




 本文深入探讨集合的概念,集合与数组的区别,集合框架的组成,数据存储结构分类,以及Collection、Set、List、Map接口的特点和实现。通过示例展示了如何使用HashSet、ArrayList、LinkedList、HashMap等集合类。
本文深入探讨集合的概念,集合与数组的区别,集合框架的组成,数据存储结构分类,以及Collection、Set、List、Map接口的特点和实现。通过示例展示了如何使用HashSet、ArrayList、LinkedList、HashMap等集合类。
集合的概念:
集合与数组的特点对比:
集合:数量不限、类型不限
数组:定长、类型单一
“集合框架”由一组用来操作对象的接口组成,不同接口描述不同类型的组
数据存储结构分类:
(1)顺序存储 (2)链式存储 (3)树形存储 (4)散列存储Hash (5)Map映射存储
| 接口 | 实现 | 历史集合类 |
| Set | HashSet | |
| TreeSet | ||
| List | ArrayList | Vector |
| LinkedList | Stack | |
| Map | HashMap | Hashtable |
| TreeMap | Properties |
集合框架中各接口的特点:
1:Collection接口 是一组允许重复的对象。
2:Set接口 继承Collection,无序但不允许重复。
3:List接口 继承Collection,有序但允许重复,并引入位置下标。
4:Map接口 既不继承Set也不继承Collection,是键值对。
Collection接口:
用于表示任何对象或元素组。想要尽可能以常规方式处理一组元素时,就使用这一接口。
| 方法摘要 | ||
|---|---|---|
boolean | add(E e) 确保此 collection 包含指定的元素(可选操作)。 | |
boolean | addAll(Collection<? extends E> c) 将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。 | |
void | clear() 移除此 collection 中的所有元素(可选操作)。 | |
boolean | contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 | |
boolean | containsAll(Collection<?> c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 | |
boolean | equals(Object o) 比较此 collection 与指定对象是否相等。 | |
int | hashCode() 返回此 collection 的哈希码值。 | |
boolean | isEmpty() 如果此 collection 不包含元素,则返回 true。 | |
Iterator<E> | iterator() 返回在此 collection 的元素上进行迭代的迭代器。 | |
boolean | remove(Object o) 从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。 | |
boolean | removeAll(Collection<?> c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。 | |
boolean | retainAll(Collection<?> c) 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。 | |
int | size() 返回此 collection 中的元素数。 | |
Object[] | toArray() 返回包含此 collection 中所有元素的数组。 | |
| toArray(T[] a) 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。 | |
<pre name="code" class="java">//可初定义容量大小为0
//Set是接口,必须new它的实现类
//HashSet是一组不
Set<Object> set=new HashSet<Object>(0);
Set<Object> set2=new HashSet<Object>(0);
Person p1=new Person("张三",20);
Person p2=new Person("李四",22);
Person p3=new Person("王五",24);
Person p4=new Person("Jack",30);
Person p5=new Person("Tom",20);
Person p6=new Person("Swite",13);
Person p7=new Person("Pick",16);
Person p8=new Person("钱七",32);
//添加元素,集合容量会增加(JAVA类中有操作),返回型boolean
//注意添加的是元素的地址,改变集合中的一个元素,另一集合的相同元素同样改变
//添加顺序是根据Hash算法排序的,因此需要实现添加元素的hashCode和equals函数
//不然按该元素的内存地址排序
set.add(p1);set2.add(p1);
System.out.println(set.add(p1));//返回FALSE,已加入元素不会重复添加
set.add(p5);set2.add(p5);
set.add(p6);set2.add(p6);
set.add(p4);set2.add(p7);
set.add(p2);set2.add(p8);
set.add(p3);
//在set2中元素全部加入,有添加的元素,返回true
set.addAll(set2);
//将集合的所有元素清空
set.clear();
//判断集合中有无此元素,有则返回true,
set.contains(p1);
//判断集合set2中的元素是否在set集合中都有,返回boolean值
set.containsAll(set2);
//判断参数对象与此对象的相等性
set.equals(p1);//false(即使集合中只有p1,也不会相等,因为是不同对象)
//若俩个集合中的元素相等,则俩个集合相等,
set.equals(set2);//false
//判断集合是否是空
set.isEmpty();
//获得集合元素的个数
set.size();
//移除集合的某一个元素,返回boolean值,没有则返回false
set.remove(p1);
//移除既在参数集合中存在,又在此集合中存在的元素,取差集,返回值boolean值
set.removeAll(set2);
//移除不存在参数集合中的本集合元素,取交集,返回值boolean值
set.retainAll(set2);
//返回集合的迭代器,以便搜索集合的元素
//因为HashSet是按哈希值存储,不便直接定位
Iterator<Object> it =set.iterator();
while(it.hasNext()){
//依次输出集合的每一个元素的toString()
System.out.println(it.next());
}2、Character 按Unicode值的数字大小排序
3、CollationKey 按语言环境敏感的字符串排序
4、Date 按年代排序
5、File 按系统特定的路径名的全限定字符的Unicode值排序
6、ObjectStreamField 按名字中字符的Unicode值排序
7、String 按字符串中字符Unicode值排序
public class TreeSetDome {
public static void main(String[] args) {
<span style="color:#ff0000;">//TreeSet具有set接口的所有函数(上面的函数)</span>
//在new时可以加入指定的比较器
TreeSet<Object> set=new TreeSet<Object>(new MyComp());
Person p1=new Person("张三",20);
//TreeSet具有其他函数
//返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null
set.ceiling(p1);
//返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回 null。
set.floor(p1);
//返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。
set.comparator();
//返回此 set 中当前第一个(最低)元素。
set.first();
//返回此 set 中当前最后一个(最高)元素。
set.last();
//返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回 null。
set.higher(p1);
//返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。
set.lower(p1);
//获取并移除第一个(最低)元素;如果此 set 为空,则返回 null。
set.pollFirst();
//获取并移除最后一个(最高)元素;如果此 set 为空,则返回 null。
set.pollLast();
}
}
class MyComp implements Comparator<Object>{
@Override
public int compare(Object o1, Object o2) {
//返回值为负整数,0,正整数(int型)
//表示本对象比参数对象小,相等,大
return 1;
}
}List接口继承了Collection接口以定义一个允许重复项的有序集合。该接口不但能够对列表的一部分进行处理,还添加了面向位置的操作。面向位置的操作包括插入某个元素或Collection的功能,还包括获取、除去或更改元素的功能。在List中搜索元素可以从列表的头部或尾部开始,如果找到元素,还将报告元素所在的位置。
1)使用List(如ArrayList)时,不会自动调用hashCode()方法。因为在List中,重复了就重复了,不需判断,保证唯一性。
2)List中添加了下标index的功能,这样对List的修改可以利用set方法对指定位置的元素直接进行替换,不需要象Set那么复杂(要转换成数组才能修改,之后还要转换回去)。
3)Collection用Iterator迭代器,而List可以用ListIterator列表迭代器。前者只能next(),后者不但包含next()方法,还包含previous()方法。因此,如果要用List做类似书的翻页功能,不但可以向后翻,还可以向前翻。
package cn.hncu.collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
public class ArrayListDome {
public static void main(String[] args) {
//List接口引入了下标,并且可以添加重复的元素
ArrayList<Object> al1=new ArrayList<Object>(0);
ArrayList<Object> al2=new ArrayList<Object>(0);
Person p1=new Person("张三",20);
Person p2=new Person("李四",22);
Person p3=new Person("王五",24);
Person p4=new Person("Jack",30);
Person p5=new Person("Tom",20);
Person p6=new Person("Swite",13);
Person p7=new Person("Pick",16);
Person p8=new Person("钱七",32);
//添加时,根据下标位置排序,无需实现元素的hashCode和equals方法
//可以指定下标添加,但要注意,不能加入的下标大小比集合容量大,否则出异常
al1.add(p1);
al1.add(0,p2);
al1.add(al1.size()-1,p3);
al1.add(p4);
al1.add(p5);
al1.add(0,p6);
al2.add(p2);
al2.add(p4);
al2.add(p6);
al2.add(p8);
//可以添加其他集合的指定位置
al1.addAll(0, al2);
//返回此列表中指定位置上的元素。
al1.get(0);
//返回此列表中首次出现的指定元素的索引,或如果此列表不包含元素,则返回 -1。
al1.indexOf(p1);
//返回此列表中最后一次出现的指定元素的索引,或如果此列表不包含索引,则返回 -1。
al1.lastIndexOf(p1);
//移除此列表中指定位置上的元素。
al1.remove(0);
//用指定的元素替代此列表中指定位置上的元素。
al1.set(0, p2);
//按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组。
al1.toArray();
//按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
Person[] a = new Person[0];
a=al1.toArray(a);
//将此 ArrayList 实例的容量调整为列表的当前大小。
al1.trimToSize();
//返回列表中索引在 fromIndex(包括)和 toIndex(不包括)之间的所有元素组成一个新的集合列表。
al1.subList(0, 1);
//返回此 ArrayList 实例的浅表副本。只是复制了指针,俩个集合共用元素
ArrayList<Object> po=(ArrayList<Object>) al1.clone();
((Person)al1.get(0)).age=10000;
((Person)al2.get(0)).age=-300;
for (int i = 0; i < po.size(); i++) {
System.out.println(po.get(i));
}
//返回列表的迭代器
ListIterator it=al1.listIterator();
while(it.hasNext()){
System.out.println(it.next());//当前的下一个
System.out.println(it.previous());//当前的上一个
}
}
}
如果要支持随机访问,而不必在除尾部的任何位置插入或除去元素,那么,ArrayList提供了可选的集合。(查找)
但如果要频繁的从列表的中间位置添加和除去元素,而只要顺序的访问列表元素,那么 LinkedList实现更好(添加,删除)//构造空的
LinkedList list=new LinkedList();
Person p1=new Person("张三",20);
<span style="color:#ff0000;">//链表也具有排序和下标功能,ArrayList的函数</span>
//将指定元素插入此列表的开头。
list.addFirst(p1);
list.offerFirst(p1);
//将指定元素添加到此列表的结尾。
list.addLast(p1);
list.offer(p1);
list.offerLast(p1);
// 获取但不移除此列表的头(第一个元素)。
list.element();
list.get(0);
list.getFirst();
list.peek();
list.peekFirst();//没有返回空
//获取并移除此列表的头(第一个元素)
list.pop();
list.pollFirst();//没有返回空
list.remove(0);
list.removeFirst();
//移 不移除列表的尾而获得同头部;
list.peekLast();
list.getLast();
list.pollLast();
list.removeLast();
//从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。
list.removeFirstOccurrence(p1);
//从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。
list.removeLastOccurrence(p1);
ArrayList<Object> al=new ArrayList<Object>(0);
public void push(Object obj){
al.add(obj);
}
public Object pop(){
if(!al.isEmpty())
return al.remove(0);
return null;
}
public boolean isEmpty(){
return al.isEmpty();
}ArrayList<Object> al=new ArrayList<Object>(0);
public void push(Object obj){
al.add(obj);
}
public Object pop(){
if(!al.isEmpty())
return al.remove(al.size()-1);
return null;
}
public boolean isEmpty(){
return al.isEmpty();
}LinkedList<Object> lkl=new LinkedList<Object>();
public void push(Object obj){
lkl.add(obj);
}
public Object pop(){
return lkl.poll();
}
public boolean isEmpty(){
return lkl.isEmpty();
}LinkedList<Object> lkl=new LinkedList<Object>();
public void push(Object obj){
lkl.add(obj);
}
public Object pop(){
return lkl.pollLast();
}
public boolean isEmpty(){
return lkl.isEmpty();
}可以把这个接口方法分成三组操作:改变、查询和提供可选视图。
改变操作允许从映射中添加和除去键-值对。键和值都可以为null。但是, 不能把 Map 作为一个键或值添加给自身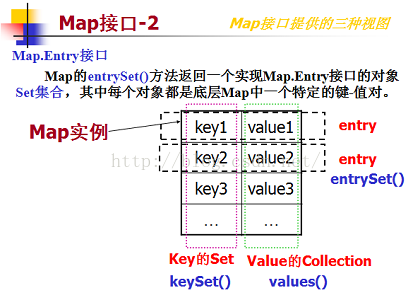
HashMap<String, Object> map=new HashMap<String, Object>(0);
Person p1=new Person("张三",20);
Person p2=new Person("李四",22);
Person p3=new Person("王五",24);
Person p4=new Person("Jack",30);
Person p5=new Person("Tom",20);
Person p6=new Person("Swite",13);
//键-值添加,put函数
map.put("1001", p1);
map.put("1002", p2);
map.put("1003", p3);
map.put("1004", p4);
map.put("1005", p5);
map.put("1006", p6);
//返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。
map.get("1001");
//从此映射中移除指定键的映射关系(如果存在)。
map.remove("1001");
//移除集合
map.clear();
//entry视图
Set<Map.Entry<String, Object>> entry=map.entrySet();
Iterator<Map.Entry<String, Object>> it=entry.iterator();
while(it.hasNext()){
Map.Entry<String, Object> en=it.next();
System.out.println(en.getKey()+" "+en.getValue());
}
System.out.println("------------------");
//key视图
Set<String> keys=map.keySet();
Iterator<String> it2=keys.iterator();
while(it2.hasNext()){
String str=it2.next();
System.out.println(str+" "+map.get(str));
}
System.out.println("------------------");
//values视图(不常用)
Collection<Object> values=map.values();
Iterator<Object> it3=values.iterator();
while(it3.hasNext()){
Object obj=it3.next();
System.out.println(obj);
}“集合框架”提供两种常规的Map实现:HashMap和TreeMap。和所有的具体实现一样,使用哪种实现取决于特定需要。
在Map中插入、删除和定位元素,HashMap是最好的选择。但如果要按顺序遍历键,那么TreeMap会更好。
使用HashMap要求添加的键类明确定义了hashCode()实现(助理解:Map.keySet返回的是键的Set集合,而Set集合对hashCode实现有限制,因此作为键的类也要遵守该限制)。有了TreeMap实现,添加到映射的元素一定是可排序的。
中文排序问题比较函数对于英文字母与数字等ASCII码中的字符排序都没问题,但中文排序则明显不正确。这主要是Java中使用中文编码GB2312或GBK时,char型转换成int型的过程出现了比较大的偏差。这偏差是由compare方法导致的,因此我们可以自己实现Comparator接口。另外,国际化问题可用Collator类来解决。
java.text.Collator类,提供以与自然语言无关的方式来处理文本、日期、数字和消息的类和接口。

















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









