







29.Transformer Network for Significant Stenosis Detection in CCTA of Coronary Arteries
Motivation:
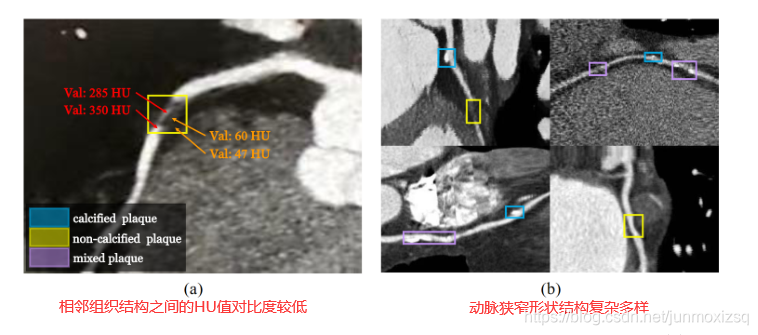
引起冠心病的冠状动脉斑块的复杂性使得冠状动脉造影(CCTA)中冠状动脉狭窄的自动检测成为一项困难的任务.已有的RNN方法虽然能够在一定程度上捕捉单个方向上语义特征之间的依赖关系,但很少考虑冠状动脉分支的全局干预来检测冠状动脉狭窄。为了确保模型能够在检测到局部冠状动脉狭窄之前学习整个冠状动脉分支的语义特征,我们将Transformer引入,提出的TR-Net结合了3D-CNN和Transformer。前者在提取局部语义信息方面具有相对较大的优势,而后者可以更自然地关联全局语义信息。我们采用了一种浅层3D-CNN来提取冠状动脉的局部语义特征,获取图像中每个位置的语义信息。然后,使用Transformer编码器来分析特征序列,这可以挖掘局部狭窄对冠状动脉每个位置的潜在依赖性。
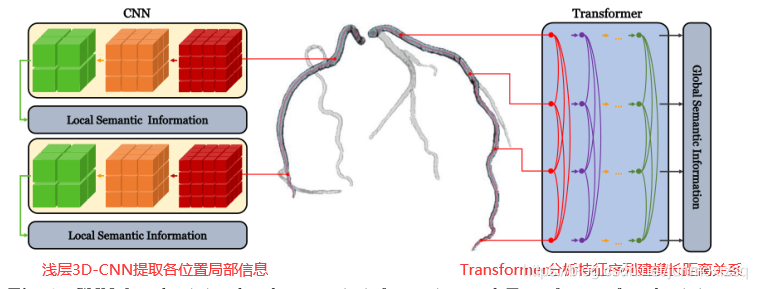
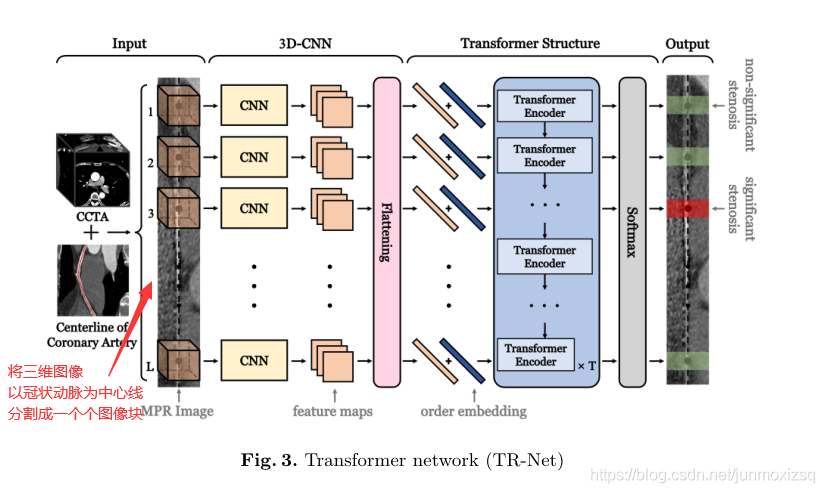
TR-Net OverView:
又因为不同部位斑块之间的潜在关系对临床诊断具有重要价值。在这项工作中,对于中心线上的图像块,在两个方向的斑块上都有可能影响检测结果的图像信息,为了将每个立方块的顺序信息引入到我们的模型中,我们在将order embeddings输入到Transformer结构之前:
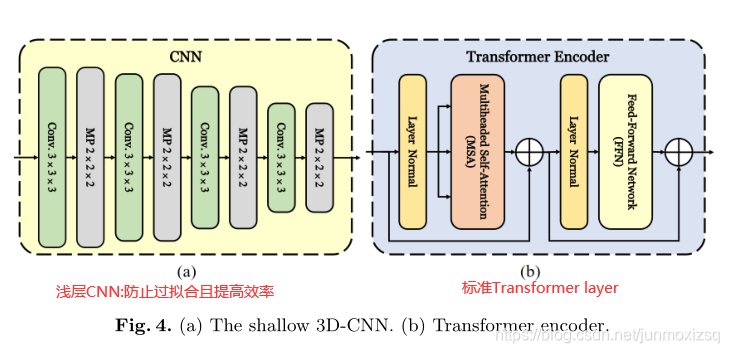
![]()

30.Transformer in Transformer
Motivation:
Transformer是一种最初用于NLP任务的基于自注意力的神经网络。最近提出的基于Transformer的模型来解决视觉问题。这些视觉Transformer通常将图像视为一系列patches,而忽略每个patch内部的固有结构信息。基于此,本文提出了一种新颖的Transformer-iN-Transformer(TNT)模型,用于对 patch级和像素级表示双尺度进行建模。
TNT OverView:


应用了计算机视觉领域比较经典的金字塔式结构.实验表明(TNT+DETR),在计算和存储成本增加很少的情况下,我们的TNT块可以有效地对局部结构信息进行建模进而对全局进行更好的估计,在准确性和复杂性之间取得更好的平衡。

31.You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Motivation:
本文对在中型 ImageNet-1k 数据集上预训练的传统ViT 在更具挑战性的 COCO 目标检测基准中的可迁移性进行了研究。具体来说,提出 You Only Look at One Sequence (YOLOS),是一系列基于纯 Vision Transformer 的目标检测模型,其修改和归纳偏差都是最小的。而仅在中等规模的 ImageNet-1k 数据集上预训练的 YOLOS 也已可以在COCO 上实现有竞争力的目标检测性能.重点揭示了Transformer的迁移学习能力与泛化性能.
YOLOS OverView:
参照原始ViT架构,并参考DETR针对目标检测进行适当调整。YOLOS可以轻易的适配不同的Transformer结构,这种简单的设置初衷不是为了更好的检测性能,而是为了尽可能无偏的揭示Transformer在目标检测方面的特性。
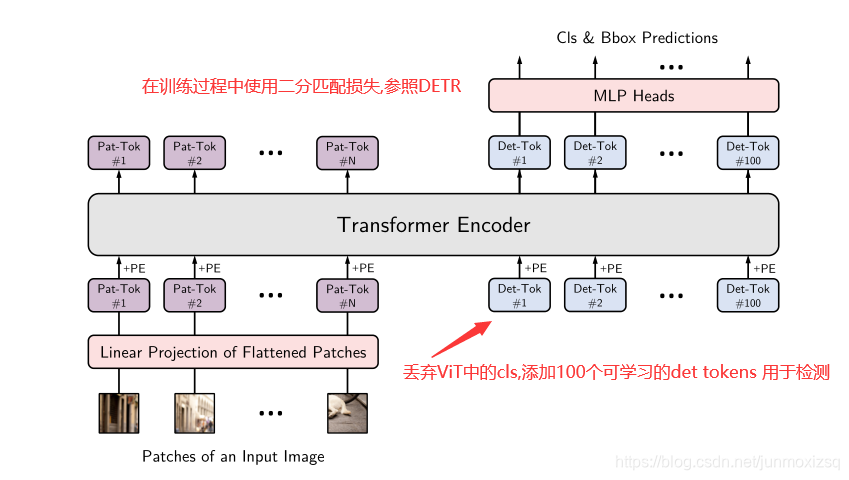
我们选择的随机初始的det作为目标表达的代理以避免2D结构与标签赋值时注入的先验知识存在的归纳偏置。当在COCO上进行微调时,每次前向传播时,在det与真实目标值之间构建一个最优二分匹配。该步骤起着与标签赋值相同的作用,但它与2D结构无关,也即说:YOLOS不需要将ViT的输出重解释为2D结构以进行标签赋值。
实验结果表明YOLOS对于预训练机制更为敏感,且性能仍未达到饱和,且与DETR对比,具有更大参数量,但结果仍然稍弱.但是YOLOS的出发点并不是为了更佳的性能,而是为了精确的揭示ViT在目标检测方面的迁移能力。YOLOS的这种最小调改精确地揭示了Transformer的灵活性与泛化性能。
32.Toward Transformer-Based Object Detection
Motivation:
在ViT提出之后,引发了一个问题,即基于transformer的体系结构(例如Vision Transformer)是否能够执行除分类以外的任务,尤其是目标检测这类高分辨率的复杂视觉任务.本文将Vision Transformer用作骨干(VT+检测头),以产生具有竞争力的COCO结果。我们提出的模型ViT-FRCNN展示了与transformer相关的几种已知特性,包括大的预训练能力和快速的微调性能。并且对大型对象的检测性能有所提高(可能是因为该架构能够全局处理),并且对对象的虚假过度检测更少。
ViT-FRCNN OverView:
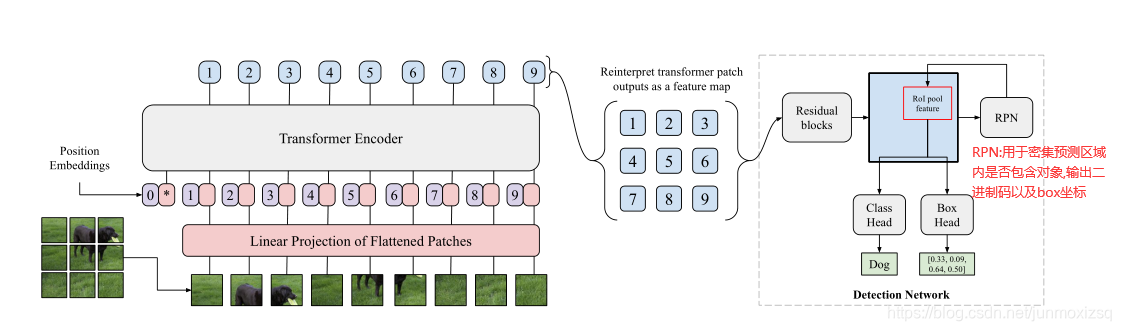
实验结果:
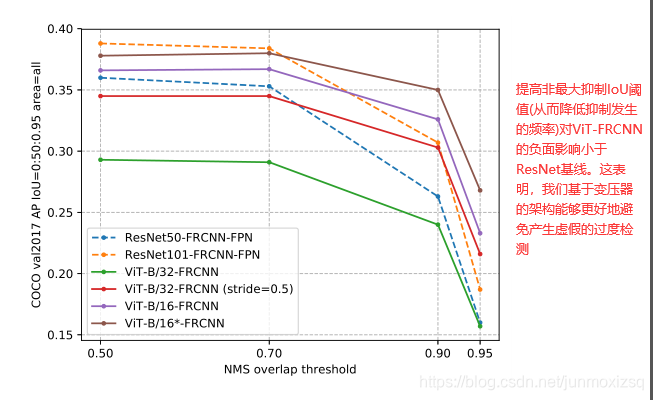
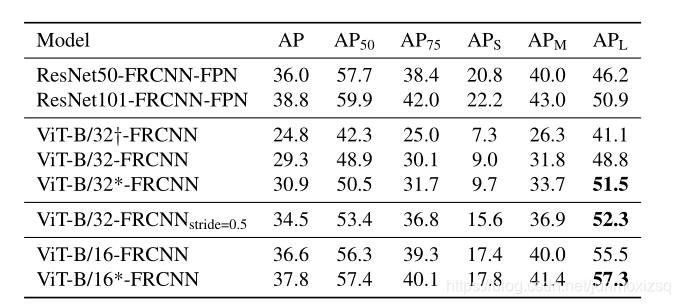
33.End-to-End Human Object Interaction Detection with HOI Transformer
Motivation:
本文提出使用HOI Transformer以端到端的方式处理人-物交互(HOI)检测。当前的方法要么将HOI任务解耦到对象检测和交互分类的分离阶段,要么引入替代交互问题。相比之下,我们的方法名为HOI变压器,通过消除对许多手工设计组件的需求,简化了HOI管道。HOI-T从全局图像背景中推理出物体和人的关系,并直接并行预测HOI实例。
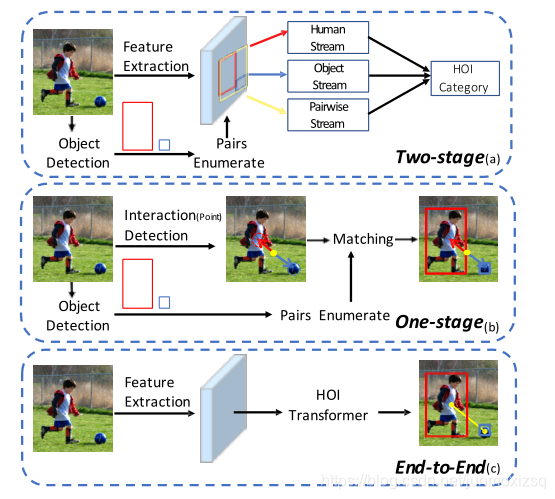
Two-stage:通常由第一阶段的目标检测器和第二阶段的交互分类器组成。更具体地说,在第一阶段,使用微调的对象检测器来获得人和对象的边界框和类标签。在第二阶段,使用多流体系结构来预测每个人-对象对的交互。顺序和分离的两级架构,这些方法具有严重的复杂性和低效率。
One-stage:也就是一种替代交互检测方法,来直接优化HOI,首先交互的proposal是通过人的先验知识来预定义。在人和物之间找到一个center-point作为interaction-point。接着,人,物以及交互的proposals都会并行的被检测。然而,一阶段方法仍然需要复杂的后处理来对目标检测结果和交互预测进行分组。
HOI-T OverView:
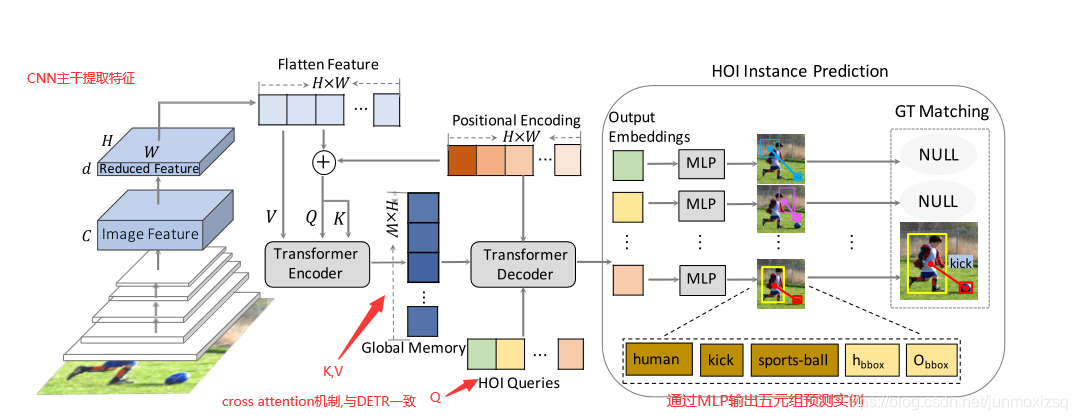
此方法由两个主要部分组成,一个端到端的Transformer编码器-解码器结构和一个五元组HOI实例匹配损失函数:
编-解码结构如上图.
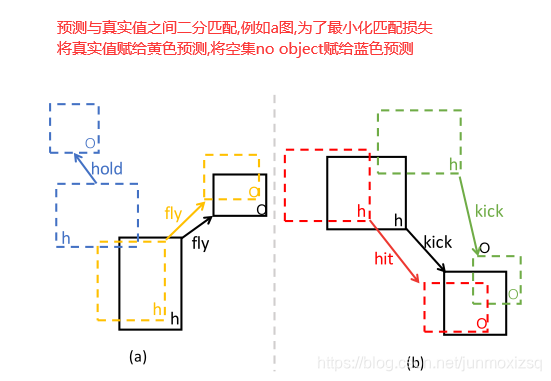
HOI实例匹配策略:
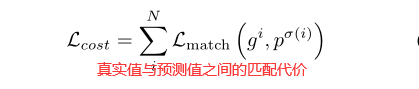
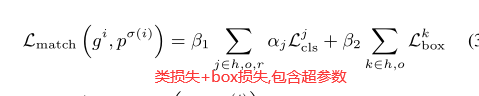

34.Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Motivation:
本文提出了一种新的vision transformer结构,它在两个方面显著地增强了ViT。首先是多尺度模型结构,它以可接受的计算成本提供多尺度的图像编码。第二个是Vision Longformer的注意机制,以实现了线性复杂度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









