







Knowledge Distillation 概述
研究背景
对于机器学习的模型,我们往往在训练和部署时使用着极其相似的模型,尽管这两个阶段明显有着不同的需求:训练时可以使用一个巨大的数据集去训练一个很深的模型,并占用大量的计算资源,以期达到最好的效果;然而在实际应用时,却又对计算时间和计算资源特别敏感。

Knowledge Distillation采用teacher-student的模式可以帮助解决这个问题。
定义(知识蒸馏是什么?)
关于知识蒸馏,就是用大的teacher model去学习一些hard label(比如one-shot label),得到一些prediction作为soft target,相当于将知识蒸馏出来,再用一个小的student model去学习这个soft target。student相比于teacher,有可能精度更高,模型更轻,可谓青出于蓝而胜于蓝。
知乎上这个总结也不错:
开山之作
至于why work?student为什么可以比teacher更有优势?
我们需要研究下Hinton2015年的开山之作Distilling the Knowledge in a Neural Network
该论文详细地分析了背后的理论。
1. Introduction
所谓知识蒸馏,我们希望的是把比较重的teacher net的知识迁移到更轻的StudentNet上。我们一般定义的knowledge即是学习到的参数,但是将一个模型学到的参数迁移到另一个网络上,来保证knowledge是非常困难的。
Hinton从一个更抽象的角度来看待knowledge,把它定义成输入到输出向量的一个映射关系。区别于GT的one-shot形式,这种hard label。Hinton认为输出的软分布形式的所有类别概率向量,包含更多的knowledge。
毕竟,即便是预测错误了,不同类别之间的概率还是有很大的差距。比如,宝马有很小的的概率被误认为垃圾车,但这种概率也比被认成胡萝卜要大得多:

如果用另一个student网络来学习teacher预测出的软分布,要比直接学习hard label更有效、更容易,因为这里面包含了teacher总结出来的一些knowledge
另外,学习teacher输出的soft target可以获得很好的泛化性能。通常来说,一些比较重的网络在大数据集上训练出的模型泛化性能更好,通过学习teacher输出的软分布,较小的student net可以获得与其一样好的泛化性能。这也是knowledge的价值所在。

soft target有着更高的熵,更小的梯度变化,因此student相比teacher可以使用更少的数据和更大的学习率(意味着收敛很快,这部分多出来的训练时间不是问题)

同时使用original训练集和teacher net生成的transfer set,通过参数来权衡对两者的学习,可以取得更好的效果:

2. Distillation
在蒸馏时,需要使用一个新的softmax来改善soft target distribution,因为输出的prediction在某些类别的概率值特别小,甚至非常接近0。下面的这个新的softmax多了一个参数T,即temperature。T越大产生的预测分布越soft,也就是类别间的概率输出值差距被拉近了,这点在数学上很容易验证。
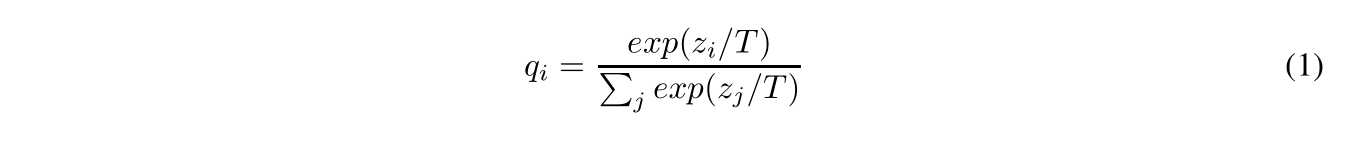
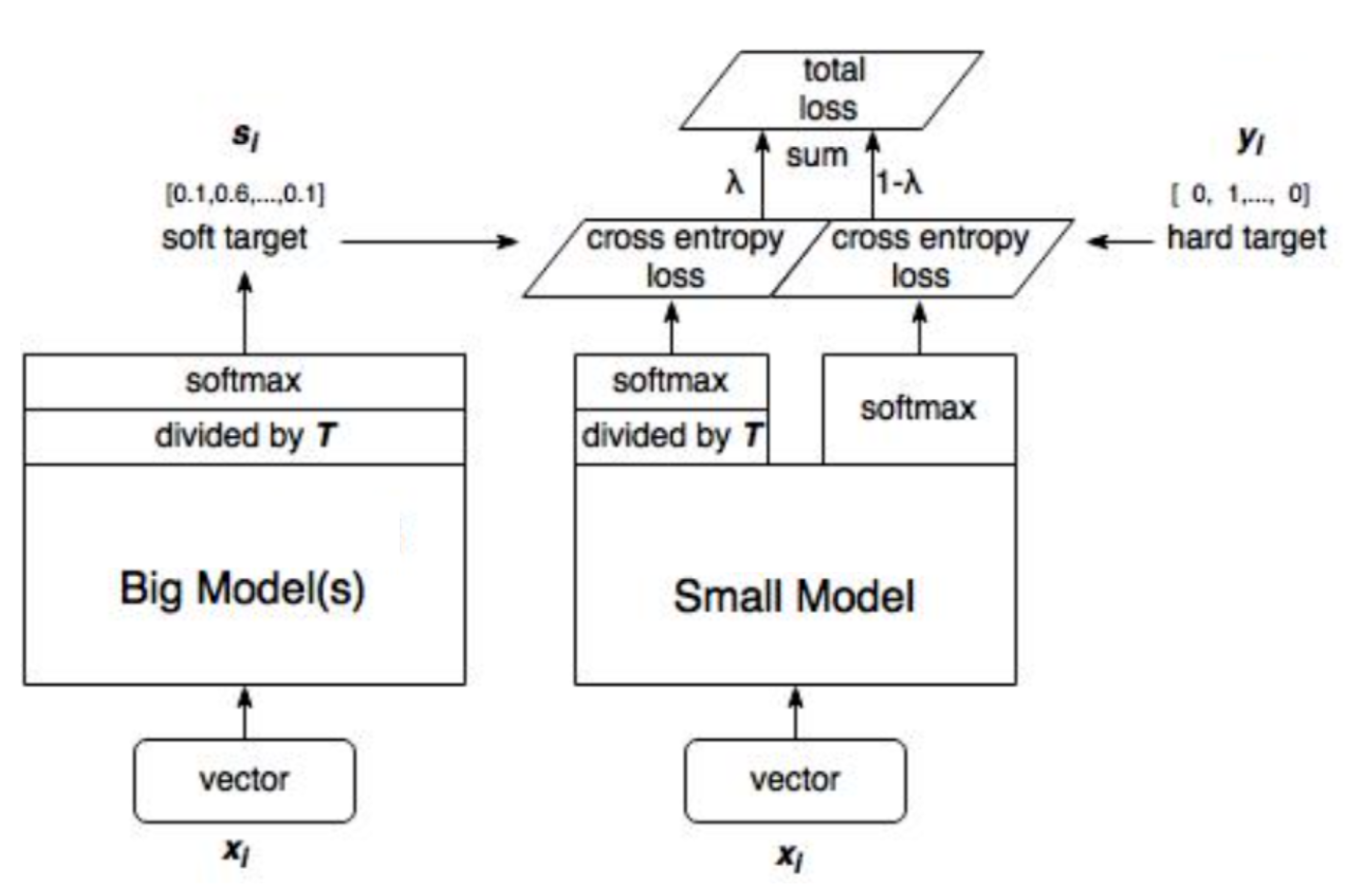
在蒸馏的过程中,Hinton提出了几种可行的方式:
- 最简单的一种方式是使用teacher生成的软分布transfer data,来训练一个student。teacher&student都是使用T(mnist训练中设为20)参数一致的softmax来训练,并且在student训练完后,又将T置为1做inference.
- 第二种方式是同时使用soft/hard target 进行监督,即
L
=
λ
∗
L
s
+
(
1
−
λ
)
∗
L
h
L=\lambda*L_s + (1-\lambda)*L_h
L=λ∗Ls+(1−λ)∗Lh。其中,二者均用cross entropy计算loss,hard项loss计算时,T设为1。对于超参
λ
\lambda
λ,Hinton的经验是hard correct labels的权重给的低一点。另外注意一点,反向传播时,soft项梯度会多出一个
1
/
T
2
1/T^2
1/T2,因而需要乘上一个
T
2
T^2
T2来保持平衡。
3. Preliminary experiments on MNIST
Hinton构建了两层,1200个神经元的model作为teacher,训练60000个minist数据,测试集上出现了67个错误;一个更小的800个神经元的model学习这些数据出现了146个错误。而相同配置的一个student模型,加入了对soft target的学习,仅出现了74个错误。
这证明了soft target可以将knowledge迁移到student model上,并且对其他数据也有很好的泛化能力!
其他论文
之后的knowledge distillation系列博客,总结自2019最新论文Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher的Related works,以及awesome-knowledge-distillation 、 knowledge-distillation-papers
(入门一个新的领域,我喜欢先看开山之作,再看最新论文的Related works了解其发展历程再针对性的挑论文阅读)
依照teacher assistant这篇论文的related work我对整个领域进行了一些分类和总结
主要是redefine Knowledge,change learning mode,some applications in some fields
详见后续系列博客。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









