






入侵检测实验一般使用的是KDD CUP99中的kddcup_data_10percent数据集。由于数据集中包含有符号型的数据属性,不适合聚类测试,对于连续型特征属性,各属性的度量方法不一样。一般而言,所用的度量单位越小,变量可能的值域就越大,这样对聚类结果的影响也越大,即在计算数据间距离时对聚类产生的影响越大。为了避免由于属性度量的差异对聚类产生的影响,需要对属性属性值进行标准化。
本文是对https://blog.csdn.net/asialee_bird/article/details/80491256的补充。感谢该博主的分享与启发。
1.字符型特征转换为数值型特征
见上面的链接。
2.数值标准化
首先计算各属性的平均值![]() 和平均绝对误差
和平均绝对误差![]() ,公式为
,公式为
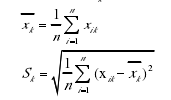
其中,![]() 表示第k个属性的均值,
表示第k个属性的均值,![]() 表示第k个属性的平均绝对误差,
表示第k个属性的平均绝对误差,![]() 表示第i条记录的第k个属性。
表示第i条记录的第k个属性。
然后对每条数据记录进行标准化度量,即
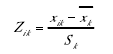
其中,![]() 表示标准化后的第i条数据记录的第k个属性值。
表示标准化后的第i条数据记录的第k个属性值。
Python3 对数据集的数据标准化方法实现如下:
def Handle_data():
source_file = "kddcup.data_10_percent_corrected.csv"
handled_file = "kddcup1.data_10_percent_corrected.csv"
data_file = open(handled_file,'w',newline='')
with open(source_file,'r') as data_source:
csv_reader = csv.reader(data_source)
count = 0
row_num = ""
for row in csv_reader:
count = count+1
row_num = row
sum = np.zeros(len(row_num)) #和
sum.astype(float)
avg = np.zeros(len(row_num)) #平均值
avg.astype(float)
stadsum = np.zeros(len(row_num)) #绝对误差
stadsum.astype(float)
stad = np.zeros(len(row_num)) #平均绝对误差
stad.astype(float)
dic = {}
lists = []
for i in range(0,len(row_num)):
with open(source_file,'r') as data_source:
csv_reader = csv.reader(data_source)
for row in csv_reader:
sum[i] += float(row[i])
avg[i] = sum[i] / count #每一列的平均值求得
with open(source_file,'r') as data_source:
csv_reader = csv.reader(data_source)
for row in csv_reader:
stadsum[i] += math.pow(abs(float(row[i]) - avg[i]), 2)
stad[i] = stadsum[i] / count #每一列的平均绝对误差求得
with open(source_file,'r') as data_source:
csv_reader = csv.reader(data_source)
list = []
for row in csv_reader:
temp_line=np.array(row) #将每行数据存入temp_line数组里
if avg[i] == 0 or stad[i] == 0:
temp_line[i] = 0
else:
temp_line[i] = abs(float(row[i]) - avg[i]) / stad[i]
list.append(temp_line[i])
lists.append(list)
for j in range(0,len(lists)):
dic[j] = lists[j] #将每一列的元素值存入字典中
df = pd.DataFrame(data = dic)
df.to_csv(data_file,index=False,header=False)
data_file.close()3.数值归一化
将标准化后的每个数值归一化到[0,1]区间。公式为
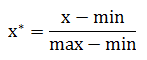
其中max为样本数据的最大值,min为样本数据的最小值,x为标准化后的数据。
Python3 对数据集的数据归一化方法实现如下:
def Find_Maxmin():
source_file = "kddcup1.data_10_percent_corrected.csv"
handled_file = "kddcup2.data_10_percent_corrected.csv"
dic = {}
data_file = open(handled_file,'w',newline='')
with open(source_file,'r') as data_source:
csv_reader=csv.reader(data_source)
count = 0
row_num = ""
for row in csv_reader:
count = count+1
row_num = row
with open(source_file,'r') as data_source:
csv_reader=csv.reader(data_source)
final_list = list(csv_reader)
print(final_list)
jmax = []
jmin = []
for k in range(0, len(final_list)):
jmax.append(max(final_list[k]))
jmin.append(min(final_list[k]))
jjmax = float(max(jmax))
jjmin = float(min(jmin))
listss = []
for i in range(0,len(row_num)):
lists = []
with open(source_file,'r') as data_source:
csv_reader=csv.reader(data_source)
for row in csv_reader:
if (jjmax-jjmin) == 0:
x = 0
else:
x = (float(row[i])-jjmin) / (jjmax-jjmin)
lists.append(x)
listss.append(lists)
for j in range(0,len(listss)):
dic[j] = listss[j]
df = pd.DataFrame(data = dic)
df.to_csv(data_file,index=False,header=False)
data_file.close()初次接触python,接触了其独特的for循环,list列表和字典等语法,待进一步理解。
日技















 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









