






将编写好的mapreduce类导入HDFS上运行
前言
本文写于2024年6月4日
其中使用的技术以及软件可能会在未来某个时刻失效,本文主要用于个人学习,请后来者在批判实践的基础上审视本文。
同时,本文这里就不进行错误复现与解决办法,网上有很多答疑的帖子
环境:
VMware® Workstation 16 Pro
MobaXterm_Portable_v12.4
CenterOS7 64
Windows10
本节内容将演示,如何将上一节编写好的mapreduce类上传Hadoop并运行
将mapreduce类打包上传
要想将自己的代码打包到别处使用,最方便的办法就是将自己的代码打包为jar包
这里我们使用maven的插件完成
在maven的pom.xml中导入以下,重构maven项目
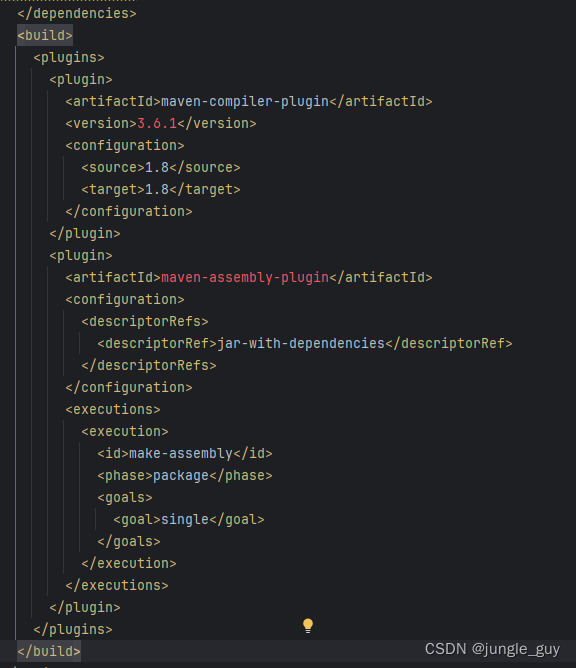
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
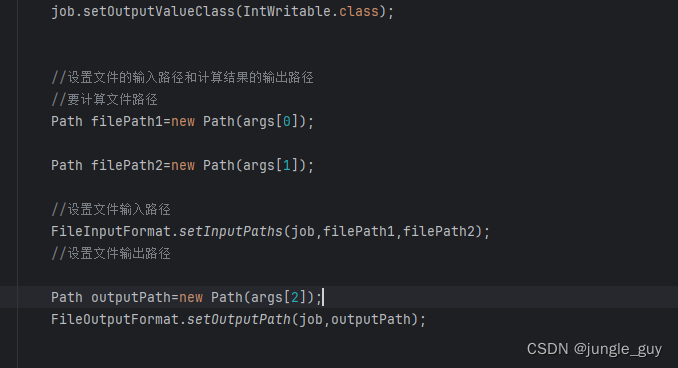
在上一节我们的目标路径是写死的,如果直接打包进Hadoop,肯定会因为找不到路径保持,所以我们这里将路径作为main函数的参数传入

然后在设置输出路径时把路径作为参数传入即可
使用maven
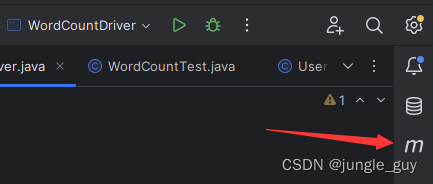
点击assembly:assembly开始将你的文件打成jar包,要注意在打jar包之前,要将你原有的编译后项目生成文件target删掉,然后重新打包生成jar包
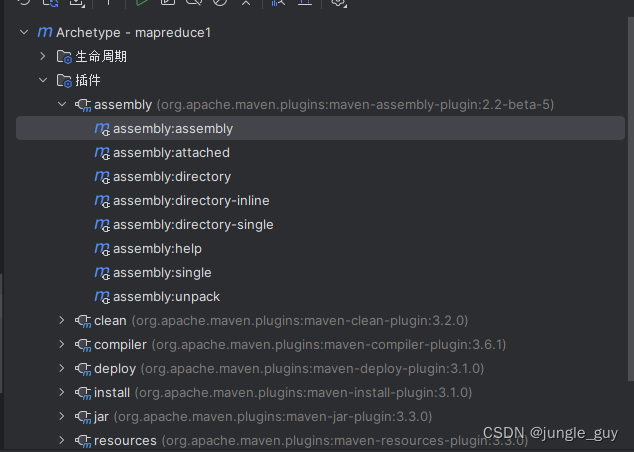
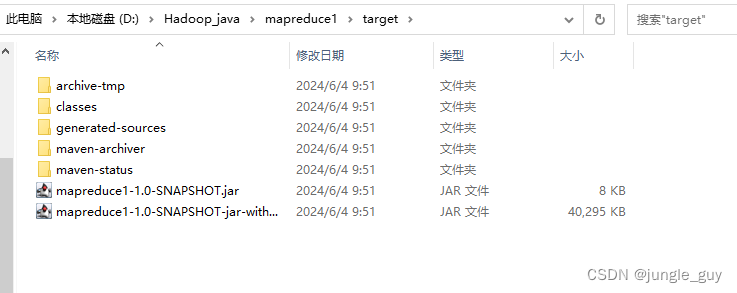
前往target文件夹下,我们就能看见生成了两个jar包,上面的是不含依赖库的,即只包含我们自己写的三个类文件,下面的是包含依赖库的,这里我们只需要下面的含依赖库的jar包
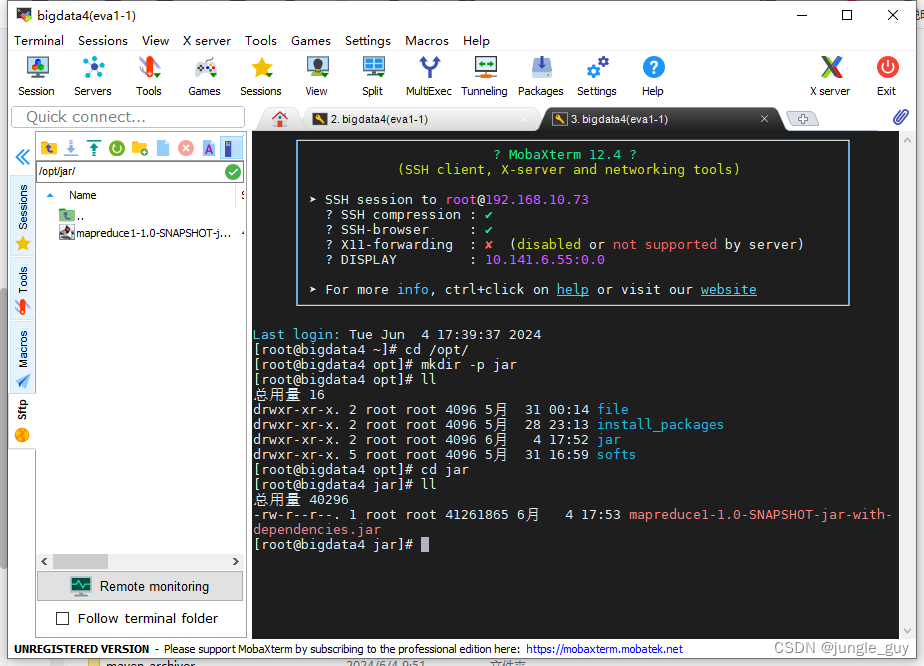
在Hadoop中运行jar包
Hadoop在进行运算时会调用三台虚拟机的资源,我只给这三台虚拟机各自分配了2G的内存,虽然我还没有完全搞清楚Hadoop的相关运行机制,但是实际运行会发生爆内存的情况,为防止运行时发生这种问题,需要进行以下配置
在mapred-site.xml中添加以下配置
<!-- 是否对容器强制执行虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for
containers</description>
</property>
<!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers</description>
</property>
在yarn-site.xml中添加以下配置
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property>
使用scp命令将设置同步到其他两台虚拟机上
scp /opt/softs/hadoop3.1.3/etc/hadoop/mapred-site.xml root@bigdata5:/opt/softs/hadoop3.1.3/etc/hadoop/
scp /opt/softs/hadoop3.1.3/etc/hadoop/mapred-site.xml root@bigdata6:/opt/softs/hadoop3.1.3/etc/hadoop/
scp /opt/softs/hadoop3.1.3/etc/hadoop/yarn-site.xml root@bigdata5:/opt/softs/hadoop3.1.3/etc/hadoop/
scp /opt/softs/hadoop3.1.3/etc/hadoop/yarn-site.xml root@bigdata6:/opt/softs/hadoop3.1.3/etc/hadoop/
重启相关的hdfs与yarn服务
在hdfs的文件管理系统中创建输入目录,并将用于输入的文件上传

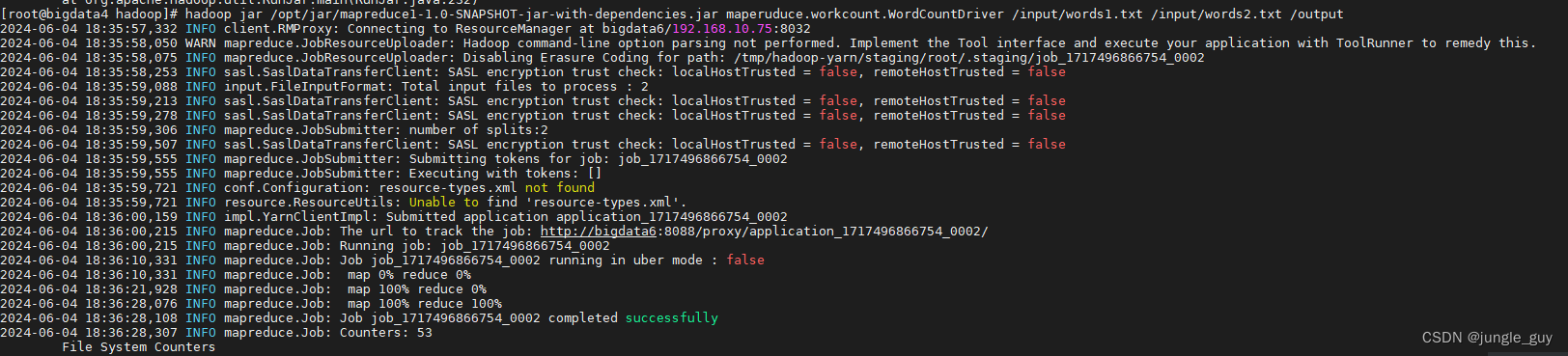
在hdfs中启动mapreduce,注意最后的三个路径是作为参数传入我们打的jar包中,就像我们在idea中运行mapreduce一样,向String[] args中添加参数
这是我们的函数入口
这是我们会使用参数的地方
所以最后三个参数需要填入hdfs上的输入输出目录
hadoop jar /opt/jar/mapreduce1-1.0-SNAPSHOT-jar-with-dependencies.jar maperuduce.workcount.WordCountDriver /input/words1.txt /input/words2.txt /output
运行成功,检查结果


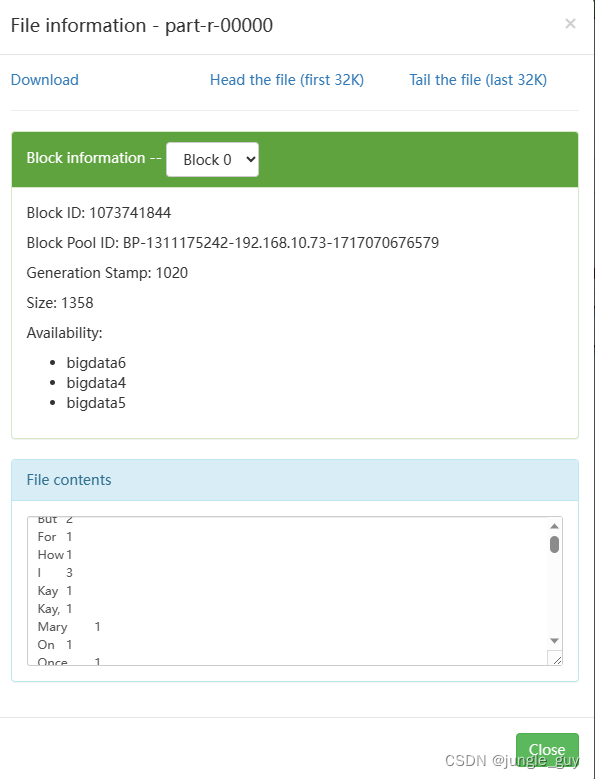
成功
自定义mapreduce类进行自定义数据类型运算
如果我们有这样的一段数据:
1,小明,男,iphone14,5999,1
2,小华,男,飞天茅台,2338,2
3,小红,女,兰蔻小黑瓶精华,1080,1
4,小魏,未知,米家走步机,1499,1
5,小华,男,长城红酒,158,10
6,小红,女,珀莱雅面膜,79,2
7,小华,男,珠江啤酒,11,3
8,小明,男,Apple Watch 8,2999,1
想要进行结算总金额像这样:
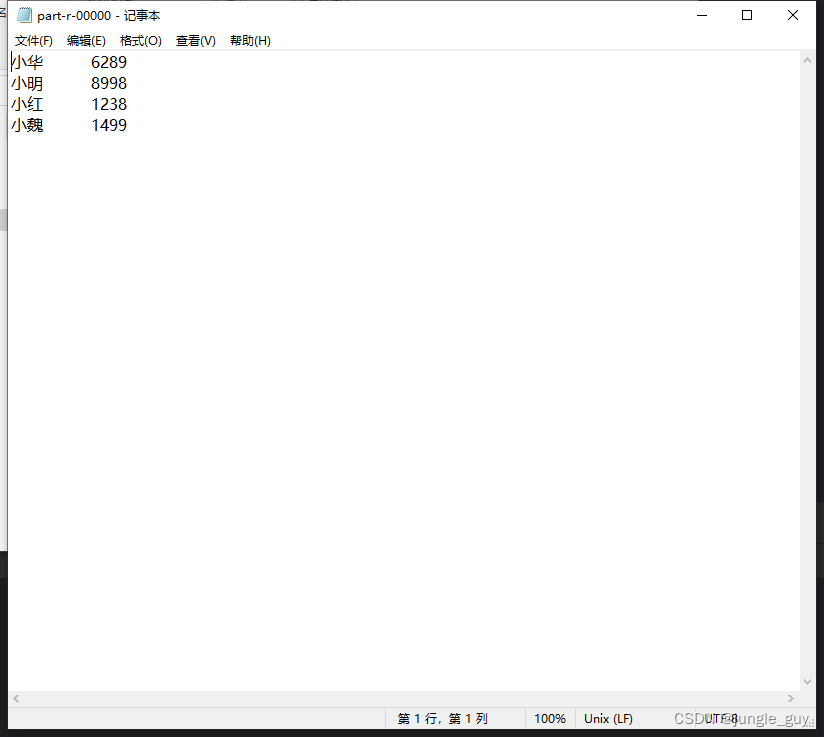
我们就需要继承一些mapreduce类,将其中的一些方法以我们自定义的方法重写
在最初的文本计数mapreduce中,我们的mapper与reducer输出类型是IntWritable是Writable的子类
Writable是Hadoop中规定的输出类,其中包含了:
void write(DataOutput var1) throws IOException;
void readFields(DataInput var1) throws IOException;
两个方法,分别是序列号与反序列化方法,没有这两个方法Hadoop没法正常读取类的数据
所以我们创建我们的自定义数据类型时,应当继承Writable,使之能够被Hadoop正常读取
用户类UserOrder源码:
其中包含了空参构造,用于之后的流程里创建空UserOrder类型对象转载数据
包含了toString()方法,toString方法决定了在reducer阶段结束后的输出文档会输出什么样的数据
重写了write与readFields方法,使数据能够正常被读取
各种set,get方法用于后续的数据操作,其中 totalPrice(总金额)有空参方法,用于直接根据saleCoun(购买数量)与price(单价)计算总价
package model;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 模型类实现Hadoop的序列号和反序列化的步骤
*
*
* 1.模型类必须实现 Writable
* 2.模型类在必须手动增加空参数构造方法
* 3.重写序列化方法write(DataOutPut out)
* 4.重写反序列化方法readFiles(DataInput in)
*/
public class UserOrder implements Writable {
//订单编号
private Integer orderId;
//用户名称
private String userName;
//用户性别
private String sex;
//订购商品名称
private String goodsName;
//商品单价
private Integer price;
//订购的商品数量
private Integer saleCount;
//订购的总价
private Integer totalPrice;
//空参数构造方法
public UserOrder(){
}
//重写序列化方法
@Override
public void write(DataOutput Out) throws IOException {
Out.writeInt(orderId);
Out.writeUTF(userName);
Out.writeUTF(sex);
Out.writeUTF(goodsName);
Out.writeInt(price);
Out.writeInt(saleCount);
Out.writeInt(totalPrice);
}
//重写反序列化方法
@Override
public void readFields(DataInput In) throws IOException {
//在反序列化时 属性的顺序需要和序列号时的顺序一样
this.orderId=In.readInt();
this.userName=In.readUTF();
this.sex=In.readUTF();
this.goodsName=In.readUTF();
this.price=In.readInt();
this.saleCount=In.readInt();
this.totalPrice=In.readInt();
}
//toString() 决定了怎样输出数据,输出什么数据,这里只输出总金额
@Override
public String toString() {
return this.totalPrice.toString();
}
public Integer getOrderId() {
return orderId;
}
public void setOrderId(Integer orderId) {
this.orderId = orderId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getGoodsName() {
return goodsName;
}
public void setGoodsName(String goodsName) {
this.goodsName = goodsName;
}
public Integer getPrice() {
return price;
}
public void setPrice(Integer price) {
this.price = price;
}
public Integer getSaleCount() {
return saleCount;
}
public void setSaleCount(Integer saleCount) {
this.saleCount = saleCount;
}
public Integer getTotalPrice() {
return totalPrice;
}
public void setTotalPrice() {
this.totalPrice=this.price*this.saleCount;
}
public void setTotalPrice(Integer data) {
this.totalPrice=data;
}
}
UserOrderMapper源码:
原理与前文的workCountMapper类似,只是将输出类型换为UserOrder,进行了更多的数据填入
package order;
import model.UserOrder;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class UserOrderMapper extends Mapper<LongWritable,Text,Text, UserOrder> {
//map阶段输出的kv中的
private Text keyOut=new Text();
//新建用户订购对象
private UserOrder valueOut = new UserOrder();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, UserOrder>.Context context) throws IOException, InterruptedException {
//获取一行数据
String line=value.toString();
//根据文本中的分隔符对数据进行拆分
String[] orderData=line.split(",");
System.out.println(orderData[1]);
//根据下标提取数据
String orderId=orderData[0];
String userName=orderData[1];
String sex=orderData[2];
String goodsName=orderData[3];
String price=orderData[4];
String saleCount=orderData[5];
//封装UserOrder对象
valueOut.setOrderId(Integer.parseInt(orderId));
valueOut.setUserName(userName);
valueOut.setSex(sex);
valueOut.setGoodsName(goodsName);
valueOut.setPrice(Integer.parseInt(price));
valueOut.setSaleCount(Integer.parseInt(saleCount));
//调用计算总价方法 赋值
valueOut.setTotalPrice();
//对输出的key进行赋值
keyOut.set(userName);
context.write(keyOut,valueOut);
}
}
UserOrderReducer源码:
原理与前文的workCountReducer类似,只是将输入输出类型换为UserOrder,进行了更多的数据填入
package order;
import model.UserOrder;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class UserOrderReducer extends Reducer<Text, UserOrder,Text,UserOrder> {
//新建UserOrder对象,作为最终输出到文件中的对象
private UserOrder valueOut=new UserOrder();
@Override
protected void reduce(Text key, Iterable<UserOrder> values, Reducer<Text, UserOrder, Text, UserOrder>.Context context) throws IOException, InterruptedException {
//定义同一个用户的最终订单总价
Integer userTotalPrice=0;
//遍历迭代器 对订单总价进行累加
for(UserOrder userOrder:values){
//获取每个订单总价
Integer totalPrice=userOrder.getTotalPrice();
userTotalPrice+=totalPrice;
System.out.println(userTotalPrice);
}
//输出对象进行赋值
valueOut.setTotalPrice(userTotalPrice);
//reduce阶段输出
context.write(key,valueOut);
}
}
UserOderDriver源码
同理,但这里我先把路径用硬编码写死了
package order;
import maperuduce.workcount.WordCountDriver;
import model.UserOrder;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class UserOderDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//获取配置信息对象和job对象
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
//关联Driver类
job.setJarByClass(UserOderDriver.class);
//设置mapper和reduce的类
job.setMapperClass(UserOrderMapper.class);
job.setReducerClass(UserOrderReducer.class);
//设置mapper输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(UserOrder.class);
//设置最终输出的kv类型(reducer输出的kv类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(UserOrder.class);
//设置文件的输入路径和计算结果的输出路径
//要计算文件路径
Path filePath1=new Path("D:\\hadoop\\input\\sale_details.txt");
//设置文件输入路径
FileInputFormat.setInputPaths(job,filePath1);
//设置文件输出路径
Path outputPath=new Path("D:\\hadoop\\output");
FileOutputFormat.setOutputPath(job,outputPath);
//提交任务 进行计算
boolean result =job.waitForCompletion(true);
System.out.println(result?"执行成功":"执行不成功");
}
}
执行,检查结果
使用Partitioner进行文件分区
如果我们想对结果进行性别分类,那么可以使用继承了Partitioner的类
首先在结果处添加性别的输出

在UserOderRudecer中向最终输出填入性别数据
boolean flag=true;
@Override
protected void reduce(Text key, Iterable<UserOrder> values, Reducer<Text, UserOrder, Text, UserOrder>.Context context) throws IOException, InterruptedException {
//定义同一个用户的最终订单总价
Integer userTotalPrice=0;
//遍历迭代器 对订单总价进行累加
for(UserOrder userOrder:values){
//获取每个订单总价
Integer totalPrice=userOrder.getTotalPrice();
userTotalPrice+=totalPrice;
System.out.println(userTotalPrice);
//给输出对象进行性别赋值
if(flag){
valueOut.setSex(userOrder.getSex());
flag=false;
}
}
//输出对象进行赋值
valueOut.setTotalPrice(userTotalPrice);
//reduce阶段输出
context.write(key,valueOut);
}
创建一个继承自Partitioner的类sexPartitioner
package order;
import model.UserOrder;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class sexPartitioner extends Partitioner<Text,UserOrder> {
@Override
public int getPartition(Text text, UserOrder userOrder, int i) {
//获取用户的性别
String sex=userOrder.getSex();
//根据性别不同 将数据划分到不同的分区
if(sex.equals("男")){
return 0;
}else if (sex.equals("女")){
return 1;
}else {
return 2;
}
}
}
在UserOderDriver中添加 sexPartitioner的区分器
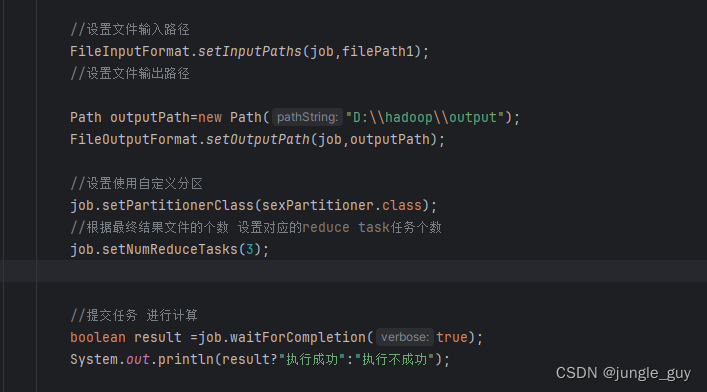
//设置使用自定义分区
job.setPartitionerClass(sexPartitioner.class);
//根据最终结果文件的个数 设置对应的reduce task任务个数
job.setNumReduceTasks(3);
运行,检查结果,成功

















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









