






截止发文,全国一共有40个城市开通了地铁,累计站点数量为5968
而我,爬完这些数据,只用了5秒
此时,正在看文章的你,是不是心里会默默的来一句:麻雀啄了牛屁股—雀食牛逼 
今天就来教大家用 Python 如何快速搞定,先给一个使用说明,源码和逻辑见后文
1、核心代码
首先是先获取所有开通地铁的城市
代码分成两部分,一部分是官方页面显示出的城市列表,一部分是未显示出来的城市列表
其中,主函数代码如下:
"""获取有地铁站点的城市名"""
df_city_list = get_city_list()
print('[ 提示 ]: 共检测到 {0} 个开通地铁的城市'.format(df_city_list.shape[0]))其次是遍历每个城市,获取对应城市的所有地铁线路
并将最终的结果进行拼接,最终生成的就是所有城市的所有地铁站点信息
df_city_data = pd.DataFrame()
for row_index, data_row in df_city_list.iterrows():
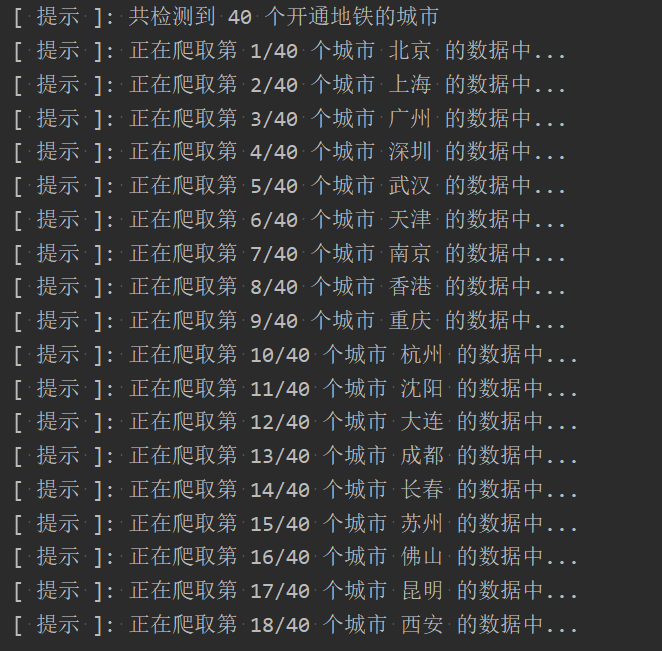
print('[ 提示 ]: 正在爬取第 {0}/{1} 个城市 {2} 的数据中...'.format(row_index + 1, df_city_list.shape[0], data_row['name_ch']))
"""遍历每个城市获取地铁站点信息"""
df_per_city = get_per_info(data_row)
df_city_data = df_city_data.append(df_per_city, ignore_index=True)程序运行图如下:
最终爬取的数据如下:
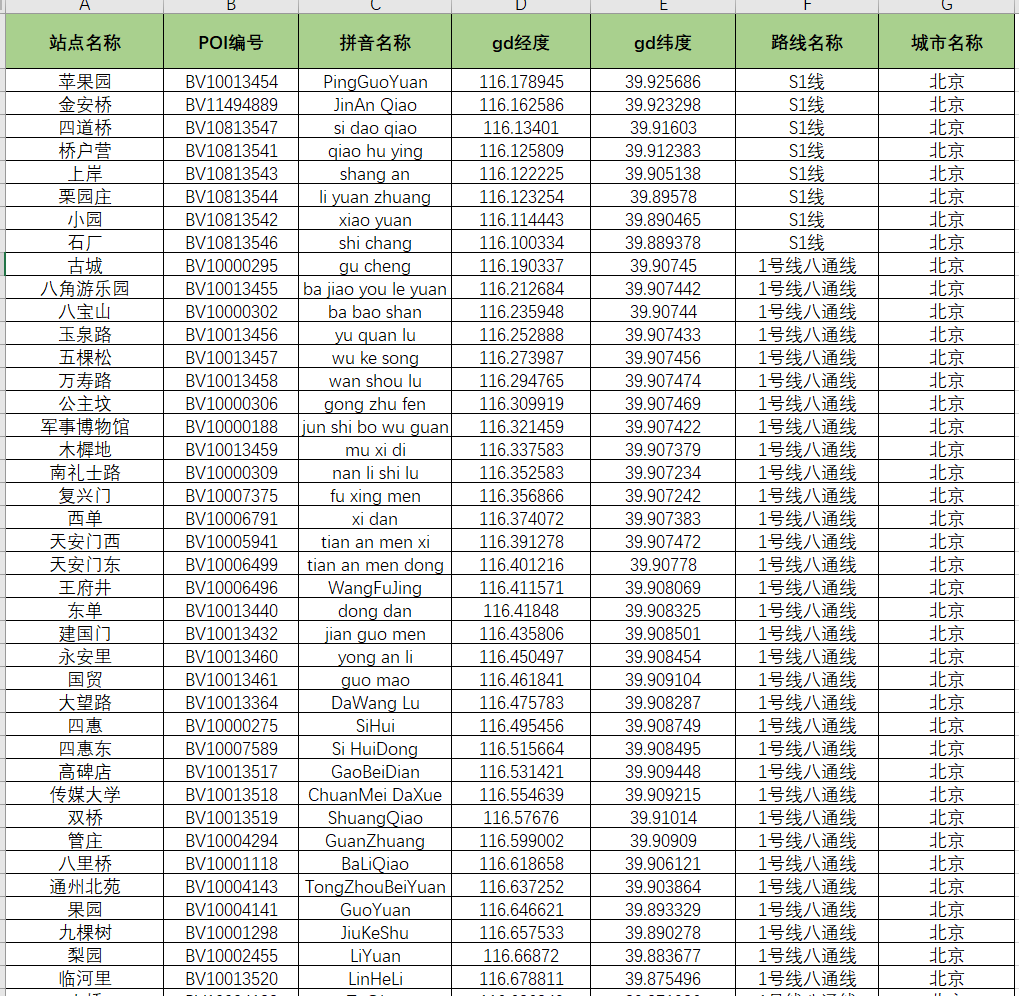
一共40个城市,5968条数据
2、爬虫思路
获取源码文件请直接在后台回复 地铁站点
今天的源码其实之前有写过,但是因为过去时间比较久了,没有和官方的更新同步,所以在运行过程中会出现bug
这次我也是将存在的bug修复了,并优化了部分逻辑,比以前的代码运行速度会更快。
今天的数据来自于高德,下面是高德地图对于全国地铁站点的一个可视化界面,做的相当不错。
页面长这样:

对了,如果有不擅长写代码的读者,但是又想拿到数据做分析和挖掘,可以在后台回复地铁数据集我会发给你。
首先,浏览器打开 F12,定位到上方的城市列表
对应的城市列表是直接显示在 div 标签里面的,不过城市是被分成了两部分,一部分在 city-list 里面,一部分在 more-city-list 里面。
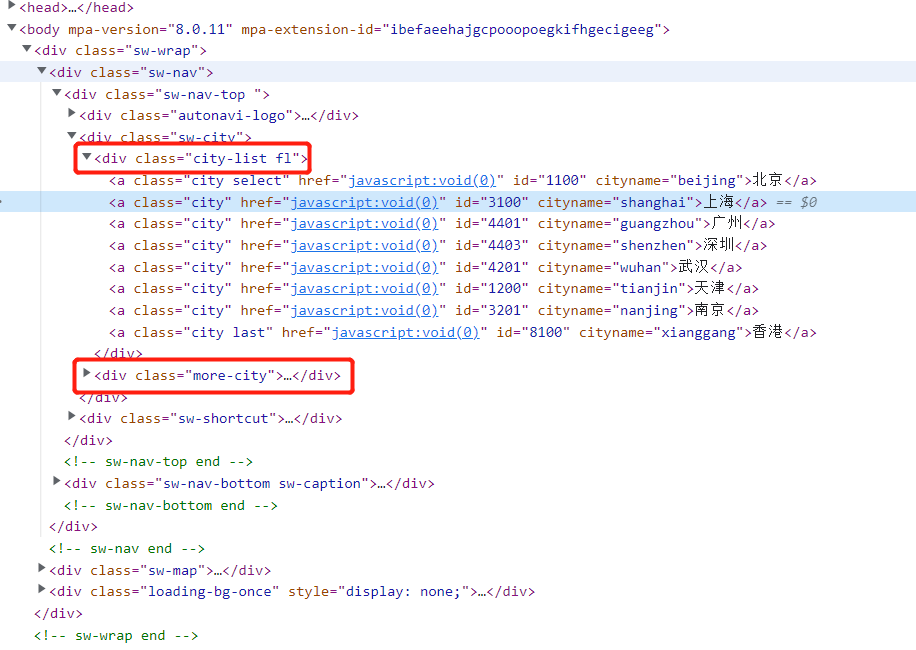
而且在每一个城市的 a 标签里面有对应的城市 ID 和城市拼音。
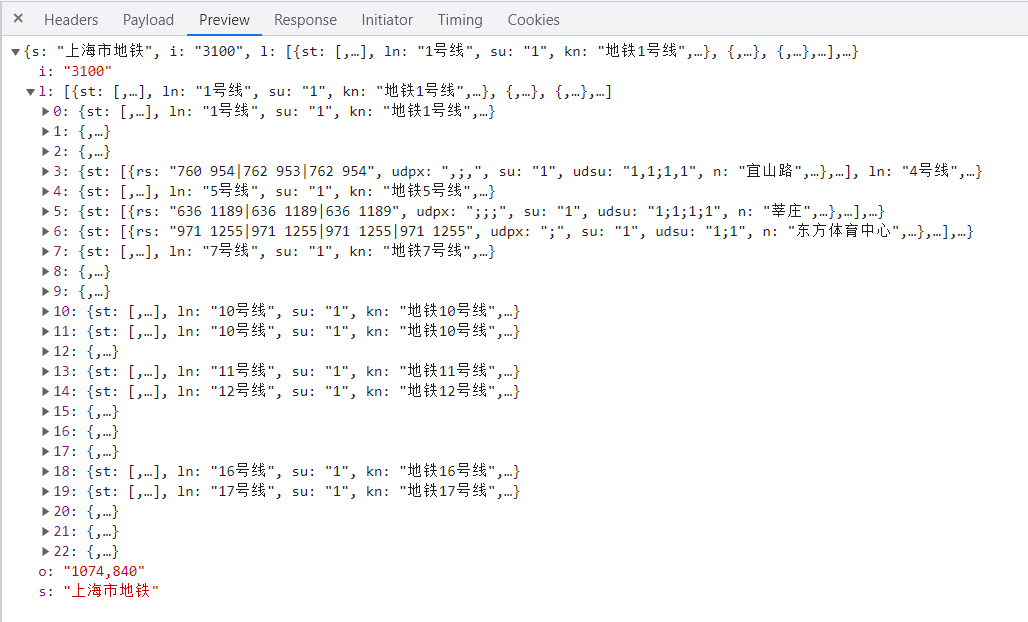
随便点击一个城市,在可视化界面发生变化的同时看到 Network 中出现了一个链接。
链接名称中包含了这个城市的 ID 和拼音,对应的数据就是我们要的地铁站点数据。
总结一下流程,思路如下:
爬取两个 div 中的城市数据(包括 ID 和拼音),生成城市集合
遍历城市集合,构造每一个城市的 url
访问 url,爬取对应城市的地铁站点数据
代码复现起来也比较简单,但是由于篇幅问题,这里就只展示核心的代码部分
首先是获取城市列表中的第一部分:
# 获取显示出的城市列表
for soup_a in soup.find('div', class_='city-list fl').find_all('a'):
city_name_py = soup_a['cityname']
city_id = soup_a['id']
city_name_ch = soup_a.get_text()
name_dict.append({'name_py': city_name_py, 'id': city_id, 'name_ch': city_name_ch})参考上面的写法获取未显示出来的城市列表,合并在一起就是所有的城市列表
最后就是获取每个城市的地铁线路,核心代码如下:
# 遍历每一条地铁线路
for data_line in data['l']:
df_per_metro = pd.DataFrame(data_line['st'])
df_per_metro = df_per_metro[['n', 'sl', 'poiid', 'sp']]
df_per_metro['gd经度'] = df_per_metro['sl'].apply(lambda x: x.split(',')[0])
df_per_metro['gd纬度'] = df_per_metro['sl'].apply(lambda x: x.split(',')[1])
df_per_metro.rename(columns={'n': '站点名称', 'sp': '拼音名称', 'poiid': 'POI编号'}, inplace=True)以上是核心源码,这里省去了非核心部分,需要请查看源码文件。
— 完 —
对比Excel系列新书《对比Excel,轻松学习Python统计分析》已经上线全网销售,原价89、全彩印刷,现价5折。点击下方链接即可购买。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









