






文章目录
1.基本概念
特点
主要采集日志文件,实时采集流式文件,高扩展性,高可靠性(不会出现数据采集一半成功一半失败),高度可定制化(配置文件)
安装
- 将安装包解压至指定目录,在conf目录下的flume-env.sh. template重命名为 flume-env.sh 并修改此配置文件的JAVA_HOME
- 添加环境变量,flume-ng version 查看flume的版本号
- 配置分布式flume只需将文件传递到各个节点上并配置环境变量即可
配置Agent
从telent端口输入数据,数据源为netcat类型,将采集到的数据放入内存中,将数据从缓存中拉取并放入sink类型的Logger中,最后打印输出。

在conf目录中新建netcat-logger.conf 配置以下内容:
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
启动任务
#-c 配置文件路径 -f 配置方案的路径 -n agent名称 打印设置
flume-ng agent -c /usr/local/flume/conf/ -f /usr/local/flume/conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
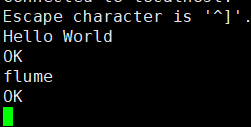
#在另一个端口开启44444,输入的内容会被采集
telnet localhost 44444
2.Agent组件及应用
| Source类型 | 描述 |
|---|---|
| Exec Source | 执行某个命令或脚本,可以将命令产生的输出作为源 |
| Avro Source | 监听Avro端口来接收外部Avro客户端的事件流 |
| Channel类型 | 描述 |
|---|---|
| Memory Channel | 事件将被存储在内存中,读写速度快,存储容量小 |
| File Channel | 事件被存储在磁盘中,数据不易丢失,性能较低 |
| JDBC Channel | 事件存储在关系数据库中,支持的数据库仅Derby,用于测试 |
| Kafka Channel | 事件存储在Kafka集群中,高可靠、高可用 |
| Sink类型 | 描述 |
|---|---|
| HDFS Sink | 将数据写到HDFS |
| Avro Sink | 使用Avro协议将数据发送到另一个FlumeAgent |
| Thrift Sink | 同Avro,传输协议为Thrift |
| Fileroll Sink | 将数据保存到本地文件系统中 |
| HBase Sink | 将数据写到HBase中 |
| Kafka Sink | 将数据写入Kafka组件中 |
任务1
从本地的/opt/logs采集数据并输出到logger中
1.在conf目录下新建spool-memory-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#设置source类型为监控目录类型spooldir
a1.sources.r1.type=spooldir
a1.sources.r1.fileHeader=false
#要监控的目录
a1.sources.r1.spoolDir=/opt/logs
a1.sources.channels=c1
#设置channel类型为内存
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#通道中最大处理事件数
a1.channels.c1.transactionCapacity=100
#sink的类型Logger
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
2.启动任务并将文件传入logs目录中 会打印出logs中的内容
任务2
配置中间缓存采用磁盘存储,从44444端口采集数据到Logger
1.在conf目录下新建netcat-file-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#设置source类型为netcat
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
a1.sources.r1.channels=c1
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/home/jqt/flume/chk
a1.channels.c1.dataDir=/home/jqt/flume/data
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
启动任务,在44444端口采集的数据会被保存至本地目录中
任务3
配置44444端口采集数据到HDFS
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.path=hdfs://Master:9000/data/flumeData
a1.sinks.s1.hdfs.fileType=DataStream
a1.sinks.s1.hdfs.rollInterval=0
a1.sinks.s1.hdfs.rollSize=0
a1.sinks.s1.hdfs.rollCount=5
a1.sinks.s1.channel=c1
3.通道
3.1 组成

3.2 拦截器
任务1
添加时间戳
#作用:将时间戳插入到flume的事件报头中
#在netcat-logger.conf添加时间戳拦截器
a1.sources.r1.interceptors=ts
a1.sources.r1.interceptors.ts.type=timestamp
#若事件中报头时间戳信息已经存在,会替换时间戳报头的值
a1.sources.r1.interceptors.preserveExisting=false

会将加入的数据和时间戳设置为键值对的形式
任务2
使用正则表达式进行过滤
#作用:根据需要收集满足正则条件的日志
#在netcat-logger.conf添加相关设置
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=REGEX_FILTER
#只收集spark或者hadoop
a1.sources.r1.interceptors.i1.regex=(spark)|(hadoop)
#默认收集匹配到的事件
a1.sources.r1.interceptors.i1.excludeEvents=false
3.3 Channel选择器
任务1
复制选择器的使用
定义复制选择器,将事件写入两个Memory Channel,分别存储到HDFS和打印到Logger中
新建netcat-memory-logger-hdfs.conf
a1.sources=r1
a1.channels=c1 c2
a1.sinks=s1 s2
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
#设置2个通道,复制选择器
a1.sources.r1.channels=c1 c2
a1.sources.r1.selector=replication
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
a1.sinks.s2.type=hdfs
a1.sinks.s2.channel=c2
a1.sinks.s2.hdfs.path=hdfs://Master:9000/data/flume/netcat
a1.sinks.s2.hdfs.fileType=DataStream
3.4 Sink处理器
决定sink组里哪个sink处理channel的事件
| Sink处理器类型 | 描述 |
|---|---|
| Load-Balancing Sink处理器 | Load-Balancing Sink 处理器从Sink组所有的Sink中选择一个Sink,处理来自Channel的事件。 |
| Failover Sink处理器 | Failover Sink处理器从Sink组中以优先级的顺序选择Sink。拥有最高优先级的Sink先写数据直到它失败,然后选择组中其他Sink中拥有最高优先级的Sink。 |
任务1
定义sink组,设置logger优先级高于本地目录的sink
新建netcat-logger-processor.conf 本地目录要事先新建好
a1.sources=r1
a1.channels=c1
a1.sinks=s1 s2
#设置sink组名称
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=s1 s2
a1.sinkgroups.g1.processor.type=failover
#s2设置为高优先级,优先级越高数字越大
a1.sinkgroups.g1.priority.s1=1
a1.sinkgroups.g1.priority.s2=2
#设置数据为netcat端口采集的数据
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#将数据保存到本地文件系统中file_roll
a1.sinks.s1.type=file_roll
a1.sinks.s1.sink.directory=/opt/filerolls
a1.sinks.s1.channel=c1
a1.sinks.s2.type=logger
a1.sinks.s2.channel=c1
4.常见的Agent配置方案
方案1:采集新增source到logger

#新建exec-memory-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#执行某个命令或脚本,可以将命令产生的输出作为源exec
a1.sources.r1.type=exec
#获取新增文件
a1.sources.r1.command=tail -f /opt/log.00
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
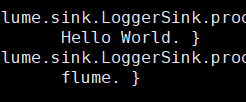
采集原有数据后,输入命令echo “I like flume”>>log.00 会采集到新增语句
方案2:从Avro端口采集数据到logger

#新建avro-memory-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
#监听Avro端口来接收外部Avro客户端的事件流
a1.sources.r1.type=avro
a1.sources.r1.bind=localhost
a1.sources.r1.port=4141
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=logger
a1.sinks.s1.channel=c1
启动avro-memory-logger.conf后,启动avro客户端
#-c 配置文件的位置 -h 主机名 -p 端口号 -f 读取文件的目录
flume-ng avro-client -c /usr/local/flume/conf/ -h localhost -p 4141 -f /opt/log.00
采集到avro log.00的内容
方案3:收集文件后输出到Avro指定端口,另一台机器从该端口读取,并输出logger。
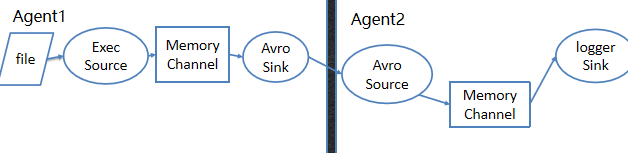
在master节点中新建exec-memory-avro.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -f /opt/log.00
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=Slave1
a1.sinks.s1.port=4141
a1.sinks.s1.channel=c1
在slave1中新建avro-memory-logger.conf
a2.sources=r1
a2.channels=c1
a2.sinks=s1
a2.sources.r1.type=avro
a2.sources.r1.bind=Slave1
a2.sources.r1.port=4141
a2.sources.r1.channel=c1
a2.channels.c2.type=memory
a2.channels.c2.capacity=1000
a2.channels.c2.transactionCapacity=100
a2.sinks.s1.type=logger
a2.sinks.s1.channel=c1
[注]:slave节点的flume用来采集master节点中的本地内容,所以需要先启动slave节点的flume
方案4:两台服务器收集实时产生的日志,汇总到第三台服务器的HDFS中并添加拦截器生成存储目录结构
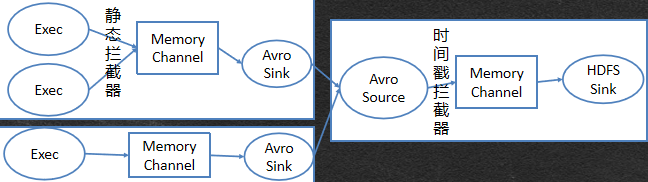
在master节点上新建exec2-memory-avro.conf
a1.sources=r1 r2
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -f /opt/access.log
a1.sources.r1.channels=c1
#静态拦截器
a1.sources.r1.interceptors=st1
a1.sources.r1.interceptors.st1.type=static
#设置键值对 事件头的key为文件类型,value为文件名
a1.sources.r1.interceptors.st1.key=type
a1.sources.r1.interceptors.st1.value=accsee
#若报头中以及存在了key,false表示不替换
a1.sources.r1.interceptors.st1.preserveExisting=false
a1.sources.r2.type=exec
a1.sources.r2.command=tail -f /opt/ng.log
a1.sources.r2.channels=c1
a1.sources.r2.interceptors=st2
a1.sources.r2.interceptors.st2.type=static
a1.sources.r2.interceptors.st2.key=type
a1.sources.r2.interceptors.st2.value=ng
a1.sources.r2.interceptors.st2.preserveExisting=false
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=Slave2
a1.sinks.s1.port=4141
a1.sinks.s1.channel=c1
在slave1节点上新建exec-memory-avro.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -f /opt/web.log
a1.sources.r1.channels=c1
a1.sources.r1.interceptors=st1
a1.sources.r1.interceptors.st1.type=static
a1.sources.r1.interceptors.st1.key=type
a1.sources.r1.interceptors.st1.value=web
a1.sources.r1.interceptors.st1.preserveExisting=true
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=Slave2
a1.sinks.s1.port=4141
a1.sinks.s1.channel=c1
在slave2节点上新建avro-memory-hdfs.conf
a1.sources=r1
a1.channels=c1
a1.sinks=s1
a1.sources.r1.type=avro
a1.sources.r1.bind=Slave2
a1.sources.r1.port=4141
a1.sources.r1.channels=c1
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.sinks.s1.type=hdfs
a1.sinks.s1.hdfs.fileType=DataStream
#通过键type获取文件名作为路径名,通过时间戳拦截器获取当前文件的传入时间,作为路径名
a1.sinks.s1.hdfs.path=hdfs://Master:9000/data/flume/logs/%{type}/%y%m%d
#定义文件名称的前缀
a1.sinks.s1.hdfs.filePrefix=events
#不按照文件大小和时间来滚动
a1.sinks.s1.hdfs.rollInterval=0
a1.sinks.s1.hdfs.rollSize=0
#按照100个临时文件滚动成一个目标文件
a1.sinks.s1.hdfs.rollCount=100
a1.sinks.s1.channel=c1
【注】:必须先启动slave2节点,否则采集不到数据
5.Flume+Kafka架构
一般使用Flume+Kafka架构都是希望完成实时流式的日志处理 。
优点
kafka可以当做一个消息缓存队列,从广义上理解就是一个数据库,可以存放一段时间的数据;Kafka属于中间件,一个明显的优势就是使各层解耦,使得出错时不会干扰其他组件;使用Kafka可以一边将数据同步到hdfs中做离线处理,一边做实时的处理, 实现数据多分发 。
实操
1.编写配置文件netcat-memory-kafka.conf,放入指定目录
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#设置采集数据为端口输入
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels=c1
#设置通道为缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#设置kafkaSink 注意大小写
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置kafka的主题topic
a1.sinks.k1.topic = kafka_netcat_test
#设置kafka 的 broker地址以及端口号
a1.sinks.k1.kafka.bootstrap.servers = slave1:9092,slave2:9092,slave3:9092
#设置kafka序列化方式
a1.sinks.k1.serializer.class = kafka.serializer.StringEncoder
a1.sinks.k1.channel = c1
2.启动consumer并指定topic。此时,Kafka的producer就是flume采集到的数据
#创建主题kafka_netcat_test,启动consumer并指定该topic
bin/kafka-topics.sh --bootstrap-server Slave1:9092,slave2:9092,slave3:9092 --create --topic kafka_netcat_test --replication-factor 2 --partitions 2
bin/kafka-console-consumer.sh --bootstrap-server Slave1:9092,slave2:9092,slave3:9092 --topic kafka_netcat_test --partition 0 --from-beginning
3 .启动Flume
flume-ng agent -c /usr/local/flume/conf/ -f /usr/local/flume/conf/netcat-memory-kafka.conf -n a1 -Dflume.root.logger=INFO,console
4.监听44444端口,输入数据,此时 consumer的界面会接收到这些信息
#监听44444端口
telnet localhost 44444
#创建consumer
bin/kafka-console-consumer.sh --bootstrap-server Slave1:9092,slave2:9092,slave3:9092 --topic kafka_netcat_test --partition 0 --from-beginning
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









