







ForkJoinPool 是 Java SE 7 新功能“分叉/结合框架”的核心类,现在可能乏人问津,但我觉得它迟早会成为主流。分叉/结合框架是一个比较特殊的线程池框架,专用于需要将一个任务不断分解成子任务(分叉),再不断进行汇总得到最终结果(结合)的计算过程。比起传统的线程池类ThreadPoolExecutor,ForkJoinPool 实现了工作窃取算法,使得空闲线程能够主动分担从别的线程分解出来的子任务,从而让所有的线程都尽可能处于饱满的工作状态,提高执行效率。
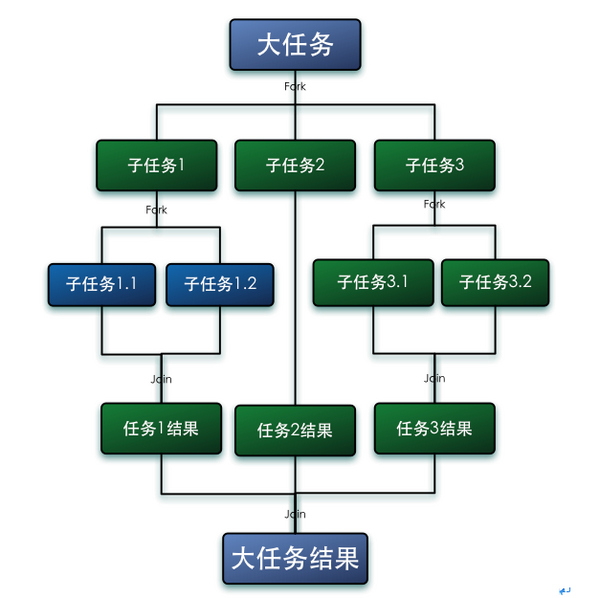
ForkJoinPool 提供了三类方法来调度子任务:
execute 系列异步执行指定的任务。
invoke 和
invokeAll执行指定的任务,等待完成,返回结果。
submit 系列异步执行指定的任务并立即返回一个
Future 对象。子任务由
ForkJoinTask 的实例来代表。它是一个抽象类,JDK 为我们提供了两个实现:
RecursiveTask 和
RecursiveAction,分别用于需要和不需要返回计算结果的子任务。
ForkJoinTask 提供了三个静态的
invokeAll 方法来调度子任务,注意只能在
ForkJoinPool 执行计算的过程中调用它们。
ForkJoinPool 和
ForkJoinTask 还提供了很多让人眼花缭乱的公共方法,其实它们大多数都是其内部实现去调用的,对于应用开发人员来说意义不大。
下面以统计 D 盘文件个数为例。这实际上是对一个文件树的遍历,我们需要递归地统计每个目录下的文件数量,最后汇总,非常适合用分叉/结合框架来处理:
// 处理单个目录的任务
public class CountingTask extends RecursiveTask<Integer> {
private Path dir;
public CountingTask(Path dir) {
this.dir = dir;
}
@Override
protected Integer compute() {
int count = 0;
List<CountingTask> subTasks = new ArrayList<>();
// 读取目录 dir 的子路径。
try (DirectoryStream<Path> ds = Files.newDirectoryStream(dir)) {
for (Path subPath : ds) {
if (Files.isDirectory(subPath, LinkOption.NOFOLLOW_LINKS)) {
// 对每个子目录都新建一个子任务。
subTasks.add(new CountingTask(subPath));
} else {
// 遇到文件,则计数器增加 1。
count++;
}
}
if (!subTasks.isEmpty()) {
// 在当前的 ForkJoinPool 上调度所有的子任务。
for (CountingTask subTask : invokeAll(subTasks)) {
count += subTask.join();
}
}
} catch (IOException ex) {
return 0;
}
return count;
}
}
// 用一个 ForkJoinPool 实例调度“总任务”,然后敬请期待结果……
Integer count = new ForkJoinPool().invoke(new CountingTask(Paths.get(“D:/”)));
在我的笔记本上,经多次运行这段代码,耗费的时间稳定在 600 豪秒左右。普通线程池(Executors.newCachedThreadPool())耗时 1100 毫秒左右,足见工作窃取的优势。
结束本文前,我们来围观一个最神奇的结果:单线程算法(使用 Files.walkFileTree(…))比这两个都快,平均耗时 550 毫秒!这警告我们并非引入多线程就能优化性能,并须要先经过多次测试才能下结论。















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









