







 本文是《Dice Loss for Data-imbalanced NLP Tasks》的阅读笔记,探讨了交叉熵loss在样本不均衡问题上的局限,以及weighted cross entropy的挑战。文章提出自适应Dice loss,通过调整权重降低易学习样本的影响,适用于f1 score导向的任务,但在accuracy-oriented任务上逊于交叉熵。对于数据不平衡的NLP任务,Dice loss提供了新的解决方案。
本文是《Dice Loss for Data-imbalanced NLP Tasks》的阅读笔记,探讨了交叉熵loss在样本不均衡问题上的局限,以及weighted cross entropy的挑战。文章提出自适应Dice loss,通过调整权重降低易学习样本的影响,适用于f1 score导向的任务,但在accuracy-oriented任务上逊于交叉熵。对于数据不平衡的NLP任务,Dice loss提供了新的解决方案。
https://arxiv.org/pdf/1911.02855.pdf
1.几种loss函数:

2.关于交叉熵loss
交叉熵方法是accuracy-oriented的,每个样本的贡献相同。
如果测试集上以f1 score作为主要评估,则更重视对正样本的考量。
若在样本不均衡的情况下使用交叉熵训练会造成训练和测试间的性能差异。
3.关于weighted cross entropy
系数a在[0,1]内,它可以是inverse class frequence 或是一个可调的超参数。
使用weighted cross entropy的方法和对训练数据采样的方法本质是相同的,都是在训练时改变数据的分布。
这两种方法都不常用,因为难以确定何时的a值,不合适的a可能会导致偏向较少的类型。
4.文章提出的自适应Dice loss
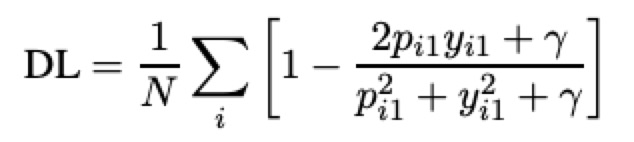
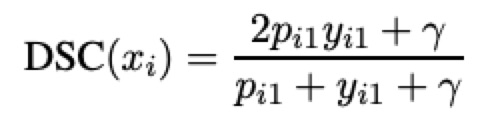 ——>
——>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









