







看了两天理论,终于轮到学习和预测上了。下载安装了CRF++-0.58,准备程序分析来理解CRF的主要过程。
CRF++算法源程序是C++编写的,主要的原生接口有三个:学习和预测用的crf_learn和crf_test,供其他语言调用模型的libcrfpp。官方文档把learn过程看做是encoder,把test看作decoder。
1.学习的过程
执行crf_learn最简洁的命令
crf_learn template_file train_file model_file后面3个参数分别是特征模板、要训练的数据、模型存放文件。除了这三个必须的参数,还有如下可选参数,用于控制训练过程。

对实际的程序,crf_learn.cpp调用了crfpp_learn函数。
int main(int argc, char **argv) {
return crfpp_learn(argc, argv);
}crfpp_learn在文件encoder.cpp里,crfpp_learn上面所提的参数,然后将参数传入Encoder::learn。
bool Encoder::learn(const char *templfile,
const char *trainfile,
const char *modelfile,
bool textmodelfile,
size_t maxitr,
size_t freq,
double eta,
double C,
unsigned short thread_num,
unsigned short shrinking_size,
int algorithm)这个函数根据特征模板抽取训练数据的特征
CHECK_FALSE(feature_index.open(templfile, trainfile))
<< feature_index.what();然后根据传入的参数(algorithm)选择要执行的算法
switch (algorithm) {
case MIRA:
if (!runMIRA(x, &feature_index, &alpha[0],
maxitr, C, eta, shrinking_size, thread_num)) {
WHAT_ERROR("MIRA execute error");
}
break;
case CRF_L2:
if (!runCRF(x, &feature_index, &alpha[0],
maxitr, C, eta, shrinking_size, thread_num, false)) {
WHAT_ERROR("CRF_L2 execute error");
}
break;
case CRF_L1:
if (!runCRF(x, &feature_index, &alpha[0],
maxitr, C, eta, shrinking_size, thread_num, true)) {
WHAT_ERROR("CRF_L1 execute error");
}
break;最后存模型
if (!feature_index.save(modelfile, textmodelfile)) {
WHAT_ERROR(feature_index.what());
}提取特征在feature_index的open中完成,open函数调用openTemplate和openTagSet两个函数,前者读模板文件生成模板,后者读训练文件,逐行读数据,统计数据(但是没有看到和特征模板匹配)。
runCRF函数同在encoder.cpp中
/*****
*x:训练句子的列表
*feature_index:特征统计后的对象
*alpha:特征函数的代价
*maxiter:可执行的最大迭代次数
*C:跟cost相关的超参数,用于平衡过拟合和欠拟合。
*eta:收敛阈值
*shrinking_size:没搞明白是啥
*thread_num:线程数
*orthant:选择正则化方法,false为L2,true为L1
*****/
bool runCRF(const std::vector<TaggerImpl* > &x,
EncoderFeatureIndex *feature_index,
double *alpha,
size_t maxitr,
float C,
double eta,
unsigned short shrinking_size,
unsigned short thread_num,
bool orthant) {runCRF()函数根据thread_num生成CRFEncoderThread线程,线程配置完成后,开启线程执行CRFEncoderThread,并计算误差diff
double diff = (itr == 0 ? 1.0 :
std::abs(old_obj - thread[0].obj)/old_obj);并优化参数lbfgs.optimize优化参数。如果diff连续3次小于eta,或者迭代次数大于等于maxiter,停止训练。
2.学习算法
上一节中提到主要的执行的线程为CRFEncoderThread,而这个线程主要做一件事——计算梯度
void run() {
obj = 0.0;
err = zeroone = 0;
std::fill(expected.begin(), expected.end(), 0.0);
for (size_t i = start_i; i < size; i += thread_num) {
obj += x[i]->gradient(&expected[0]);
int error_num = x[i]->eval();
err += error_num;
if (error_num) {
++zeroone;
}
}
}梯度计算涉及到的前向-后向算法、维特比算法等都在tagger.c中。TaggerImpl这个类包含了主要的计算和标注、预测工作,其中标注、预测相关方法作为接口开给了其他语言,但是主要的计算并没有对其他语言提供调用接口(java和python都是这样的),扯远了。开始真正的算法程序分析吧。
代码是这样的:
/************
*expected:梯度向量
*/
double TaggerImpl::gradient(double *expected) {
if (x_.empty()) return 0.0;
buildLattice(); //构建网络,建立结点和边之间的联系
forwardbackward(); //前向-后向算法
double s = 0.0;
for (size_t i = 0; i < x_.size(); ++i) {
for (size_t j = 0; j < ysize_; ++j) {
node_[i][j]->calcExpectation(expected, Z_, ysize_); //计算期望
}
}
//以下为梯度计算
for (size_t i = 0; i < x_.size(); ++i) {
for (const int *f = node_[i][answer_[i]]->fvector; *f != -1; ++f) {
--expected[*f + answer_[i]];
}
s += node_[i][answer_[i]]->cost; // UNIGRAM cost
const std::vector<Path *> &lpath = node_[i][answer_[i]]->lpath;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) {
if ((*it)->lnode->y == answer_[(*it)->lnode->x]) {
for (const int *f = (*it)->fvector; *f != -1; ++f) {
--expected[*f +(*it)->lnode->y * ysize_ +(*it)->rnode->y];
}
s += (*it)->cost; // BIGRAM COST
break;
}
}
}
viterbi(); // call for eval() 维特比算法
return Z_ - s ;
}主要分5部分:构建图、前向-后向算法、期望计算、梯度计算、维特比算法。
2.1 构建图
构建图如《条件随机场(2)——概率计算》中的:
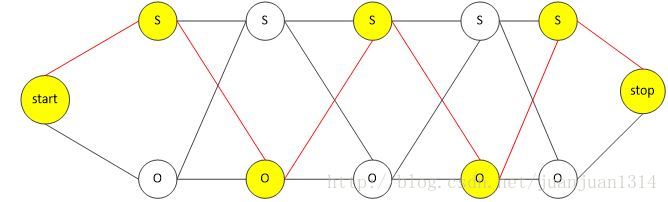
需要将从start到stop之间各位置下Y的各种取值(node)通过边(path)连接起来。个人感觉这种以图为表示方法会使后面表示各种情况(路径)下的概率和期望更直观。
node的数据结构如下:
struct Path {
Node *rnode; //右结点,i+1
Node *lnode; //左结点,i-1
const int *fvector; //对应的特征向量
double cost; //代价值
Path() : rnode(0), lnode(0), fvector(0), cost(0.0) {}
// for CRF
void calcExpectation(double *expected, double, size_t) const;
void add(Node *_lnode, Node *_rnode) ;
void clear() {
rnode = lnode = 0;
fvector = 0;
cost = 0.0;
}
};构建图主要通过调用feature_index_->rebuildFeatures(this)构建每个位置所有结点和边。然后计算每个结点的损失以及每个结点的左path集合的损失。(具体code在tagger.cpp下的void TaggerImpl::buildLattice()中)
2.2前向-后向算法
前后向算法很简单,程序如下:
void TaggerImpl::forwardbackward() {
if (x_.empty()) {
return;
}
for (int i = 0; i < static_cast<int>(x_.size()); ++i) {
for (size_t j = 0; j < ysize_; ++j) {
node_[i][j]->calcAlpha(); //从0到n+1递推计算每个node的alpha
}
}
for (int i = static_cast<int>(x_.size() - 1); i >= 0; --i) {
for (size_t j = 0; j < ysize_; ++j) {
node_[i][j]->calcBeta(); //从n到1递推计算每个node的beta。
}
}
Z_ = 0.0;
for (size_t j = 0; j < ysize_; ++j) {
Z_ = logsumexp(Z_, node_[0][j]->beta, j == 0); //计算规范化因子Z。
}
return;
}具体计算公式前面已经总结过了,不赘述了。
23期望计算
代码如下:
/********
*expected 存储梯度的向量,初始值就是期望,因此,这里也是期望的存储。
*Z:规范化因子
*size:y的取值数量。
*/
void Node::calcExpectation(double *expected, double Z, size_t size) const {
const double c = std::exp(alpha + beta - cost - Z); //计算每个节点的概率
for (const int *f = fvector; *f != -1; ++f) {
expected[*f + y] += c; //按照理论,条件满足,特征值为1,那么p*1=p,所以c相加就是特征加权和。
}
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) {
(*it)->calcExpectation(expected, Z, size); //递归计算,算每条边的概率和,作为期望。
}
}计算公式之前也已经总结过了。
2.4梯度计算
理论是这样的!
梯度计算是为优化做准备,这里总结一下梯度计算和优化算法。
《统计学习方法》中讲到的CRF的学习方法有两种:改进的迭代尺度法、拟牛顿法。
改进的迭代尺度法中,对数似然函数为
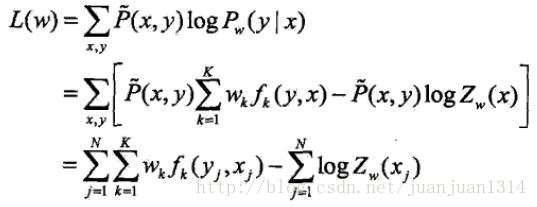
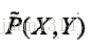
改进的迭代尺度法是最大熵模型学习的最优化算法,CRF的概率模型和最大熵算法很相似。
假设模型当前的参数向量为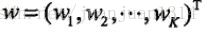
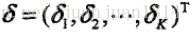
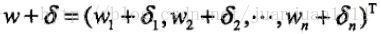
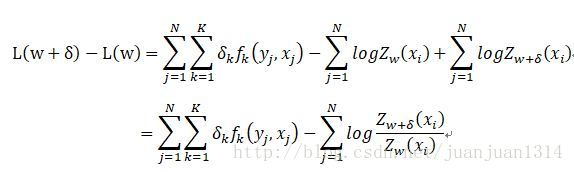
利用不等式
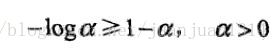
建立对数似然函数改进变量的下界:
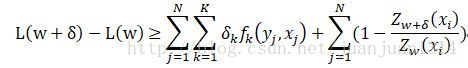
针对似然函数的下界做优化,当下界极大时,对数似然函数的值也更大。因此,取等式由端对于梯度的偏导,当偏导为0时,对数似然函数的下界极大,得到
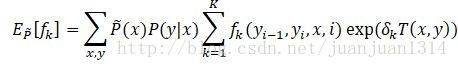
其中
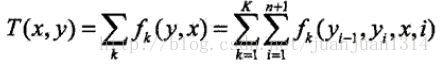
当k=1,2,…,
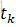
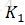
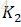
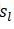
代码是这样的!!
//以下为梯度计算
for (size_t i = 0; i < x_.size(); ++i) {
for (const int *f = node_[i][answer_[i]]->fvector; *f != -1; ++f) { //answer应该是每个结点预测到的结果y_
--expected[*f + answer_[i]]; //每个node的原始梯度为整个网络的期望。当特征向量中,每维特征不为-1说明特征匹配成功,梯度自减.
}
s += node_[i][answer_[i]]->cost; // UNIGRAM cost
const std::vector<Path *> &lpath = node_[i][answer_[i]]->lpath;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) { //沿着边,将与真实y匹配成功的结点的特征对应的边再匹配一次,满足条件的,梯度再自建。
if ((*it)->lnode->y == answer_[(*it)->lnode->x]) {
for (const int *f = (*it)->fvector; *f != -1; ++f) {
--expected[*f +(*it)->lnode->y * ysize_ +(*it)->rnode->y];
}
s += (*it)->cost; // BIGRAM COST
break;
}
}
}是不是觉得程序和理论不一致呢?确实有点不一样,可能是程序采用的是松弛特征把。
2.5维特比算法
这块还没有细看,留着后面看吧。代码如下
void TaggerImpl::viterbi() {
for (size_t i = 0; i < x_.size(); ++i) {
for (size_t j = 0; j < ysize_; ++j) {
double bestc = -1e37;
Node *best = 0;
const std::vector<Path *> &lpath = node_[i][j]->lpath;
for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it) {
double cost = (*it)->lnode->bestCost +(*it)->cost +
node_[i][j]->cost; //损失应该是负数。
if (cost > bestc) { //找该位置下,损失的绝对值最小的点和到此位置前面最优的路径。
bestc = cost;
best = (*it)->lnode;
}
}
node_[i][j]->prev = best; //将最优的左结点作为当前结点的左结点。
node_[i][j]->bestCost = best ? bestc : node_[i][j]->cost; //将最小损失赋给当前结点作为该node的bestcode,以便后面的node回推最优cost和最优路径用。
}
}
double bestc = -1e37;
Node *best = 0;
size_t s = x_.size()-1;
for (size_t j = 0; j < ysize_; ++j) {
if (bestc < node_[s][j]->bestCost) {
best = node_[s][j];
bestc = node_[s][j]->bestCost;
}
}
for (Node *n = best; n; n = n->prev) {
result_[n->x] = n->y; //最优路径存储。
}
cost_ = -node_[x_.size()-1][result_[x_.size()-1]]->bestCost;
}
2.5优化算法
程序里面的优化是通过调用lbfgs.optimize()函数,该函数由调用了实际工作的lbfgs_optimize()完成的,lbfgs_optimize()用了LBFG优化算法,对这个算法完全不了解,暂时不胡说。
void LBFGS::lbfgs_optimize(int size,
int msize,
double *x,
double f,
const double *g,
double *diag,
double *w,
bool orthant,
double C,
double *v,
double *xi,
int *iflag) {3.预测算法
维特比算法大致的意思是求出位置i各个取值概率最大的取值,同时记录下非规范化概率最大的路径,依次往后推,直到推导n,那么最优路径就计算出来了。(没有系统的看过这个函数,这里是根据程序正儿八经胡说的。)
据说预测主要是通过如下接口完成
bool TaggerImpl::parse() {
CHECK_FALSE(feature_index_->buildFeatures(this))
<< feature_index_->what(); //构建特征
if (x_.empty()) {
return true;
}
buildLattice(); //构建图
if (nbest_ || vlevel_ >= 1) {
forwardbackward(); //前向-后向算法
}
viterbi(); //维特比计算最优路径
if (nbest_) {
initNbest();
}
return true;
}4.总结
终于大致了解使用CRF的过程了,接下来就是实战了。














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









