







我自飘零我自狂,犹如云鹤游四方
文章目录
前言
和大家一起共同学习DolphinDB数据库,以下请指教
一、DolphinDB是什么?
DolphinDB呢咱们可以理解为速度很快的 * 时序数据库 * 和数据分析系统,内置并行和分布式计算,可以实时数据处理和多节点计算.(时序数据库就是处理带时间标签的数据,即时间序列数据),那为什么要用它,这个跟物联网有紧密的联系,由于传统的数据库处理物联网数据时有些乏力,功能过剩但性能不足.
由于数据库和开发语言集成,所以速度很快,可以达到毫秒级响应速度.

二、模块
1.高性能数据库
列式混合引擎,分区灵活,支持单表百万分区数,本人最喜欢的就是那个直接在数据库进行编程和计算,很爽的有没有哈哈,拓展了标准sql的功能:窗口连接,透视表等,还有动态增加字段.
2.分布式计算
数据本地化,并行计算内置了多种计算框架,分布式编程等
3.多范式编程语言
友好的是它的语法和sql,py很相似,上手快,直呼:舒服了.还有内置很多的函数和自定义函数.
4.流数据处理
发布订阅的数据模型,消息延迟很低,亚毫秒级,发布一条消息相当于在表中添加一条记录.实时更新数据仓库.
5.系统管理与接口
web服务器,web接口实现系统监控,有集成的开发环境,语言接口:C++, C#, Java, Python, R, JavaScript和Excel。
三.数据类型
1.测试一下string和symbol数据类型的排序速度
一个symbol类型数据被DolphinDB系统内部存储为一个整数,因此数据排序和比较更有效率。因此,使用symbol类型有可能提高系统性能,同时也可节省存储空间。但是,将字符串映射到整数(hash)需要时间,哈希表也会占用内存。

股票交易数据中的股票代码应该使用symbol类型,因为股票代码的数量基本是固定的,在数据中重复极多;另外,股票代码经常被搜索和比较。
描述性字段不应该使用symbol类型,因为描述性字段很少重复,而且很少被搜索、排序或比较。

那么问题来了,怎么创建symbol类型向量呢?请看下面代码块
(1) 使用函数 array 来创建:
syms=array(symbol, 0, 100);
// 创建长度为100的空符号数组;
typestr syms;
//FAST SYMBOL VECTOR
syms.append!(`aaa`bbb`ccc);
syms;
//["aaa","bbb","ccc"]
(2) 通过类型转换来创建:
syms=`IBM`C`MS;
typestr syms;
//STRING VECTOR
// 转换为符号向量;
sym=syms$SYMBOL;
typestr sym;
//FAST SYMBOL VECTOR
typestr syms;
//STRING VECTOR
(3) 使用随机函数 rand.来创建:
syms=`IBM`C`MS;
symRand=rand(syms, 10);
//生成一个随机的symbol类型向量
symRand;
typestr symRand;
//FAST SYMBOL VECTOR
DolphinDB支持的对象类型包括:常量、变量、函数调用、表达式、列引用、表连接器、命名对象和SQL查询。 动态元组和元编程.
四.直接上SQL
DolphinDB的SQL格式与一些关系型数据库管理系统中的标准SQL语言十分相似,比如MySQL, Oracle, SQL Server等(sqlboy:你要是说这个我可就不困了):
select [top_clause] column_expressions
from table_name | table_expression
[where filtering_conditions]
[grouping_clause [having_clause] | order_clause]
区别
1.通常标准SQL语句不区分字母的大小写,而DolphinDB的SQL语句区分大小写。DolphinDB中的SQL关键字必须使用小写。
2.可在SQL查询中直接使用绝大部分函数。
select column_name(s)
from table1 left join table 2
on table1.column_name=table2.column_name
select column_name(s) from lj(table1, table2, column_name)
DolphinDB的语法更简洁。
| 标准sql语法 | DolphinDB语法 |
|---|---|
| where sym=’IBM’ | where sym=IBM (“IBM”) or where sym==IBM (“IBM”) |
| LEFT JOIN | lj, slj |
sql语句
1.select
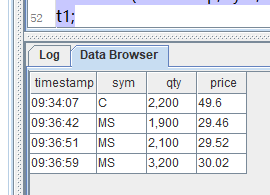
创建表t1
#直接列字段名=列的值 值 值;
#表名=table(列字段,字段名);
sym = `C`MS`MS`MS$SYMBOL
price= 49.6 29.46 29.52 30.02
qty = 2200 1900 2100 3200
timestamp = [09:34:07,09:36:42,09:36:51,09:36:59]
t1 = table(timestamp, sym, qty, price);
t1;
select * from t1;
2.exec
select查询出的不管几列都会是table的形式,如果你要把其中一列变成标量或者向量,比如int类型,要用到exec关键字.
如下代码:
x = select count(price) from t1;
x;
typestr x;
//table
y=exec count(price) from t1;
y;
//9
typestr y;
//现在咱们可以看到输出的是int
3.表连接cross join
交叉连接函数返回两张表的笛卡尔积的结果集。如果左表有n行,右表有m行,那么笛卡尔积结果集含有n*m行。(在DolphinDB中,可以直接取首字母小写去进行表连接的关键字,比如cj>>cross join )
cj(leftTable, rightTable)
4.执行顺序
大多数和标准sql一样,但有一点区别:当使用context by子句时,csort关键字或limit / top子句的执行顺序。
在DolphinDBde 顺序:
from子句 --> where条件 --> group by/ context by / pivot by子句 --> csort关键字(仅为 context by 子句提供) -->having 条件(若使用了group by / context by子句)–>select子句(若select子句指定了计算,此时才执行) --> limit / top子句 (若使用了context by子句)–>order by子句 -->未使用context by的limit / top 子句.
注:context by是DolphinDB独有的功能.用context by时,每一组返回一个和组内元素数量相同的向量。context by既可以配合聚合函数使用,也可以与移动窗口函数或累积函数等其它函数结合使用。context by常用于基于组更新的场景.
总结
这里对文章进行总结:
cv大法水博客,打算更新DolphinDB的全套路线,挖坑:以后会更新到DolphinDB在实际项目中的应用.
官网一手资料,请放心食用















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









