




Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
现有的技术背景及其局限:
- 深度卷积体系结构缺乏对图像中的远程依赖关系的把握。
- 用于医学成像的数据样本数量相对较少,使得有效训练用于医学得transformer变得困难。
探索解决方案:
- 基于 Transformer 的体系结构利用自我注意机制,编码长期依赖关系,并具有极富表现力的表示法.
- 我们提出了一种门控轴向注意模型,通过在自我注意模块中引入额外的控制机制来扩展现有的体系结构.
- 此外,为了对模型进行有效的医学图像训练,我们提出了一种局部-全局训练策略(LOGO),进一步提高了模型的性能。
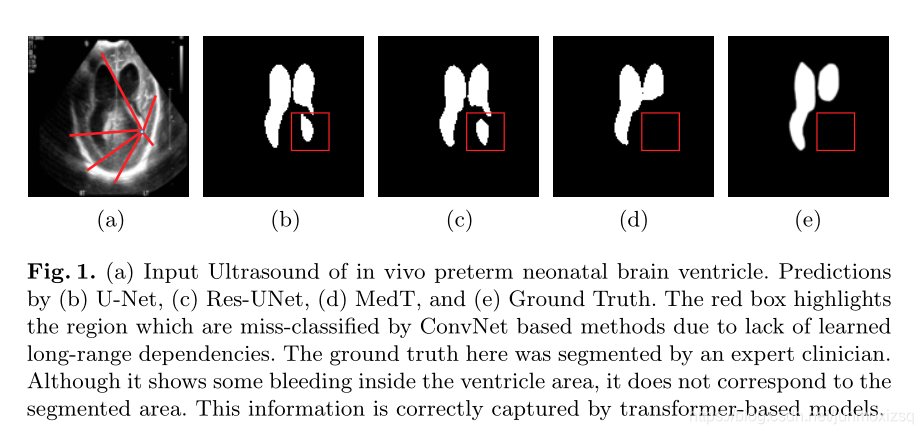
Medical Transformer
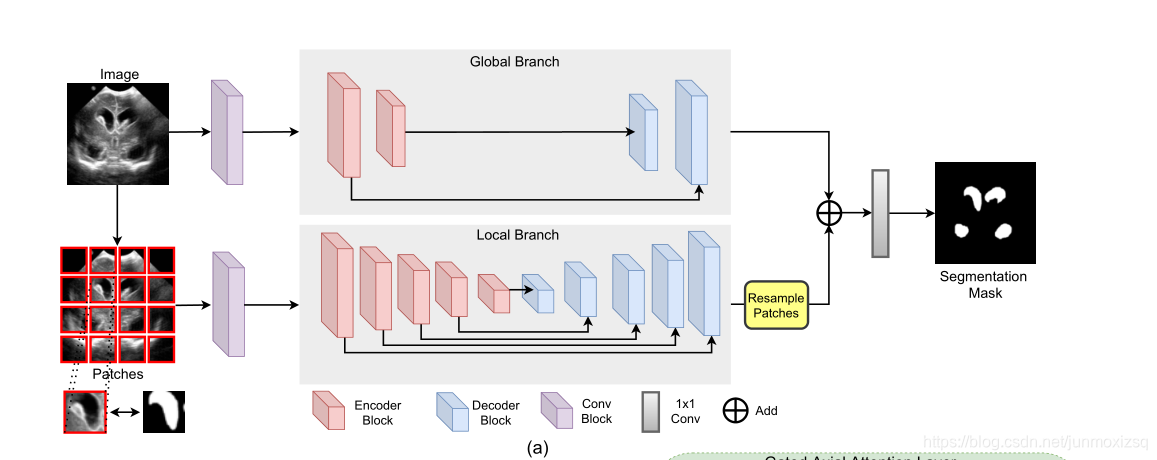
MedT 有两个分支机构:一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









