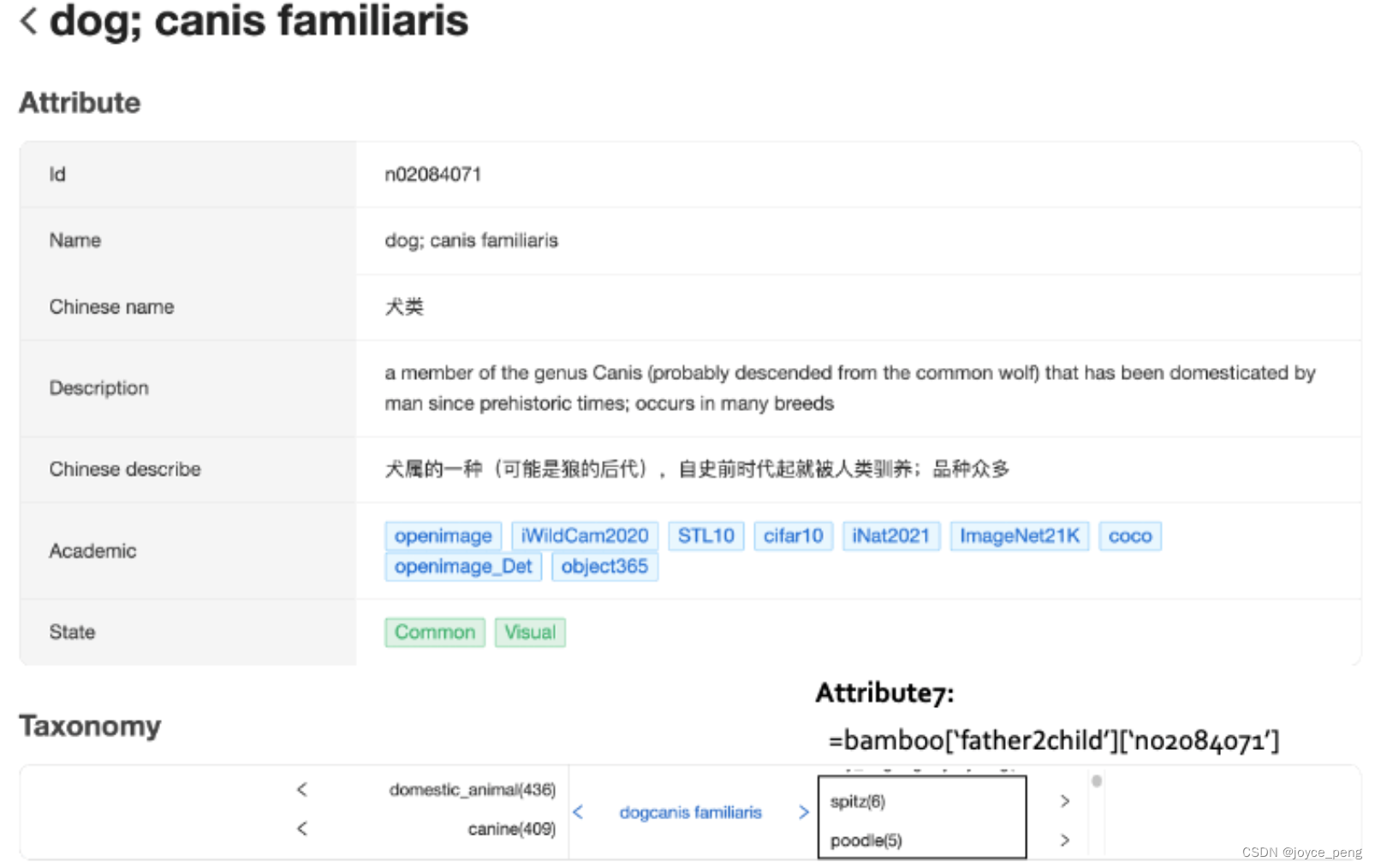
商汤2022.3发表,主要内容为如何对开源数据集进行合并
论文分为摘要、背景介绍、相关工作、标签系统、Bamboo数据集构建、数据集数据、验证集实验
总结摘要如下,具体图片解释见摘要最后
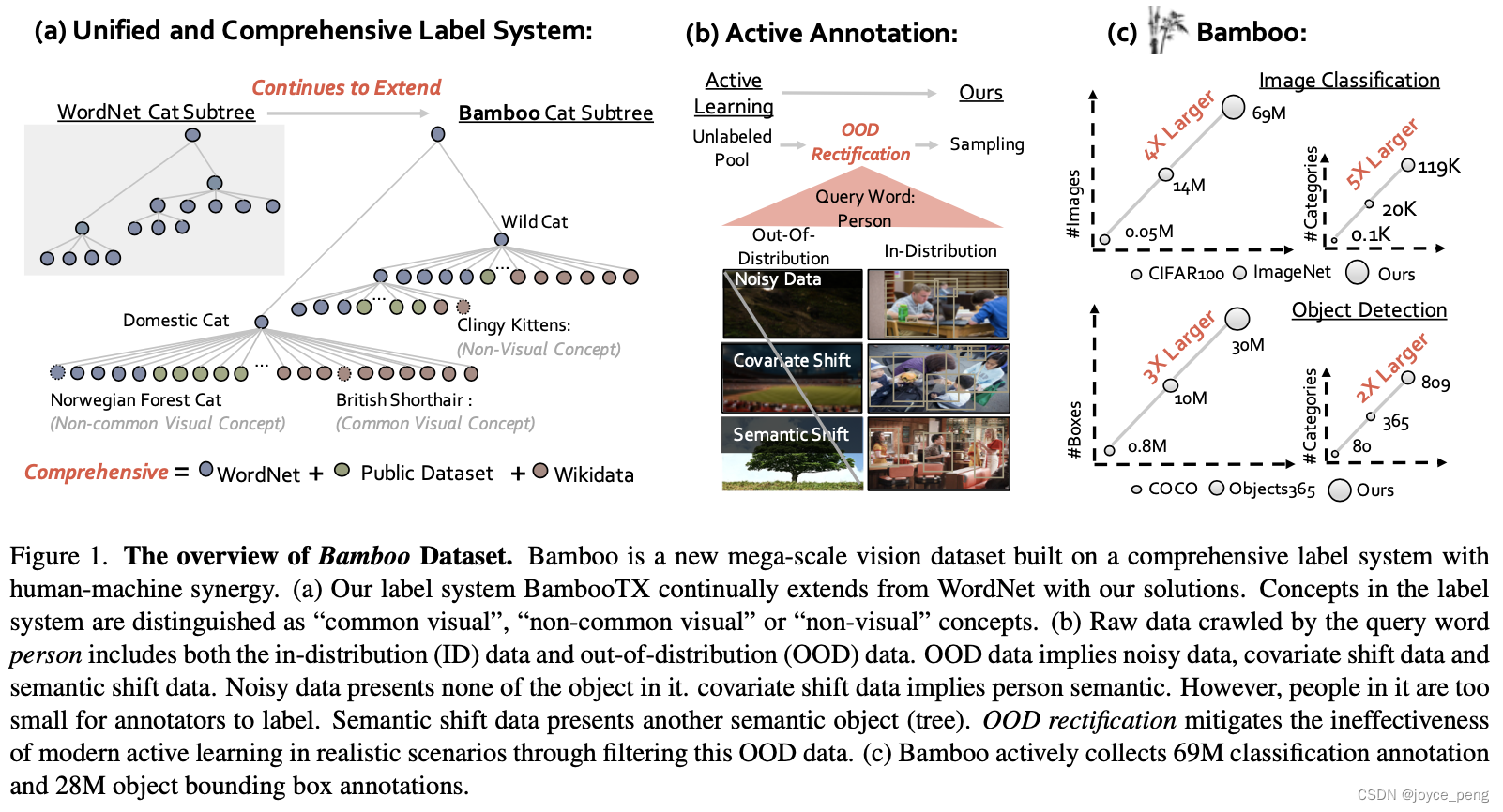
fig1:
a. Bamboo以wordnet参考构建,分为“common visual”, “non-common visual” or “non-visual” 三个概念
b. 爬虫数据分为in-distribution(ID)和out-of-distribution(OOD),OOD中包含噪声数据、Covariate Shift(人太小无法标记)、Semantic Shift(语义理解错误),通过过滤这些OOD数据矫正
c. Bamboo搜集了69M分类标注和28M目标框标注
摘要
(问题)现在的数据集要么是参考heuristic标签系统,要么是不区分样本区别的标注,效率低且扩展性差
(创新点)所以我们建立了Bamboo数据集,将分类和检测的数据集合并建立了高质量的视觉数据集
(细节)包含两方面1)标签系统: 合并了24个数据集,包含170,586类别,层次结构包含304,048个类别,标签结构在我们的体系中容易扩展,concept进一步被区分为视觉和非视觉 2)有效标注: 基于真实的370M的爬虫数据,通过我们的标注框架,只有含信息的图片被挑中。
(效果)Bamboo使用69M分类数据和28M目标框标注,对比ImageNet22k和objects365,在Bamboo上预训练的模型性能更好(6.2%在分类上,2.1%在检测上)
3. 综合标签系统-BambooTX
3.1 标签来源Concepts Resources
WordNet: synset:WordNet中每个有意义的概念,都会通过多个词语或短语进行详细描述,比如ImageNet22K,我们只使用了WordNet中名词
Public Datasets: 搜集了24个公开数据集,ImageNet22K、OpenImages、COCO等分类和检测数据集
Wikidata: 包含的concepts更多更详细,我们已经有170w概念来自它
3.2 标签融合Concepts Integration
通过字符串匹配可以融合大部分概念,但有些类别不在WordNet中,提出了方案BambooTx将concept融合
方法1: 搜寻common名。
在Wiki中搜索该类别(可能是学术名)常用的名字,如Aves是birds的学术名,使用WordNet中bird的描述
方法2: 使用subclassOf。
Wikidata 的分类是通过在 WordNet 的分类中添加与上位词关系相关的“subclassOf”来贡献的。我们通过利用“sub-classOf”将 Wikidata 叶节点概念链接到 WordNet。
方法3:解析concept。
通过解析Sumatran Orangutan获得主语Orangutan,如果主语在WordNet中,则将其变为Orangutan的下位词
方法4: 相近词链接到已有synset。
通过spacy计算同义词和词向量,添加其到同义词集的下位词中
3.3 概念标记
Visuality: 之前工作对视觉性标签有标注,但有几个缺点,1)视觉表示和视觉区分是不匹配的,eg.女儿和姐姐都是女生,但视觉难以区分。2)标注员往往对不熟悉的标签容易标注非视觉标签。所以我们提供了示例图像。非视觉标签指:样例图片不包含语义信息or语义信息不具有唯一性。如图2.
Commonality: 对视觉标签进行概念标注,5个标注员至少3个投票才认为标注有效。
4. 数据集构建-Bamboo
step1: 从公共数据集中获取数据
step2: 从Flickr中获取图片
step3: 建立标注循环,通过不断增长的数据扩展Bamboo
4.1 获取公共数据集数据
19个分类和5个检测数据集,选择了12个数据集做下游验证,并整合了另外12个数据集到Bamboo。总共有27,848,477分类标注和21,983,223目标框标注。
4.2 获取原始数据
通过在Flickr上搜索关键词获取数据,对于分类,一个查询词有一个视觉概念,对于检测,一个查询词有两个概念(通用概念和场景语义,比如dog+street)。为了丰富结果,给定的查询词可以转换为同义词或外语版本。作者有170M的分类未标记池和200M的检测未标记池
4.3 标注循环
图和细节见附录算法1
由于不干净的数据占比过多,所以1)初始化网络2)OOD矫正,3)sampling,4)标记有效数据
1.模型训练: 公开数据集和新标记的少量数据集上,初始化网络
2.OOD矫正: 1) 图像分类:使用上一轮训练好的模型预测unlabel池里的图片,如果top5预测结果都和它相关类别(查询词和父类的所有子类)无重叠,则视为out-of-distribution,否则加入下一步sample的数据中。2)检测:同样使用上一轮训练好的模型预测unlabel池里的图片。如果图像上少于两个proposals或者超过15个不同语义的proposals则滤除
3.Sampling: 目的是为了筛选5M分类和100K检测数据来人工标注
4. 标记有效数据 标记是否为视觉概念、是否为通用概念
附录:
图2:
a)OOD数据
b)视觉和非视觉样例,维他命没有语义信息,经济学家没有唯一性,均会被筛除。






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









