







一、 背景
网上有很多是说 auto-commit 和 concurrency 的关系
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.listener.concurrency=3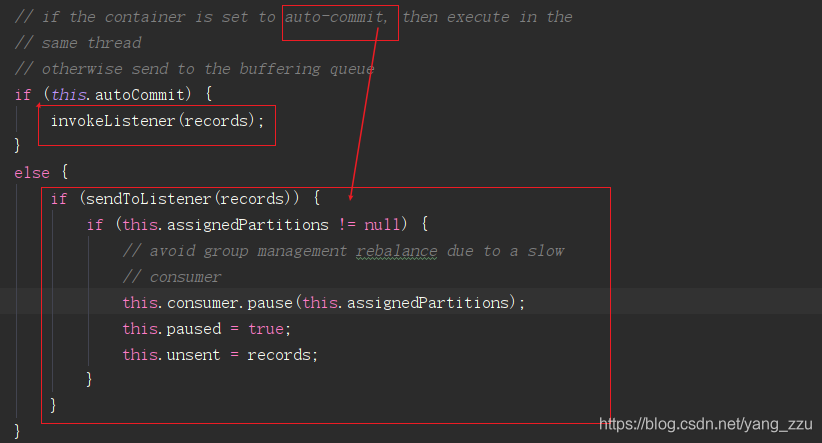
所以,当concurrency=3,自动提交设置为false时,如果程序里有2个方法标记了@KafkaListener,那么此时会启动 2 * 3 = 6 个Consumer线程,6个Listener线程。
二、验证
2.1 实验环境:
两个topic: teacherTopic、studentTopic, 每个topic 的 partition 的数量为 3

2.2 消费者线程数量为1
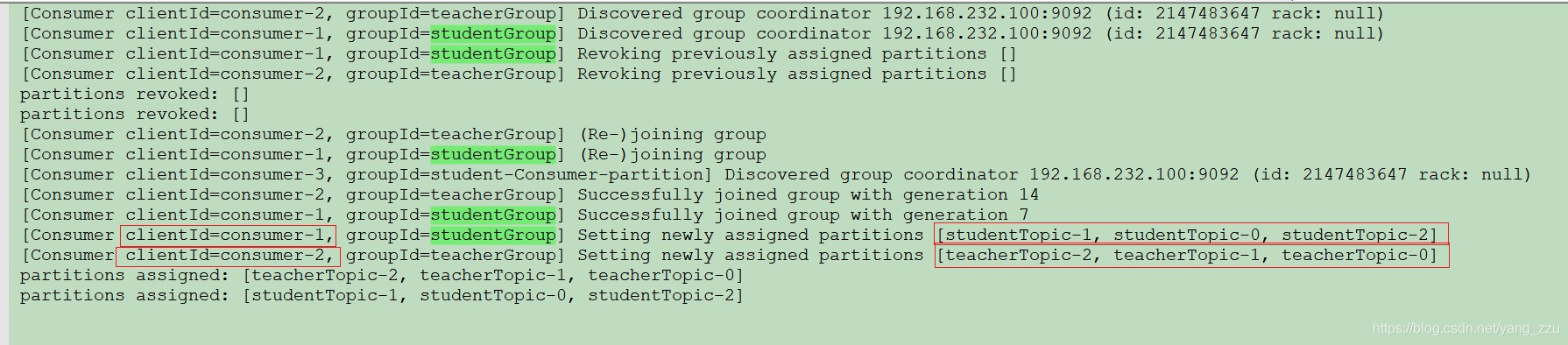
可以看到,studentGroup 和 teacherGroup 的消费者数量是1,项目中总共是2个消费线程
一个消费者 消费了 该topic 的所有分区
2.3 消费者线程为 2


消费的线程为2 的时候,studentGroup 和 teacherGroup 的消费者数量是2,项目中总共是4个消费线程, 有的消费者消费两个partition 有的消费者消费了一个partition
2.4 消费者线程为3

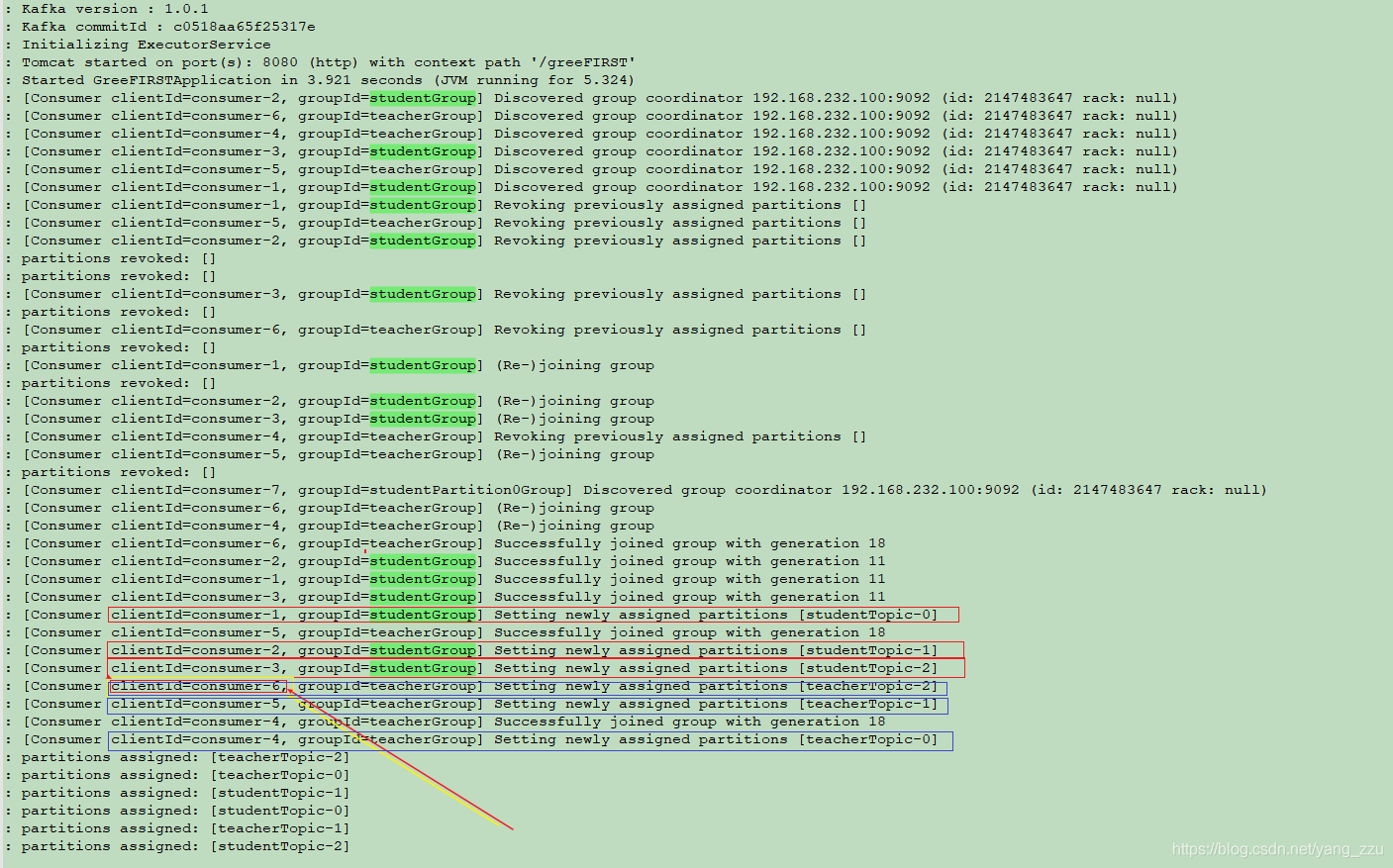
当线程为3 时,studentGroup 和 teacherGroup 的消费者数量是3,项目中总共是6个消费线程,一个消费者消费一个 partition。
2.4 消费者线程为4

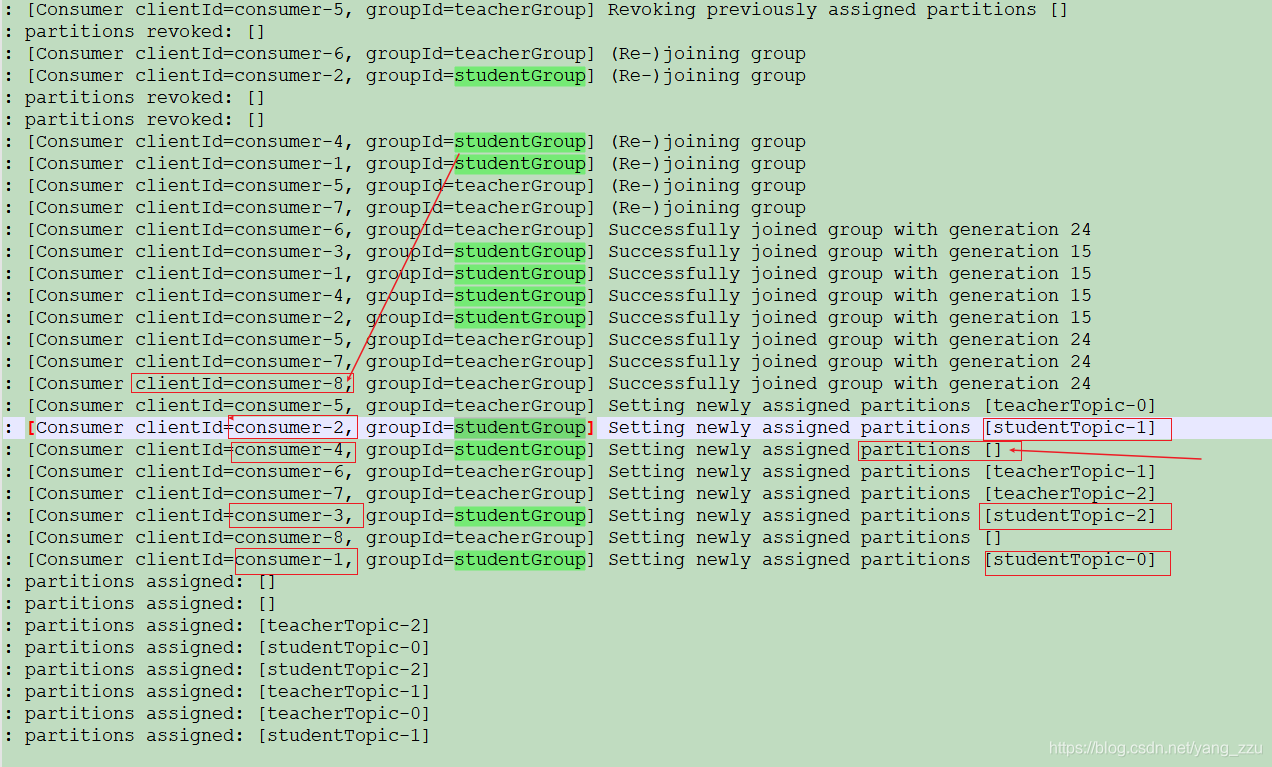
消费线程为4 时,studentGroup 和 teacherGroup 的消费者数量是4,项目中总共是8个消费线程,但是有一个消费者消费的partition 为空,即,该消费者不会消费任何数据。
所以,当concurrency=3,自动提交设置为false时,如果程序里有两个方法标记了@KafkaListener,那么此时会启动 2 * 3 = 6 个Consumer线程,6个Listener线程。-------这种说法不是很准确
总结:
项目中总的消费者线程数量为:
concurrency * @KafkaListener的数量(默认监听全部的partition)当 (concurrency * @KafkaListener) < partition 的数量,会出现消费不均的情况,一个消费者的线程可能消费多个partition 的数据
当 (concurrency * @KafkaListener) = partition 的数量,最佳状态,一个消费者的线程消费一个 partition 的数据
当 (concurrency * @KafkaListener) > partition 的数量,会出现有的消费者的线程没有可消费的partition, 造成资源的浪费

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









