







本文,就像本系列的其他文章一样。旨在通过阅读原论文+手写代码的方式,自己先把算法搞明白,然后再教其他人。手写代码除了可以验证自己是否搞明白以外,我会对中间过程做图。这样,我可以通过图直观的验证算法是否正确。而这些图,又成为写文章时候的很好的素材。
什么是 DBSCAN
DBSCAN,全称是 Density-Based Scan。 故名思意,就是通过密度扫描。DBSCAN是一种聚类算法,和KMeans相比,他不需要指定cluster的数量。他的主要参数有两个,半径和邻居的数量。Scikit-Learn中,半径用 ϵ \epsilon ϵ(epsilon)表示,邻居的数量用min-samples表示。我们这里也借用sklearn的表示方式。这样大家使用sklearn的时候不会搞混。
当然,除了sklearn,在weka,R,elki等库里,也有DBSCAN的实现。他在教科书里也经常被提及,并有很多成功的实际运用。许多基于密度的聚类算法,也都受了DBSCAN的启发。实践证明改算法是有效的,并在2014年获得了SIGKDD的test-of-time大奖。
和KMeans比较
为什么有了KMeans,还要有DBSCAN,肯定是KMeans有解决不了的问题。
比如,我们画两个月亮。
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import Circle
from sklearn.cluster import DBSCAN, KMeans
from sklearn.datasets import make_moons
from sklearn.metrics.pairwise import euclidean_distances
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)
plt.figure(figsize=(12, 6))
plt.scatter(X[:,0], X[:,1])
plt.show()
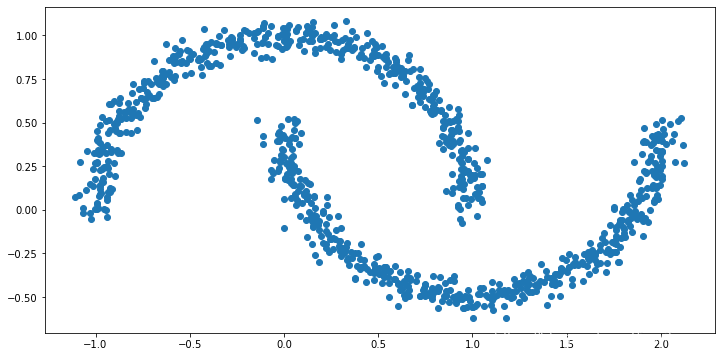
然后,我们用KMeans聚类:
km = KMeans(n_clusters=2)
km.fit(X)
plt.figure(figsize=(12, 6))
# Plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=km.labels_)
plt.title(f"Kmeans (k=2)")
plt.show()
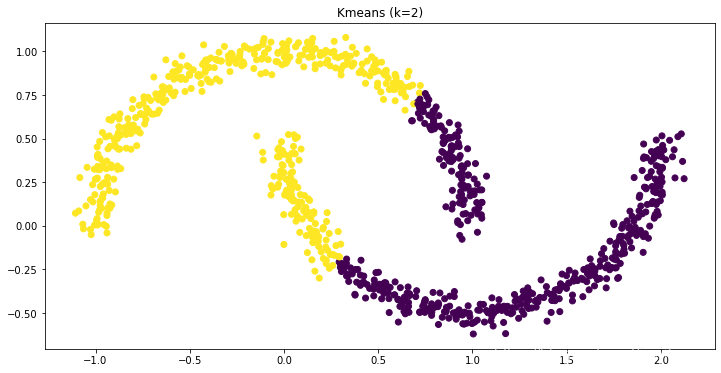
这里,我们可以看到,我们本来希望两个月亮能分别对应两个簇(cluster),但是事与愿违。这是因为,KMeans是按照距离来聚类的。一个月亮的边缘,距离其中心的距离,可能大于其距离另一个月亮中心的距离。这样,这些点就被另一个月亮带跑了。
DBSCAN 算法
第一步:找核心(core)点
这时,DBSCAN就出现了。他不是基于距离的,而是基于密度的。他把高密度的区域都连起来,形成一个簇。
这里,我们就需要半径( ϵ \epsilon ϵ)和最小邻居数量(min-samples)来确定高密度区了。
首先,我们要找到一些中心点。他们的半径( ϵ \epsilon ϵ)之内,有min-samples个点。我们这里把epsilon和min-samples设置为0.1和10。
这时找到的这些中心点,叫做core。
# set the parameters
epsilon = 0.1
min_samples = 10
# In most of the cluster algorithms, the first step is to calculate the distance matrix.
distance_matrix=euclidean_distances(X)
neighbour_predicate_matrix = distance_matrix<=epsilon
neighbour_counts_array=neighbour_predicate_matrix 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2628
2628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











