







文章目录
0x0. 前言(太长不看版)
paper链接:https://arxiv.org/pdf/2405.04437v1
之前浏览 vllm 的时候看到一篇尝试去掉 vLLM 的 PagedAttention,利用 CUDA 底层的虚拟内存和物理内存分配 API 直接分配连续的虚拟内存以及做物理内存映射从而避免 PagedAttention 由于要手动维护 Block Table 和物理内存分配带来的一系列工程麻烦以及高 Overhead 。另外对于新的 Attention 架构,想用上 Paged Attention,不得不从GPU Kernel的角度去适配Paged Attention,非常困难,而使用vAttention实现则无需对底层的GPU Kernel进行任何改动。从 Paper 的结果来看,从 PagedAttention 切换到 Paper 提出的 vAttention 时,无论是在首 Token 延迟,decode吞吐,Overhead 都明显优于 vLLM 框架。最重要的是,它对新 Attention架构的适配会比 vLLM 更加简单,因为不用 Paged kernel。
在 vllm github 仓库 issue 中有人询问什么时候支持 vAttention ,paper 的作者回答会在最近开源 vAttention,同时会提 PR 将其作为 vLLM 管理逻辑内存和物理内存的另外一种选择,期待后续进展。
注:下面是Paper的详细阅读,然后在每一节也穿插了一些自己的总结,博客里的 page 和 页 都是同一个意思,感兴趣的读者可以继续阅读本文。此外,省掉了Paper里面一些没有干货的章节,主要是还是围绕了vAttention的架构进行阅读,图表比较多,所以看起来有点长。
0x1. 摘要
高效利用GPU内存对于高吞吐量的LLM推理至关重要。以前的系统提前为 KV Cache 保留内存,导致由于内部碎片而浪费容量。受操作系统基于虚拟内存系统的启发,vLLM 提出了 PagedAttention,以实现 KV Cache 的动态内存分配。这种方法消除了碎片问题,使得能够在更大批量的情况下高吞吐量地服务 LLM。然而,为了能够动态分配物理内存,PagedAttention 将 KV Cache 的布局从连续的虚拟内存更改为非连续的虚拟内存 。这一变化要求重写注意力 kernel 以支持分页,并且服务框架需要实现一个内存管理器。因此,PagedAttention 模型导致了软件复杂性、可移植性问题、冗余和低效率。
在本文中,提出了 vAttention 用于动态 KV Cache 内存管理。与 PagedAttention 不同,vAttention 在连续虚拟内存中保留 KV Cache,并利用已有系统支持的 low-level 按需分页来实现按需物理内存分配。因此,vAttention解除了注意力 kernel 开发人员必须显式支持分页的负担,并避免了在服务框架中重新实现内存管理。paper证明了 vAttention 能够无缝动态地管理各种未修改的注意力 kernels 的内存。vAttention 生成 tokens的速度比 vLLM 快达 1.97 倍,而处理输入 prompts 的速度比 PagedAttention 版本的 FlashAttention 和FlashInfer 分别快达3.92倍和1.45倍。
0x2. 介绍&背景
paper介绍和背景酱的东西都是一回事,这里就直接用一节进行描述。
大型语言模型(LLM)被部署在广泛的应用中,例如聊天机器人、搜索引擎和编码助手。因此,优化LLM推理变得非常重要。提高LLM服务吞吐量的关键技术之一是批处理。在LLM推理的两个阶段——prefill 和 decode 中,decode 阶段是内存受限的,因为它每次请求处理一个单独的 token 。批处理通过均摊从 GPU 内存中获取模型权重的成本并提高内存带宽利用率,从而提高了吞吐量。
高效的推理还需要谨慎分配GPU内存。对于每个请求,LLM维护一个称为 KV Cache 的内存状态,并在请求的整个生命周期内每次迭代都重新使用它。在推理过程中实现高内存容量利用率具有挑战性,原因有两个:1)每个请求的KV Cache增长缓慢,即每次迭代一个token(几十毫秒),2)生成的token数量以及请求的KV Cache总大小通常事先未知。
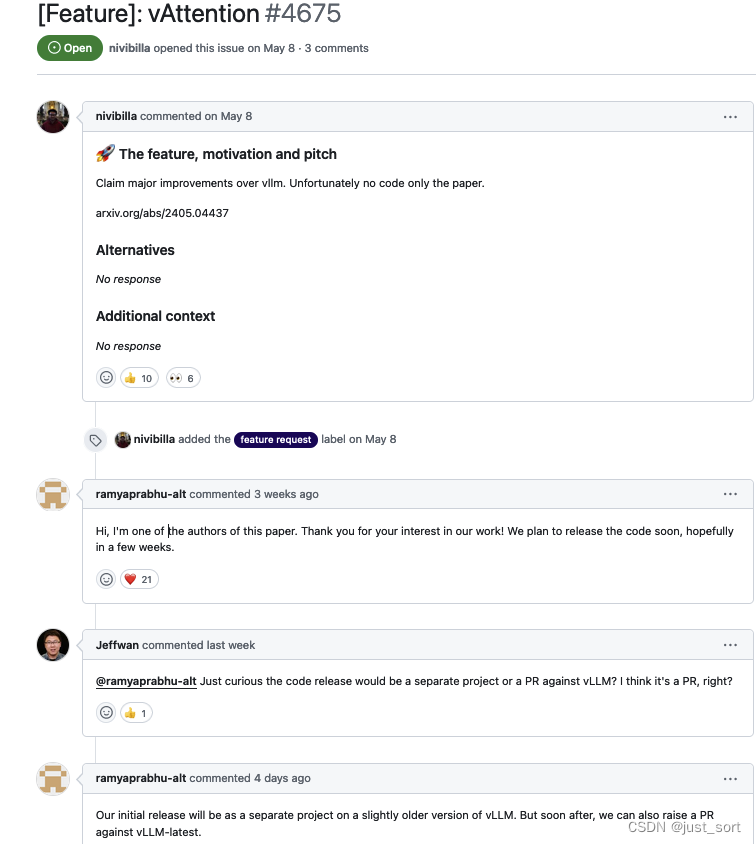
以前的系统如 Orca 和 FasterTransformer 为 KV Cache 分配了一块连续的虚拟内存(由预先分配的物理内存支持)。分配的大小对应于模型支持的最大序列长度,例如32K。由于模型生成的 token 通常远少于最大限制,因此由于内部碎片而浪费了大量GPU内存。因此,这些系统表现出较差的吞吐量,因为它们无法支持较大的批处理大小。
受操作系统基于虚拟内存系统的需求分页启发,vLLM引入了PagedAttention,以减轻与KV Cache相关的内存碎片问题。vLLM并不预先保留KV Cache内存的最大序列长度,而是在需要时按需分配小块的虚拟内存(由物理内存支持),即当先前分配的块已完全使用且模型继续生成更多token时进行分配。然而,动态分配的块在虚拟内存中不一定是连续的(系统可能已将这些块分配给其它请求)。因此,PagedAttention接受KV Cache分配是非连续的,并实现了一个块表以将这些非连续的分配拼接在一起。
如今,PagedAttention已经成为LLM服务系统中动态内存分配的事实标准,例如在TensorRT-LLM、HuggingFace TGI、FlashInfer、LightLLM等系统中。PagedAttention方法最显著的方面是将KV Cache存储在非连续的虚拟内存中,以便能够动态分配物理内存。尽管这种方法为KV Cache碎片问题提供了一个合适的解决方案,但paper认为它存在几个缺陷(参见Table 1中的实证证据和实际经验):
1. 需要重写注意力kernel(GPU代码)。已知可以使用基于索引的查找简单而高效地访问虚拟连续对象的元素。而PagedAttention的 KV Cache 存储在非连续的虚拟内存中,所以 PagedAttention 要求重写 GPU 代码,以便注意力 kernel 能够取消引用 KV Cache 的所有元素。重写代码的需求是将新 Attention 优化用于生产环境的主要障碍。
2. 增加了软件复杂性和冗余(CPU代码)。PagedAttention 还迫使开发者在服务框架内实现一个内存管理器,使其负责(取消)分配 KV Cache 和跟踪动态分配的 KV Cache 块的位置。这种方法实际上相当于在用户代码中重新实现了分页需求——这是操作系统的功能。
3. 引入性能开销。PagedAttention 可能会通过两种方式在执行的关键路径中增加运行时开销。首先,它要求 GPU kernel 执行与从非连续内存块中获取 KV Cache 相关的额外代码。paper 发现,这在许多情况下会使注意力计算速度减慢超过 10%。其次,用户空间内存管理器可能会增加 CPU 开销,导致额外的 10% 的成本。
在 paper 中,作者认为保持 KV Cache 的虚拟内存连续性对于减少 LLM 部署中的软件复杂性和冗余性至关重要。作者主张,不应在用户级别重新实现分页,而应重新利用操作系统中现有的虚拟内存抽象来进行动态 KV Cache 内存管理,从而简化部署并提高性能。
为此,paper提出了 vAttention —— 一个在不提前分配物理内存的情况下将 KV Cache 存储在连续虚拟内存中的系统。paper通过利用CUDA支持的 Low-Level 虚拟内存API实现了这一点,这些 API 提供了分配虚拟和物理内存的不同接口。vAttention 提供了一组简单的 API,通过这些 API,服务框架可以为 KV Cache 保留连续的虚拟空间,并按需分配物理内存。这种方法带来了多项好处,如表2所示。vAttention 还通过实现现有 GPU kernel 的无缝重用,消除了在服务系统中实现内存管理器的需求,从而提高了可移植性。
挑战和优化:vAttention 解决了在没有 PagedAttention 的情况下实现高效动态内存管理的两个关键挑战。首先,CUDA API 支持的最小物理内存分配粒度为 2MB。根据模型和工作负载的特性,这种大小可能导致显著的容量浪费。为了解决这个问题,paper 修改了开源的 CUDA 统一虚拟内存驱动程序,以支持 64KB 到 256KB的更细粒度的物理内存分配。其次,使用 CUDA API 进行内存分配会产生高延迟,因为每次分配都涉及到kernel的往返。为了将内存分配的延迟对终端用户的影响隐藏起来,引入了几种 LLM 特定的优化措施,例如将内存分配与计算重叠,提前执行一些操作和延迟内存回收。最后展示了这些优化使 vAttention 成为一个高效的KV Cache 内存管理器。
总体而言,作者在 Paper 中做出了以下贡献:
- 提出了 vAttention,一个在保持 KV Cache 虚拟内存连续性的同时实现物理内存动态分配的系统。
- 展示了 vAttention 能够无缝地为未修改的 FlashAttention 和 FlashInfer 的注意力 kernel 添加动态内存管理支持,同时具有高性能。
- 在 1-2个A100 GPU 上评估了 Yi-6B、Llama-3-8B 和 Yi-34B,并展示了使用 FlashAttention 原始 kernel 时,vAttention 的性能优于 vLLM 高达 1.97 倍,而相对于 PagedAttention 版本的 FlashInfer,首 token 生成时间(TTFT)减少了高达 1.45 倍。
在背景部分仍然是对大语言模型,KV Cache,vLLM这些概念反复进行描述,就不赘述了,最后看一下Figure1吧。
0x3. 使用PagedAttention模型的问题
尽管受到需求分页的启发,PagedAttention采用了一种不同于传统需求分页的方法:它要求修改应用程序代码以适应动态分配的物理内存,而传统的需求分页对应用程序是透明的。本节详细说明了这种方法带来的一些问题。
0x3.1 需要重写注意力kernel
PagedAttention需要重写注意力kernel。这是因为传统实现的注意力操作符假设两个输入张量K和V存储在连续的内存中。由于偏离了传统的内存布局,PagedAttention要求修改注意力算子的实现,以便在非连续的KV Cache块上计算注意力得分。编写正确且高效的GPU kernel对大多数程序员来说是具有挑战性的。
作为Transformer架构的基本构建块,注意力算子在系统和机器学习社区中见证了大量的性能优化创新,这一趋势可能会继续。在PagedAttention模型中,跟上新研究需要持续努力将新的优化移植到支持PagedAttention的实现中。因此,生产系统很容易落后于研究,从而可能失去性能和竞争优势。举例来说,图9b显示,vLLM的分页kernel在GQA情况下已经比FlashAttention对应的kernel慢多达2.85倍。
0x3.2 在服务框架中增加冗余
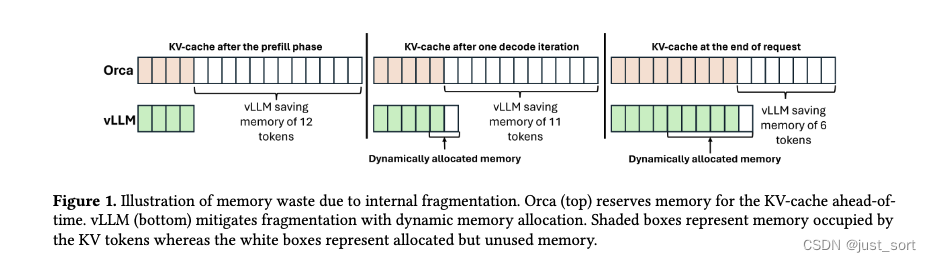
PagedAttention使LLM服务系统负责管理KV Cache与动态分配的内存块之间的映射。例如,考虑一个请求,它随着时间的推移分配了四个KV Cache块(图2左半部分)。这些块在虚拟内存中通常是非连续的。在计算注意力矩阵的过程中,PagedAttention Kernel需要访问这四个KV Cache块的所有元素。为了实现这一点,服务系统需要跟踪KV Cache块的虚拟内存地址并在运行时将它们传递给注意力kernel。这种方法实际上需要复制操作系统已经为实现虚拟到物理地址转换所做的工作(图2右半部分)。
0x3.3 性能开销
PagedAttention在GPU和CPU上都会导致潜在的性能问题。vAttention分别对此进行了研究。
0x3.3.1 GPU上的运行时开销
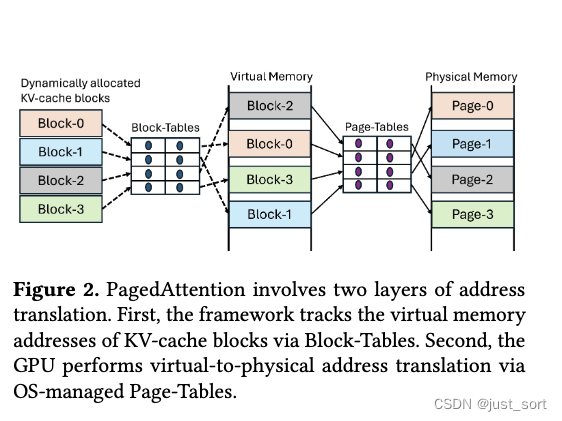
PagedAttention通过在关键路径中添加额外代码,减慢了注意力计算。例如,vLLM承认其基于PagedAttention的实现比原始的FasterTransformer kernel慢20-26%,主要是由于查找块表和执行额外分支的开销。图3显示了FlashAttention中的分页解码kernel也比普通kernel慢。进一步分析表明,PagedAttention中执行的指令数量比普通kernel高出13%。vAttention还发现,分页的开销在大批处理大小或长上下文长度时减少。这是因为对于解码来说,计算注意力是内存受限的,当KV Cache大小较大时,内存墙隐藏了指令开销。
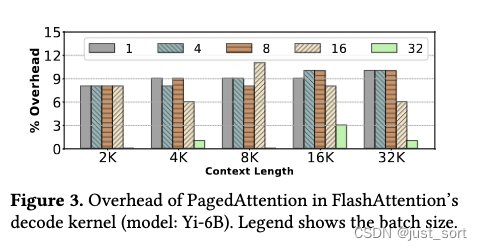
然而,在计算复杂度为 N 2 N^2 N2的 prefill 注意力kernel中,隐藏指令开销更具挑战性。例如,图4显示了FlashInfer的prefill kernel分页版本比普通kernel慢多达14%。分页kernel也缺少一些众所周知的优化。
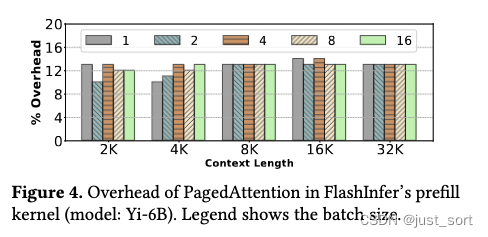
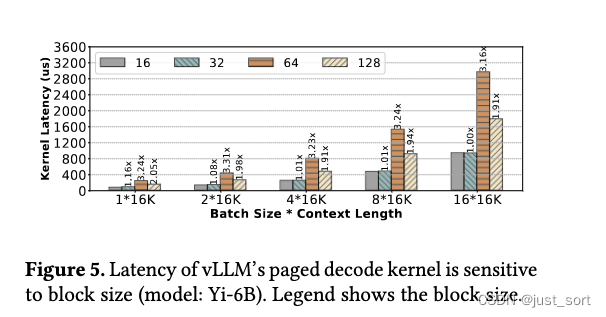
另一个例子显示编写高效注意力kernel的难度,图5表明vLLM的分页解码kernel在块大小为64和128时的性能显著较差。分析显示,这可能是由于L1缓存效率:较小的块由于L1缓存命中率较高而具有更高的内存带宽利用率。
0x3.3.2 CPU上的运行时开销
实现一个额外的内存管理器会在服务系统的CPU运行时中增加性能问题。作者引用了一些实际案例和对vLLM的观察来证明这一观点。
为了启用PagedAttention,服务系统需要向注意力kernel提供块表。在vLLM中,准备块表的延迟取决于批处理组成,并且随着max_num_blocks × batch_size成比例增长,其中max_num_blocks指的是批处理中最长请求的KV Cache块数量。这是因为vLLM将块表管理为一个2D张量,并通过用零填充未占用的槽来对齐每个请求中的KV Cache块数量。如果一个批处理中包含一些长请求和许多短请求,这种填充会导致显著的开销。在作者早期的实验中,作者观察到vLLM中块表准备在解码迭代中贡献了30%的延迟。虽然最近的修复减轻了部分开销,但作者发现它仍然可能高达10%。在TensorRT-LLM中也发现了PagedAttention的高开销,吞吐量下降了11%,从412 tokens/s降至365 tokens/s。这个问题归因于TensorRT-LLM的Python运行时,转移到C++运行时可以减轻CPU开销。
总体而言,本节显示了PagedAttention模型增加了显著的编程负担,同时也效率低下。vAttention通过利用现有的需求分页系统支持,引入了一种更系统的方法来动态管理KV Cache内存。然而,在深入讨论vAttention之前,vAttention首先强调LLM服务工作负载在内存管理方面的一些基本特征。
0x4. 对LLM服务系统的洞察
为了突出LLM服务系统的内存分配模式,vAttention对Yi-6B在单个NVIDIA A100 GPU上运行,Llama-3-8B和Yi-34B在两个A100 GPU上以张量并行方式运行进行了实验。vAttention将每个请求的初始上下文长度设置为1K tokens,批量大小从1到320变化,测量了decode阶段的延迟、吞吐量和内存需求(有关prefill阶段的讨论和优化,见第6节)。
观察1:每次迭代的KV Cache内存需求是事先已知的。这是因为自回归解码每次请求生成一个 token。因此,每次迭代中,请求的 KV Cache 内存占用都会均匀增长一个token,直到请求完成。
观察2:KV Cache不需要高内存分配带宽。单个 token 在所有层中的内存占用通常是几十到几百KB。例如,Yi-6B、Llama-3-8B 和 Yi-34B 的每个 token 内存占用分别为 64KB、128KB 和 240KB。此外,每次迭代运行10到100毫秒(图6b),这意味着每个请求每秒最多需要几MB的内存。尽管批处理提高了系统吞吐量,但每秒生成的 token 数量在某个批量大小之后趋于平稳(图6a)。这意味着内存分配带宽需求在大批量大小时也趋于饱和(例如,对于Yi-34B,在128时)。对于vAttention研究的所有模型,观察到最高内存分配速率最多为600MB每秒(图6c)。
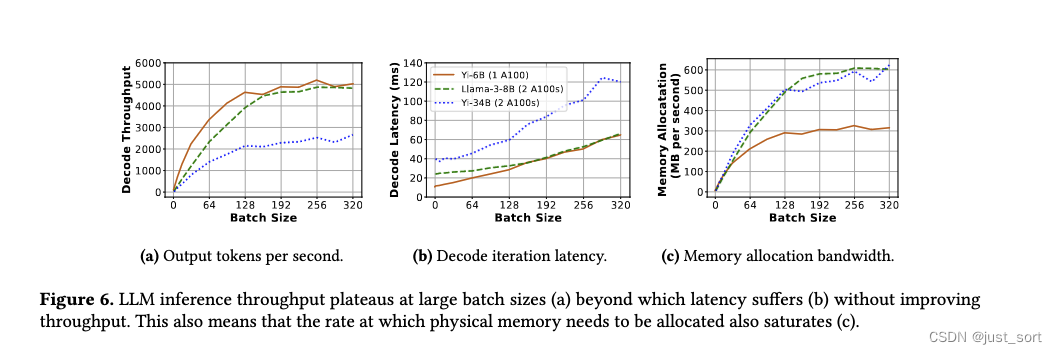
在vAttention中,利用上面这些观察来实现一个高效的KV Cache动态内存管理系统。在下一节中,作者首先提供vAttention的高层设计描述(§5.1),然后讨论vAttention如何用于 Serving LLM(§5.3),最后描述的优化方法(§6)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









