






配置版本信息:spark-2.3.4,Kafka-2.10,Scala-2.11,JDK8
1.创建Maven工程
配置Pom文件
<properties>
<spark.version>2.3.4</spark.version>
<kafka.version>2.1.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
连接Kafka并进行词频统计
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Duration, Seconds, StreamingContext}
object SSKafka_Direct {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming")
val ssc = new StreamingContext(sparkConf,Duration(10000)) //采集周期10s
//TODO SparkStreaming读取Kafka的数据
//kafka配置信息
val kafkaPara: Map[String, Object] = Map[String, Object](
//zookeeper地址
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "slaver1:9092,slaver2:9092,slaver3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "app",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
//订阅的topic名kafka_spark
ConsumerStrategies.Subscribe[String, String](Set("kafka_spark"), kafkaPara))
val valueDStream: DStream[String] = kafkaDStream.map(record=>record.value())
valueDStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
注1:new不出Scala文件
1.检查是否安装了Scala插件
2.检查是否将目录设置为source
3.检查是否导入scala JDK,在projectStructure—>Modules—>Dependencies中+—>Libraray—>scalaSDK
注2:在运行的时候报错:找不到或者加载不到主类
版本不兼容,使用上文提供的POM文件即可解决
2.创建生产者,发送数据
依次启动zookeeper,Hadoop,Kafka,spark
创建topic,生产者
kafka-topics.sh --create --zookeeper slaver1:2181 --replication-factor 1 --partitions 3 --topic kafka_spark
kafka-console-producer.sh --broker-list slaver1:9092 --topic kafka_spark
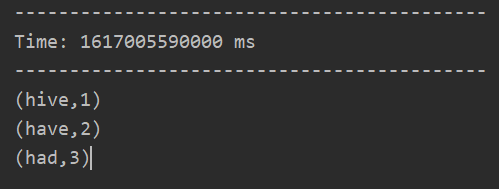
启动程序,在消费者端口输入单词,运行结果如下:















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









