






Java编程操作Mapreduce
前言
本文写于2024年6月3日
其中使用的技术以及软件可能会在未来某个时刻失效,本文主要用于个人学习,请后来者在批判实践的基础上审视本文。
同时,本文这里就不进行错误复现与解决办法,网上有很多答疑的帖子
环境:
VMware® Workstation 16 Pro
MobaXterm_Portable_v12.4
CenterOS7 64
Windows10
Mapreduce的介绍
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
“分而治之”是MapReduce的核心思想,它表示把一个大规模的数据集切分成很多小的单独的数据集,然后放在多个机器上同时处理
Mapreduce的配置
创建一个新maven项目
在maven的pom.xml文件中添加依赖项,重新构建maven项目
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
以下的内容基本上是类方法的调用,直接展示源代码
创建Mapper类
package maperuduce.workcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* LongWritable:代表map函数的输入kv键值对的key类型,值为每行文本的偏移量
* 第一个Text:代表map函数的输入kv键值对的value类型,值为每行文本
*
* 第二个Text:代表map函数的输出kv键值对的key类型,代表每个单词
* IntWritable:代表map函数的输出kv键值对的value类型,代表每个单词出现次数(1次)
*/
public class workCountMapper extends Mapper<LongWritable,Text,Text, IntWritable>{
//新建Text对象,该对象作为map节点输出kv键值对中的key
Text keyOut=new Text();
//新建IntWritable对象,该对象作为map阶段输出的kv键值对的value
IntWritable valueOut=new IntWritable(1);
//map函数的具体逻辑代码在重写的map()
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//获取一行文本
String line =value.toString();
//根据单词间的分隔符对应单词进行拆分
String[] words= line.split(" ");
//对数组进行遍历
for (String word:words){
//对kv中的key进行赋值
keyOut.set(word);
//map阶段处理完成,进行kv键值对的输出
context.write(keyOut,valueOut);
}
}
}
创建reduce类
package maperuduce.workcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 第一个Text:reduce阶段输入的kv键值对的key,实际上也是map阶段输出的kv键值对中的key,值为单词
* 第一个IntWritable:reduce阶段输入的kv键值对的value,实际上也是map阶段输出的kv键值对中的value,值为1
*
* 第二个Text:reduce阶段输出的kv键值对中的key,值为单词
* 第二个IntWritable:reduce阶段输出的kv键值对中的value,值为对应单词在整个文本中出现的总次数
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
//新建IntWritable对象,作为reduce阶段输出的kv键值对中的value
IntWritable valueOut=new IntWritable();
//reduce函数的具体逻辑代码在重写的reduce()中实现
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//定义单词出现的总次数
int totalCount=0;
//对出现的单词次数进行累加
for(IntWritable value:values){
//totalCount=totalCount+value.get();
totalCount+=value.get();
}
//对reduce阶段输出的value进行赋值
valueOut.set(totalCount);
//reduce阶段统计完成,将结果进行输出
context.write(key,valueOut);
}
}
创建Driver类启动Mapreduce
package maperuduce.workcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//获取配置信息对象和job对象
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
//关联Driver类
job.setJarByClass(WordCountDriver.class);
//设置mapper和reduce的类
job.setMapperClass(workCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv类型(reducer输出的kv类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置文件的输入路径和计算结果的输出路径
//要计算文件路径
Path filePath1=new Path("D:\\hadoop\\input\\words1.txt");
Path filePath2=new Path("D:\\hadoop\\input\\words2.txt");
//设置文件输入路径
FileInputFormat.setInputPaths(job,filePath1,filePath2);
//设置文件输出路径
//output的目录不应存在,mapreduce会自己创建output,如已经存在会报错
Path outputPath=new Path("D:\\hadoop\\output");
FileOutputFormat.setOutputPath(job,outputPath);
//提交任务 进行计算
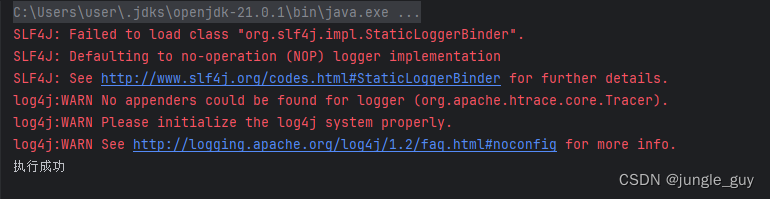
boolean result =job.waitForCompletion(true);
System.out.println(result?"执行成功":"执行不成功");
}
}
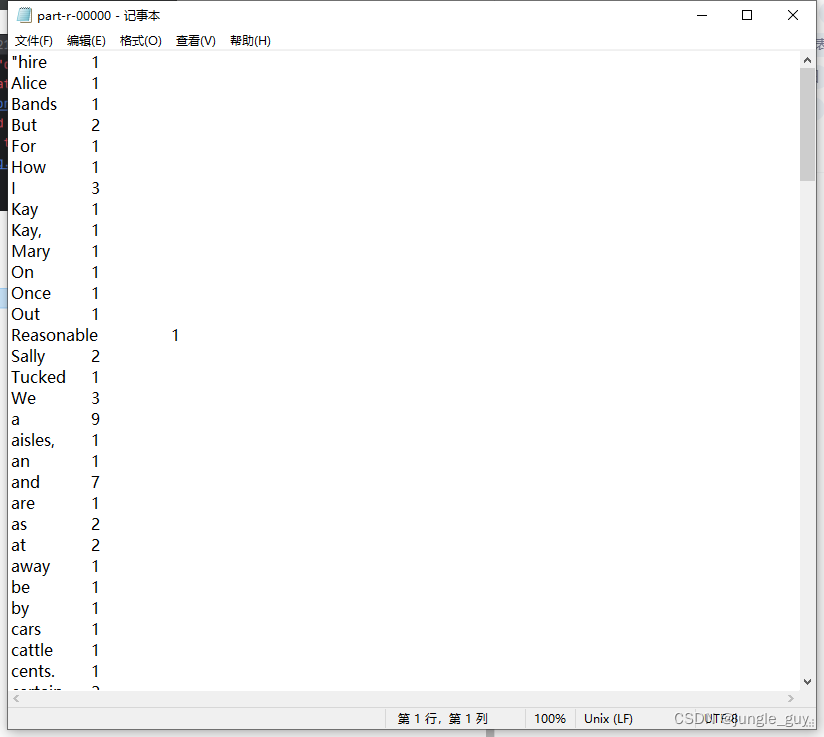
运行成功
















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









