







命令:切换到hive的安装目录,输入:./bin/hive
问题:
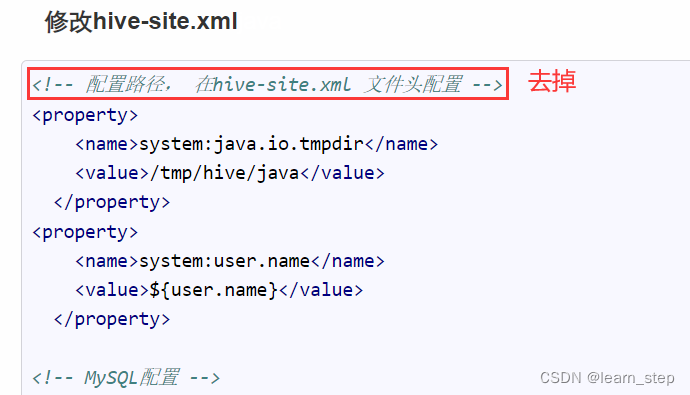
1、切换到hive的安装目录下,输入hive,报错java.io.CharConversionException: Invalid UTF-8 middle byte 0xe4 (at char #93, byte #20)

处理:hive-site不能有注释部分
2、hadoop fs -mkdir /hive/warehouse提示No such file or directory
直接在目录下创建好的也不行。
处理:切换到/目录,一级级创建
hadoop fs -mkdir /hive
cd /hive
hadoop fs -mkdir /hive/warehouse
授权
hdfs dfs -chmod 755 /hive/warehouse
3、hive客户端不能使用
mapred-site.xml
增加配置
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop-3.3.6/etc/hadoop,
/usr/local/hadoop-3.3.6/share/hadoop/common/lib/*,
/usr/local/hadoop-3.3.6/share/hadoop/common/*,
/usr/local/hadoop-3.3.6/share/hadoop/hdfs,
/usr/local/hadoop-3.3.6/share/hadoop/hdfs/lib/*,
/usr/local/hadoop-3.3.6/share/hadoop/hdfs/*,
/usr/local/hadoop-3.3.6/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop-3.3.6/share/hadoop/mapreduce/*,
/usr/local/hadoop-3.3.6/share/hadoop/yarn,
/usr/local/hadoop-3.3.6/share/hadoop/yarn/lib/*,
/usr/local/hadoop-3.3.6/share/hadoop/yarn/*
</value>
</property>














 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









