






第一部分:
这个教程使用的是python进行编写的。大部分代码运行在ipython上面,如果是项目则运行在pycharm的IDE环境下。
那么先进性一些python的入门,这些都是在后面的分析中使用。
1.可变和不可变:
1)大部分的python对象是可变的(mutable)的,e.g.列表、字典、自定义的类
2)字符串和元组是不可变的(immutable)。
2.range和xrange
xrange比range效率高,但是xrange不会预先生成列表,而是一个迭代器。
3.元组tuple
一维、定长、不可变的对象序列、创建元组()、转换为元组
4.列表list
变长、可变、创建列表、转换为列表、添加移除元素,append,insert,pop,remove、合并列表+,extend
排序操作 sort(就地排序,无需创建新对象)、切片操作[start_idx:stop_idx:step]
5.常用列表函数
enumerate,for循环时记录索引,逐个返回元组(i,item)
reversed逆序迭代,可配合list返回逆序列表
zip "压缩"将多个序列的对应位置的元素组成元组
zip(*元组列表) "解压缩",zip的逆操作
6.字典
字典dict
{key1:value,key2:value2}
创建字典,插入元素,dict_variable[new_key] = new_value,获取keys(),values()
7.python的高级特性
列表推导式 :[exp for item in collection if condition]
字典推导式:{key_exp : value_exp for item in collection if condition}
集合推导式:{exp for item in collection if condition}
8.其他特性
匿名函数lamba
生成器 generator
9.高阶函数
map/reduce:
map(func,lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表返回
reduce(func(x,y),lst)
filter(func,lst),将func作用于lst的每个元素,然后根据返回值是true或者false判断是保留还是丢弃该元素。
第二部分:
numpy:
高性能科学计算和数据分析的基础包
ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
矩阵运算,无需循环,可完成类似Matlab中的矢量运算
线性代数、随机数生成
import numpy as np
ndarray:
N维数组对象(矩阵)
所有元素必须是相同类型
ndim属性,维度个数
shape属性,各维度大小
dtype属性,数据类型
创建ndarray:
np.array(collection),collection为序列型对象(list),嵌套序列 (list of list)
np.zeros, np.ones,np.empty 指定大小的全0或全1数组
注意:第一个参数是元组,用来指定大小,如(3,4)
import numpy as np
# 生成指定维度的随机多维数据
data = np.random.rand(2, 3)
print data
print type(data)empty不是总是返回全0,有时返回的是未初始的随机值
# 嵌套序列转换为ndarray
l2 = [range(10), range(10)]
data = np.array(l2)
print data
print data.shapenp.arange()类似range() 注意是arange,不是英文arrange
# 多维数组
arr2 = np.arange(12).reshape(3,4)
print arr2
矢量运算,相同大小的数组键间的运算应用在元素上
矢量和标量运算,“广播”— 将标量“广播”到各个元素
# 矢量与矢量运算
arr = np.array([[1, 2, 3],
[4, 5, 6]])
print "元素相乘:"
print arr * arr
print "矩阵相加:"
print arr + arr索引与切片 (续)
多维数组的索引
arr[r1:r2, c1:c2]
arr[1,1] 等价 arr[1][1]
[:] 代表某个维度的数据
data_arr = np.random.rand(3,3)
print data_arr
year_arr = np.array([[2000, 2001, 2000],
[2005, 2002, 2009],
[2001, 2003, 2010]])
filtered_arr = data_arr[year_arr >= 2005]
print filtered_arr# 多个条件
filtered_arr = data_arr[(year_arr <= 2005) & (year_arr % 2 == 0)]
print filtered_arr条件索引
布尔值多维数组 arr[condition] condition可以是多个条件组合
注意,多个条件组合要使用 & |,而不是and or
维数转换
转置 transpose
高维数组转置要指定维度编号 (0,1,2,…)
常用的通用函数
• ceil, 向上最接近的整数
• floor, 向下最接近的整数
• rint, 四舍五入
• isnan, 判断元素是否为 NaN(Not a Number)
• multiply,元素相乘
• divide, 元素相除
np.where
• 矢量版本的三元表达式 x if condition else y
• np.where(condition, x, y)
arr = np.random.randn(3,4)
print arr
np.where(arr > 0, 1, -1)常用的统计方法
• np.mean, np.sum,
• np.max, np.min
• np.std, np.var
• np.argmax, np.argmin
• np.cumsum, np.cumprod
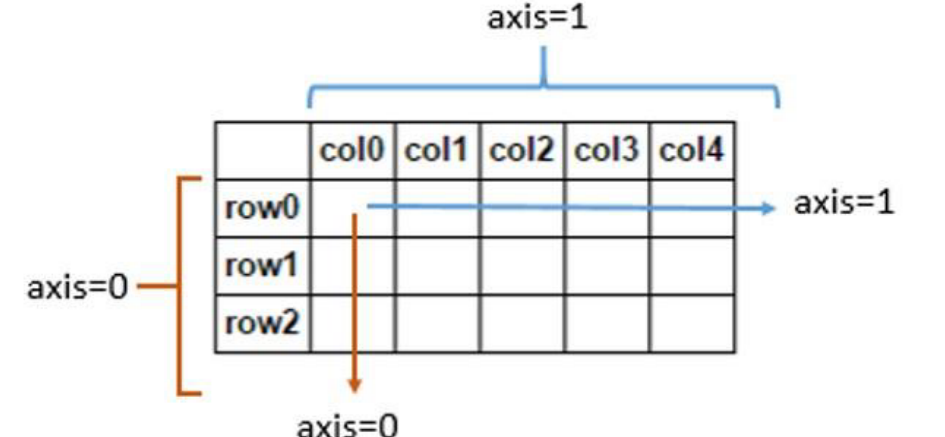
arr = np.arange(10).reshape(5,2)
print arr
print np.sum(arr)
print np.sum(arr, axis=0)
print np.sum(arr, axis=1)np.all和np.any
• all,全部满足条件
• any,至少有一个元素满足条件
np.unique
• 找到唯一值并返回排序结果
相关的matplotlib内容看前面的blog
项目一:美国大选数据分析
# -*- coding: utf-8 -*-
# 引入必要的库
import numpy as np
import datetime
import matplotlib.pyplot as plt
# 数据文件地址
filename = './presidential_polls.csv'
# 读取列名,即第一行数据
with open(filename, 'r') as f:
col_names_str = f.readline()[:-1] # [:-1]表示不读取末尾的换行符'\n'
# 将字符串拆分,并组成列表
col_name_lst = col_names_str.split(',')
# 使用的列名
use_col_name_lst = ['enddate', 'rawpoll_clinton', 'rawpoll_trump','adjpoll_clinton', 'adjpoll_trump']
# 获取相应列名的索引号
use_col_index_lst = [col_name_lst.index(use_col_name) for use_col_name in use_col_name_lst]
data_array = np.loadtxt(filename, # 文件名
delimiter=',', # 分隔符
skiprows=1, # 跳过第一行,即跳过列名
dtype=str, # 数据类型
usecols=use_col_index_lst) # 指定读取的列索引号
print data_array, data_array.shape
# 处理日期格式数据
enddate_idx = use_col_name_lst.index('enddate')
enddate_lst = data_array[:,enddate_idx].tolist()
# 将日期字符串格式统一,即'yy/dd/mm'
enddate_lst = [enddate.replace('-', '/') for enddate in enddate_lst]
# 将日期字符串转换成日期
date_lst = [datetime.datetime.strptime(enddate, '%m/%d/%Y') for enddate in enddate_lst]
# 构造年份-月份列表
month_lst = ['%d-%02d' %(date_obj.year, date_obj.month) for date_obj in date_lst]
print month_lst
month_array = np.array(month_lst)
months = np.unique(month_array)
print months
# 统计民意投票数
# cliton
# 原始数据 rawpoll
rawpoll_clinton_idx = use_col_name_lst.index('rawpoll_clinton')
rawpoll_clinton_data = data_array[:, rawpoll_clinton_idx]
# 调整后的数据 adhpool
adjpoll_clinton_idx = use_col_name_lst.index('adjpoll_clinton')
adjpoll_clinton_data = data_array[:, adjpoll_clinton_idx]
# trump
# 原始数据 rawpoll
rawpoll_trump_idx = use_col_name_lst.index('rawpoll_trump')
rawpoll_trump_data = data_array[:, rawpoll_trump_idx]
# 调整后的数据 adjpoll
adjpoll_trump_idx = use_col_name_lst.index('adjpoll_trump')
adjpoll_trump_data = data_array[:, adjpoll_trump_idx]
# 结果保存
results = []
def is_convert_float(s):
"""
判断一个字符串能否转换为float
"""
try:
float(s)
except:
return False
return True
def get_sum(str_array):
"""
返回字符串数组中数字的总和
"""
# 去掉不能转换成数字的数据
cleaned_data = filter(is_convert_float, str_array)
# 转换数据类型
float_array = np.array(cleaned_data, np.float)
return np.sum(float_array)
for month in months:
# clinton
# 原始数据 rawpoll
rawpoll_clinton_month_data = rawpoll_clinton_data[month_array == month]
# 统计当月的总票数
rawpoll_clinton_month_sum = get_sum(rawpoll_clinton_month_data)
# 调整数据 adjpoll
adjpoll_clinton_month_data = adjpoll_clinton_data[month_array == month]
# 统计当月的总票数
adjpoll_clinton_month_sum = get_sum(adjpoll_clinton_month_data)
# trump
# 原始数据 rawpoll
rawpoll_trump_month_data = rawpoll_trump_data[month_array == month]
# 统计当月的总票数
rawpoll_trump_month_sum = get_sum(rawpoll_trump_month_data)
# 调整数据 adjpoll
adjpoll_trump_month_data = adjpoll_trump_data[month_array == month]
# 统计当月的总票数
adjpoll_trump_month_sum = get_sum(adjpoll_trump_month_data)
results.append((month, rawpoll_clinton_month_sum, adjpoll_clinton_month_sum, rawpoll_trump_month_sum, adjpoll_trump_month_sum))
print results
months, raw_cliton_sum, adj_cliton_sum, raw_trump_sum, adj_trump_sum = zip(*results)
fig, subplot_arr = plt.subplots(2,2, figsize=(15,10))
# 原始数据趋势展示
subplot_arr[0,0].plot(raw_cliton_sum, color='r')
subplot_arr[0,0].plot(raw_trump_sum, color='g')
width = 0.25
x = np.arange(len(months))
subplot_arr[0,1].bar(x, raw_cliton_sum, width, color='r')
subplot_arr[0,1].bar(x + width, raw_trump_sum, width, color='g')
subplot_arr[0,1].set_xticks(x + width)
subplot_arr[0,1].set_xticklabels(months, rotation='vertical')
# 调整数据趋势展示
subplot_arr[1,0].plot(adj_cliton_sum, color='r')
subplot_arr[1,0].plot(adj_trump_sum, color='g')
width = 0.25
x = np.arange(len(months))
subplot_arr[1,1].bar(x, adj_cliton_sum, width, color='r')
subplot_arr[1,1].bar(x + width, adj_trump_sum, width, color='g')
subplot_arr[1,1].set_xticks(x + width)
subplot_arr[1,1].set_xticklabels(months, rotation='vertical')
plt.subplots_adjust(wspace=0.2)
plt.show()数据分析的可视化:
















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









