



 本文介绍了MapReduce的基本原理和工作流程,详细解释了wordcount示例的实现过程,并提供了完整的Java代码示例。此外,还对比分析了YARN框架与原始MapReduce框架的不同之处及其工作机制。
本文介绍了MapReduce的基本原理和工作流程,详细解释了wordcount示例的实现过程,并提供了完整的Java代码示例。此外,还对比分析了YARN框架与原始MapReduce框架的不同之处及其工作机制。
1 原理及组成
Client:用户编写的MapReduce程序通过Client提交到JobTracker端;用户可通过Client提供的一些接口查看作业运行状态
JobTracker:负责资源监控和作业调度,JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点。JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
TaskTracker: 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等);TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和ReduceTask 使用,可以同时进行
Task:分为Map Task 和Reduce Task 两种,均由TaskTracker启动
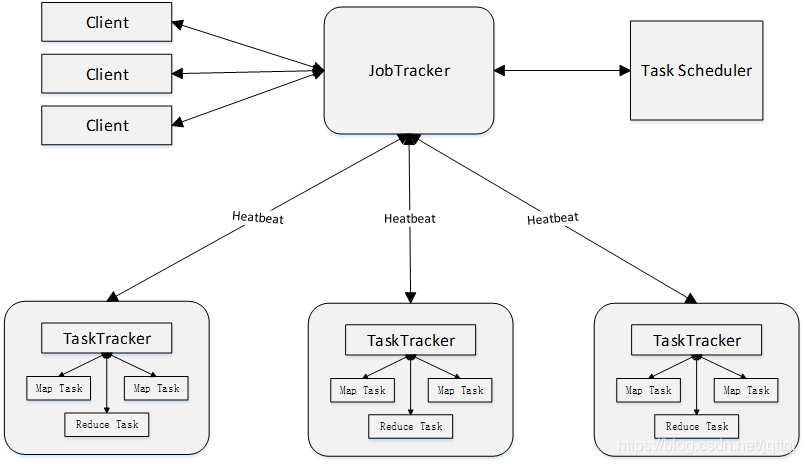
工作流程:
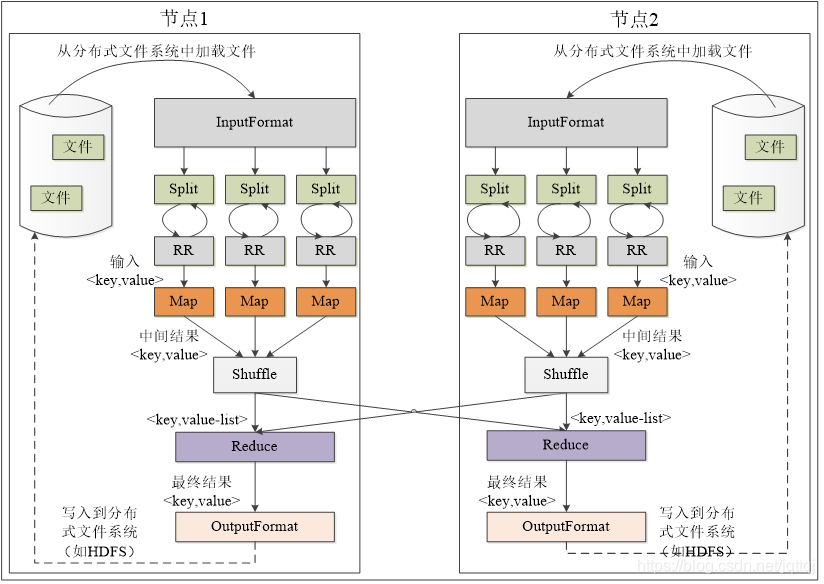
2 wordcount详解
-
分割split 键值对<字符串偏移量,字符串>,一个分片对应一个Map
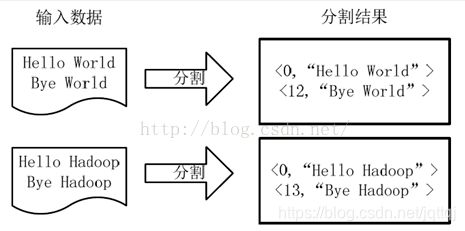
-
map
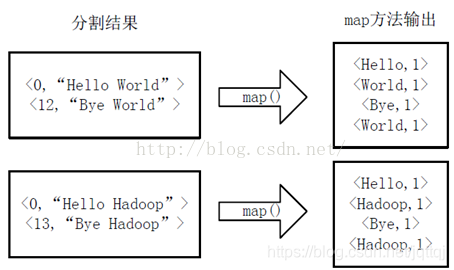
- combine
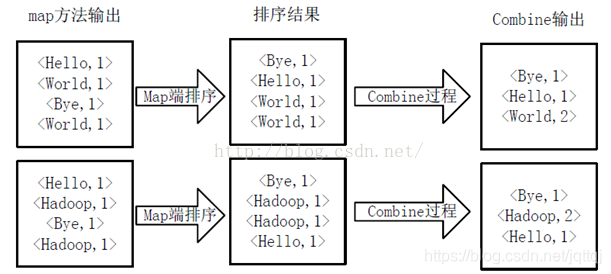
- reduce
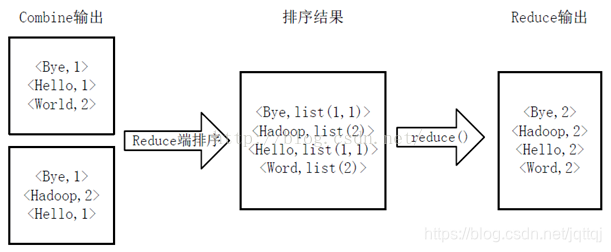
3.Java代码实现
//Map类
/*
* Mapper<输入数据的key,输入数据的value,输出key类型,输出value类型>
*
* */
public class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
Text k=new Text();
IntWritable v =new IntWritable(1);
public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
//读取一行数据,text转换为string
String line = value.toString();
//因为英文字母是以“ ”为间隔的,因此使用“ ”分隔符将一行数据切成多个单词并存在数组中
String str[] = line.split("");
//循环迭代字符串,将一个单词变成<key,value>形式,写入环形缓冲区
for(String s :str){
k.set(s);
context.write(k,v);
}
}
}
//Reduce类
public class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
//重写了reduce类
public void reduce(Text key, Iterable<IntWritable> values,Context context)throws IOException,InterruptedException{
int count = 0;
for(IntWritable value: values) {
count+=value.get();
}
context.write(key,new IntWritable(count));
}
}
//测试类
public class application {
public static void main(String[] args)throws Exception{
Configuration conf = new Configuration();
//1获取job对象
Job job = Job.getInstance(conf);
//2设置jar的存储位置
job.setJarByClass(application.class);
//3设置实现了map函数和reduce函数的类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//4设置mapper阶段k,v的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5设置最终输出的k,v的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6设置输入文件的路径,输出路径,输入从HDFS中读取。读取文件路径从脚本文件中传进来
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7提交job,成功打印0,失败打印1
System.exit(job.waitForCompletion(true) ? 0 :1);
}
}
4.YARN框架
与原框架的区别:
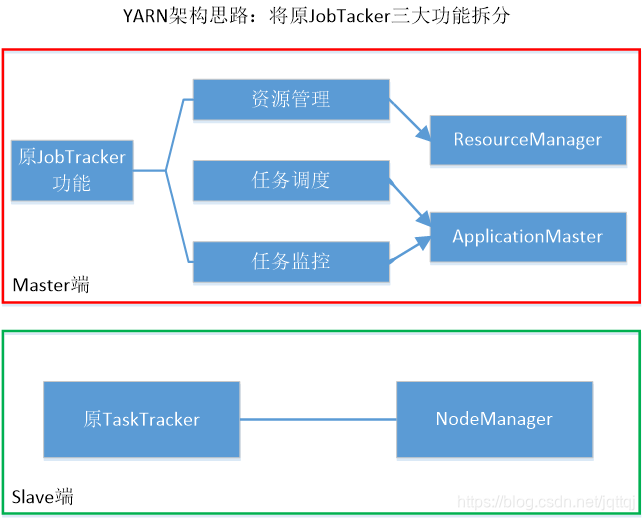
ResourceManager是一个全局的资源管理器,负责整个系统的资源管理和分配
AppMaster负责与RM调度器协商以获取资源任务分配, 监控所有任务运行状态
NodeManager 管理 container、资源下载、健康检测, 是每个节点上的资源和任务管理器
工作机制:
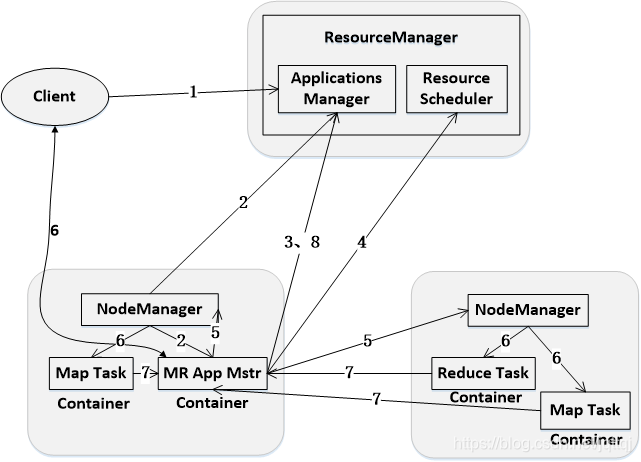
1.客户端向RM提交任务请求,启动AppManager
2.先根据资源和队列是否满足要求选择一个NM,通知它启动一个特殊的container,称为MR App Master,后续流程由它发起。
3.MR App Master根据自己任务的需要,向 RM 申请 container,包括数量、所需资源量、所在位置等因素。
4.如果队列有足够资源,RS会将container分配给MR App Master。
5.MR App Master将资源分配给各个NM
6.每个NodeManager都会启动各自的Task
7.Task向MR App Mster汇报任务的状态和进度
NM,通知它启动一个特殊的container,称为MR App Master,后续流程由它发起。
3.MR App Master根据自己任务的需要,向 RM 申请 container,包括数量、所需资源量、所在位置等因素。
4.如果队列有足够资源,RS会将container分配给MR App Master。
5.MR App Master将资源分配给各个NM
6.每个NodeManager都会启动各自的Task
7.Task向MR App Mster汇报任务的状态和进度
8.任务完成后MR App Master将结果上报给AM并注销关闭自己并允许属于它的container被收回

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









