






1.Market-Basket Model
-basket: small subset of items
-find the tends(who bought X will also bought Y)
-两种事件之间多对多映射
2.相关概念
1).支持度:包含有项目集I的集合条数(如果给定支持度阈值s,支持度>s才属于频繁集
2).自信度:给定项集I出现j的概率
conf(I->j)=support(I ∪ j)/support(I)
<font size=4>3)兴趣度(Interest):[比如conf(I->milk)值较高,因为milk可能不依赖于X]
Interest(I->j)=conf(I->j)-Pr[j]</font>
----频繁集:support和confidence值较高
3.关联规则挖掘
1)找到频繁集I
2)产生规则:对于I中每一个子集A,A->I除A剩余部分并计算自信度
3)若A,B->C,D大于自信度,则A,B,C->D同样大于。
4)产生超过自信度阈值的关联规则
4.找到频繁项目集算法:
--->frequent pair较之triple较多,要么使用矩阵纪录所有pair,要么使用table纪录三元组[i,j,k]纪录[i,j]出现次数
但由于内存不够的问题,产生了其他的算法
1)A-priori
如果项目集I出现了至少s次,那么其子集同样出现至少s次。
step1:读取每个篮子,并纪录每个独立item出现的次数。
step2:读取每个篮子,但是只统计元素双方都是频繁的(即出现次数超过阈值)
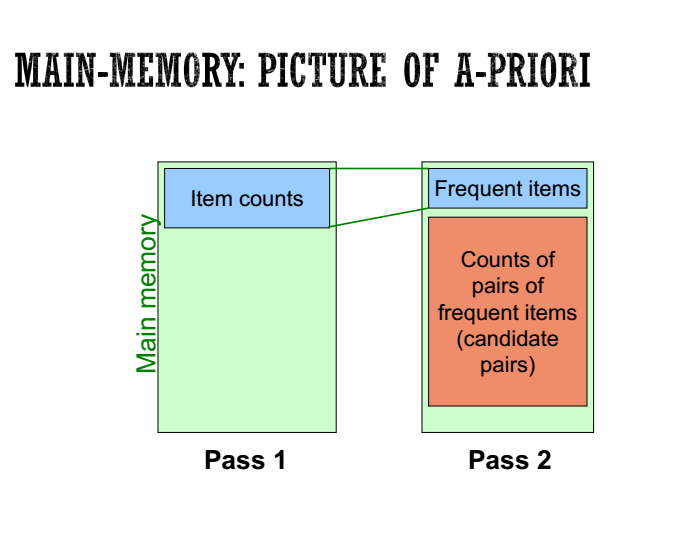
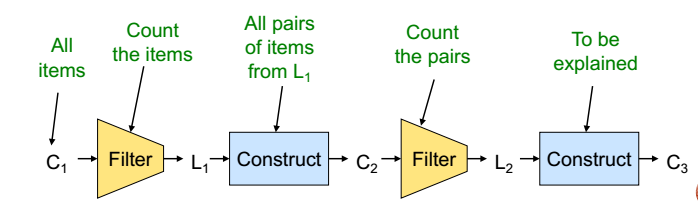
step3:此处有两种说法,其一为对于size=k的候选频繁集,基于size=k-1的候选频繁集和L1中的频繁项组成,再对其中的候选频繁集进行计数和删选
但另一种说法为:对于size=k的候选频繁集满足的条件是:其size=k-1的子集需被包含于L(k-1)【个人支持后者,减少Ck的大小】
-----另外由于step1仅记录了item的出现次数,大部分memory空闲,诞生了pcy algorithm
2)pcy algorithm
step1:伪代码如下

【如果被哈希后的桶计数小于阈值s,那么被哈希到该桶的pair出现次数也必然小于s,必然不是frequent;相反,对于次数>s的桶,被哈希到该桶内的pair也不一定是frequent】
step2:只纪录被哈希到频繁桶的pair出现的次数

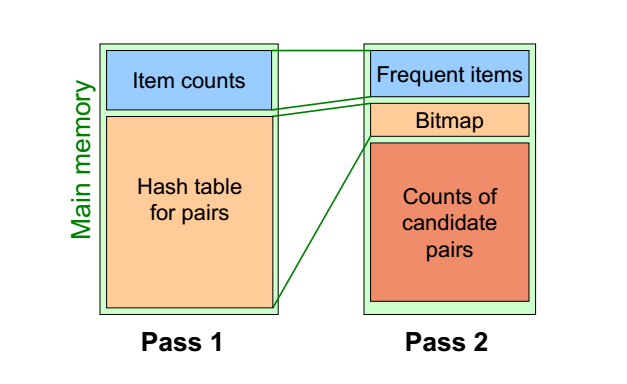
【note:由于bitmap只纪录了哈希到的桶是否频繁,哈希作为单向散列算法,不知道桶内有哪些pair】
(3)Multistage algorithm
主要想法:经过pcy的里第一轮哈希,对于那些频繁桶的pair进行第二次哈希


【note】个人理解是,对于pass1中的pair,经历了pass2后我们只知道bitmap映射到的桶是否频繁,我们必须提取一个{i,j}才知道它是否存在于某个频繁桶内。一旦了解到存在于频繁桶后,我们再对此做hash2到另一批桶内。但最后,对于每一个{i,j},提取之后,会出现第二张slide 2里面的情况,因为我们并不知道第二轮hash过后桶内的pair有哪些。
(4)multihash algorithm
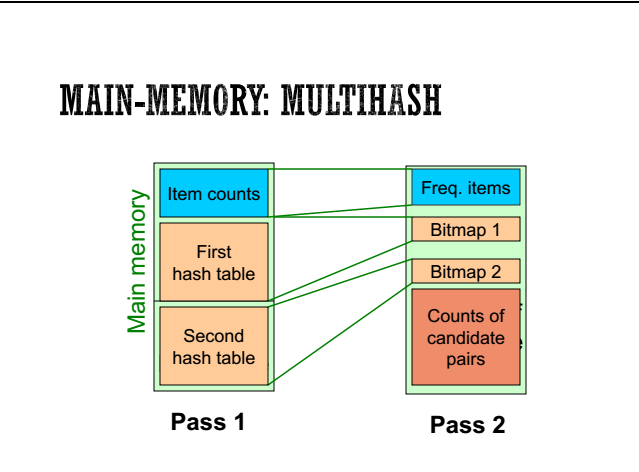
【note】和multistage 其实比较类似,比multistage 少一个pass,在pass1里面充分利用内存















 3856
3856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









